
Flink里数据区分的策略是什么?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
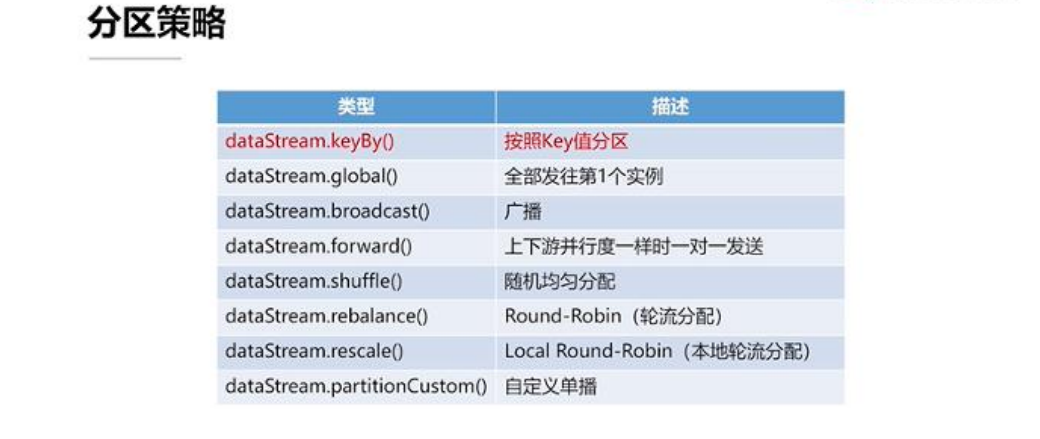
如图示,DataStream 调用 keyBy 方法后,可以把整个数据按照一个 Key 值进行分区。但要严格来讲,其实 keyBy 并不算是底层物理分区策略,而是一种转换操作,因为从 AP I 角度来看,它会把ataStream 转化成 KeyedDataStream 的类型,而这两者所支持的操作也有所不同;图中所示的这些分区策略里,稍微难理解的可能是 Rescale。Rescale 涉及到上下游数据本地性的问题,它和传统的 Rebalance,即 Round-Pobin,轮流分配类似。区别在于 Rescale 是它会尽量避免数据跨网络的传输。
如果所有上述的分区策略都不适用的话 , 我们还可以自己调用PartitionCustom 去自定义一个数据的分区。值得注意的是,它只是自定义的单播,即对每一个数据只能指定它一个下游所要发送的实例,而没有办法把它复制成多份发送到下游的多个实例中。
资料来源:《Apache Flink 必知必会》,下载链接:https://developer.aliyun.com/topic/download?id=1189
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。



