
PolarDB-X Replica的架构是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
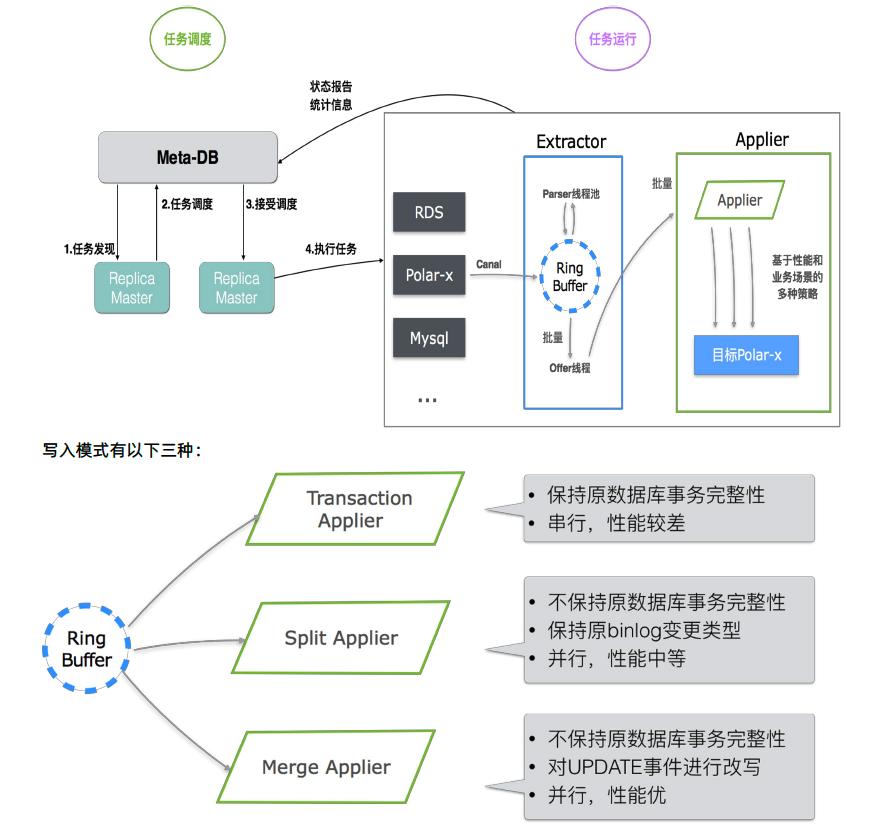
保持原数据库事务完整性的写入,即源端MySQL Binlog的事务是怎样的,在消费时就串行消费。这样在写入时能够保证事务的完整性。但这种模式性能较差。
牺牲事务,按照唯一键进行Hash,然后并发向目标端写入。这种模式性能较好。
按唯一键进行Hash,并合并相同事件类型。比如:在Hash完成后会组装队列,有一条数据ID唯一的数据有连续10次的更新,内部会将这10次更新合并成1次,这样在向目标端写入时,就不会写入10次而是只写入1次。这种模式可以大大提升性能。
以上内容摘自《PolarDB-X 从入门到实战》电子书,点击https://developer.aliyun.com/ebook/download/7674可下载完整版
PolarDB 分布式版 (PolarDB for Xscale,简称“PolarDB-X”) 采用 Shared-nothing 与存储计算分离架构,支持水平扩展、分布式事务、混合负载等能力,100%兼容MySQL。 2021年开源,开源历程及更多信息访问:OpenPolarDB.com/about


