
阿里在File Metadata中保存了共享存储文件相关的信息,它的结构是怎样的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。

Hash bucket:是为了在扩缩容的时候搬迁数据的时候,能够按照bucket来扫描,查询的时候,也是一个bucket跟着一个bucket;
Level:是merge tree的层次,0层代表实时写入的数据,这部分数据在合并的时候有更高的权重;
Physical file id:是文件对应的id,64字节是因为它不再与segment关联,不再只需要保证segment内table的唯一性,需要全局唯一;
Stripe id:是因为一个oss文件可以包含多个bucket 的文件,以stripe为单位,方便在segment一次写入的多个bucket合并到一个oss文件中。避免oss小文件,导致性能下降,和oss小文件爆炸;
Total count:是文件行数,这也是后台合并的一个权重,越大合并的权重越低 。
Visibility bitmap记录了被删除的文件信息
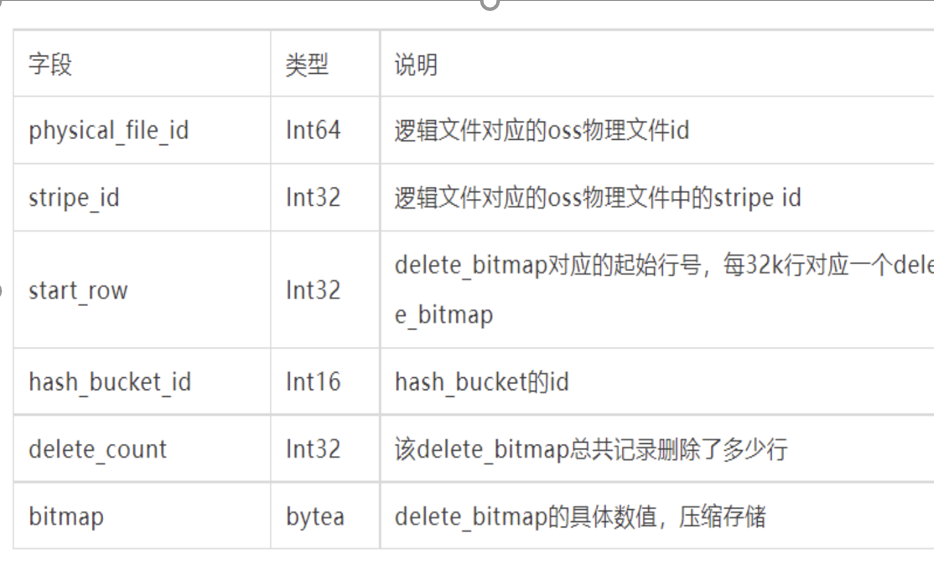
Start_row对应32k对应一个delete bitmap。这个32000 4k,行存使用的32k的page可以保存7条记录。
Delete count是被删除的数量。
我们无需访问oss,可以直接得到需要merge的文件,避免访问oss带来的延迟,另外oss对于访问的吞吐也有限额,避免频繁访问导致触发oss的限流。


