
dataworks实现jieba中文分词 创建资源文件dict.txt后怎么在jieba.load_userdict 读取这个文件信息啊?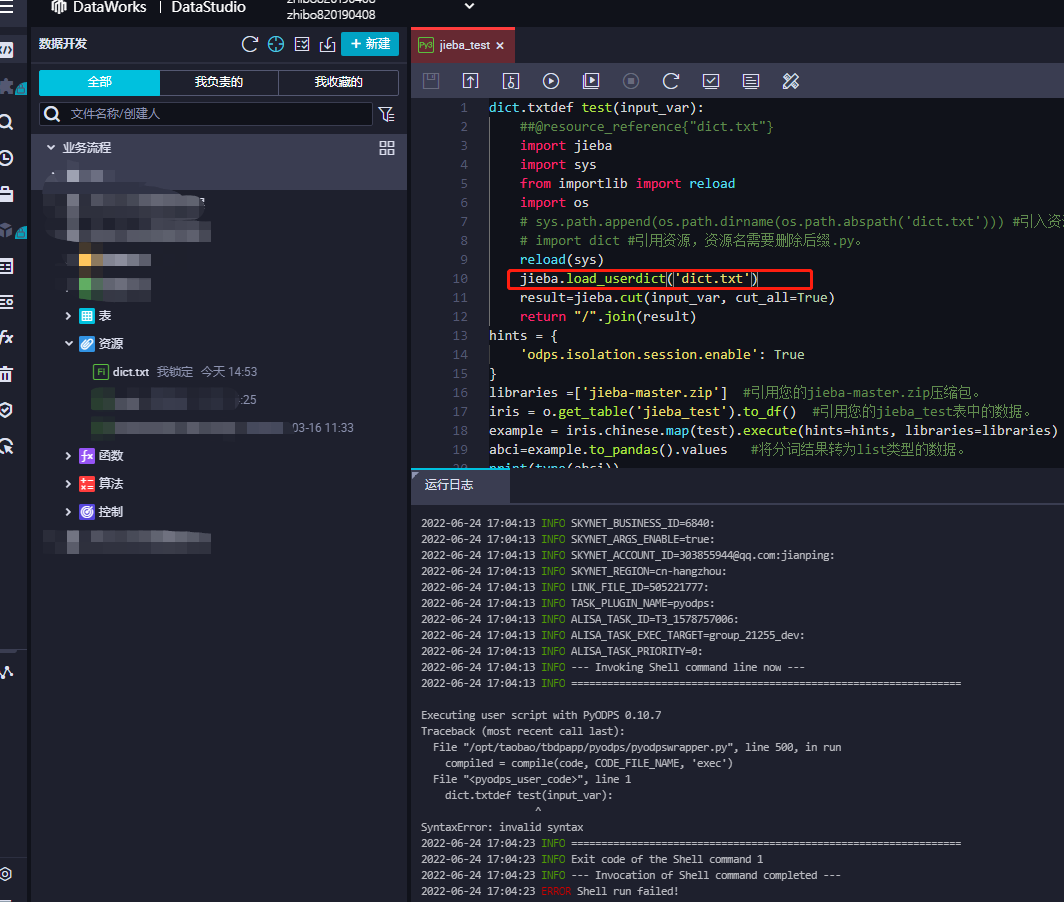
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,在 DataWorks 中使用 jieba 中文分词时,可以通过以下步骤加载自定义词典:
在 DataWorks 中创建一个新的资源文件,命名为 dict.txt,将自定义词典添加到该文件中。可以使用 DataWorks 提供的文件编辑器或者其他编辑工具,编辑 dict.txt 文件并保存。
在数据开发页面中,新建一个 Python 脚本,使用以下代码加载自定义词典:
import os
import jieba
dict_file = os.path.join(os.getcwd(), 'dict.txt')
jieba.load_userdict(dict_file)
在上面的代码中,使用 os.path 模块获取 dict.txt 文件的路径,然后使用 jieba.load_userdict() 函数加载自定义词典。
在 Python 脚本中使用 jieba 进行中文分词。例如:
import jieba
text = '你好,欢迎使用 DataWorks。'
seg_list = jieba.cut(text)
print('/'.join(seg_list))
在上面的代码中,使用 jieba.cut() 函数对文本进行分词,并使用 print() 函数输出分词结果。
需要注意的是,加载自定义词典时需要注意文件路径和编码等问题。可以使用 os.path 模块获取文件路径,并使用 codecs 模块等工具指定文件编码。同时,建议使用最新版本的 jieba 库,以获得更好的性能和效果。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


