
可以举一个决策树中过拟合现象的案例吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
首先通过人工的方式构造数据集,该数据集包含两类,第一类是蓝色的+号,利用高斯分布产生5000个点,并在5000个点的基础上添加400个噪音点。此外还有红色的o数据,通过均匀分布产生5400个点。而在得到训练数据后,抽取10%作为训练集,剩余的90%作为测试集,根据训练集可以构建很多种决策树模型,(下图)列出来决策树结点和Error的关系,我们可以发现,随着决策树上的结点增多,Error即分类的错误率越来越低。如图左边图形为简单结构模型,是具有4个结点的决策树模型,Error大概为0.1左右;右边为结点为50的复杂决策模型Error大约为0.9: 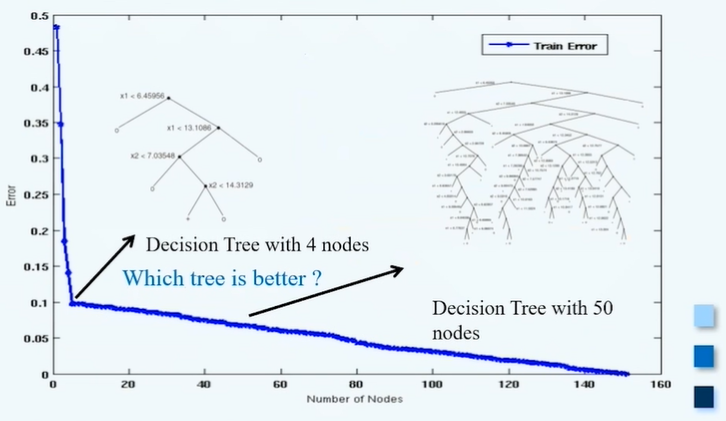
同时将两个模型的训练集和测试集的结点和Error的关系画出,如下图: 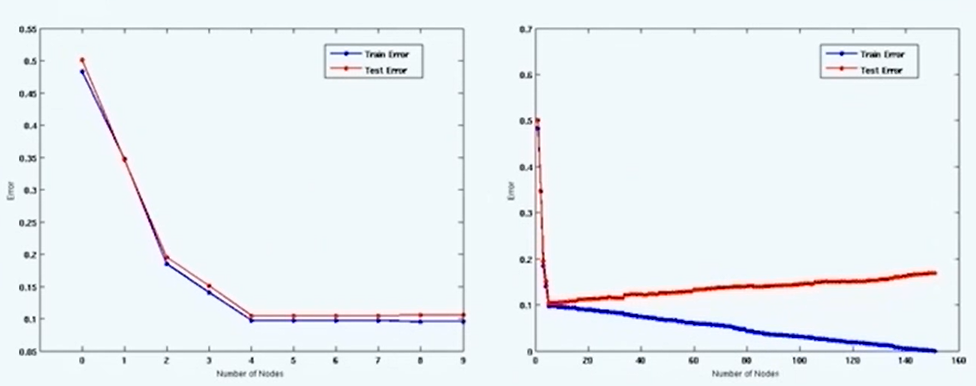
可以发现复杂模型刚开始的测试集和训练集与简单模型的变化类似,Error都是当结点数增加而降低,但之后训练集随着结点数的增加也同步增加了。这是因为复杂的模型很好的拟合了训练集,但训练集中有一部分数据可能代表了噪音和异常,当将噪音和异常都学习到分类模型中去时,就导致这个比较复杂的分类模型在测试集上的效果反而不好了。这就是过拟合现象。

