观测模型系统架构与分类是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
图10示出了观测模型的系统架构。如图所示,前一帧(第n帧)中预测的目标位置、当前帧(第n+1帧)的候选框、和候选框的特征被输入模型,输出当前帧(第n+1帧)的预测结果(目标位置)。这些候选框可能有位置变化、尺度变化、和旋转等,如图中绿色和橙色虚线框所示。 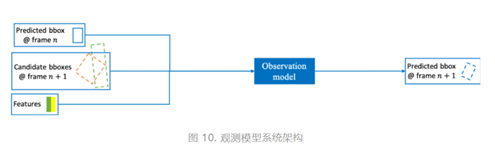
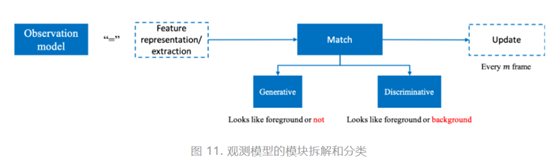
图11示出了观测模型的模块拆解和分类。如图所示,观测模型的核心模块是匹配 (match)。对于匹配方法的分类,业界的主流观点是:生成式方法 (generative) 和判别式方法 (discriminative)[1, 2, 4, 9]。这两种方法的主要区别在于是否有背景信息的引入。具体来说,生成式方法使用数学工具拟合目标的图像域特征,并在当前帧寻找拟合结果最佳(通常是拟合后重建误差最小的)的候选框。而判别式方法则是不同的思路,其将目标视为前景,将不包含目标的区域视为背景,从而将匹配问题转换成了将目标从背景中分离的问题。