
1.依赖关系 缩减分区为窄依赖,为OnetoOneDep 增加分区为宽依赖,会产生shuffle,为什么还是OnetoOneDep 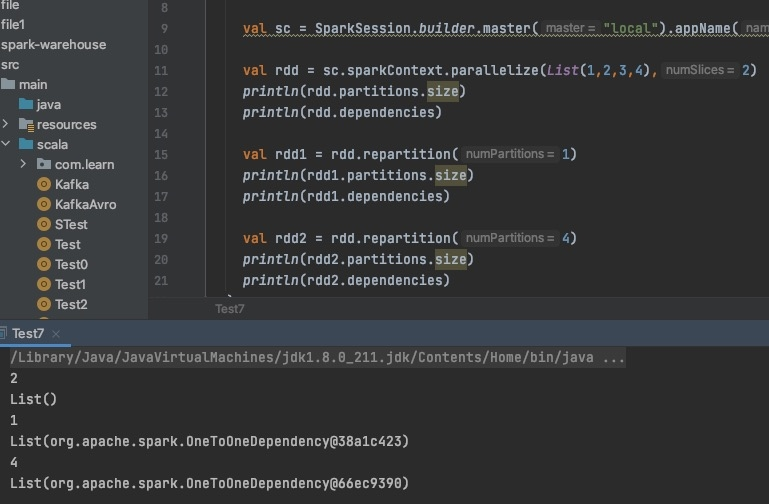 2.Job生成
2.Job生成 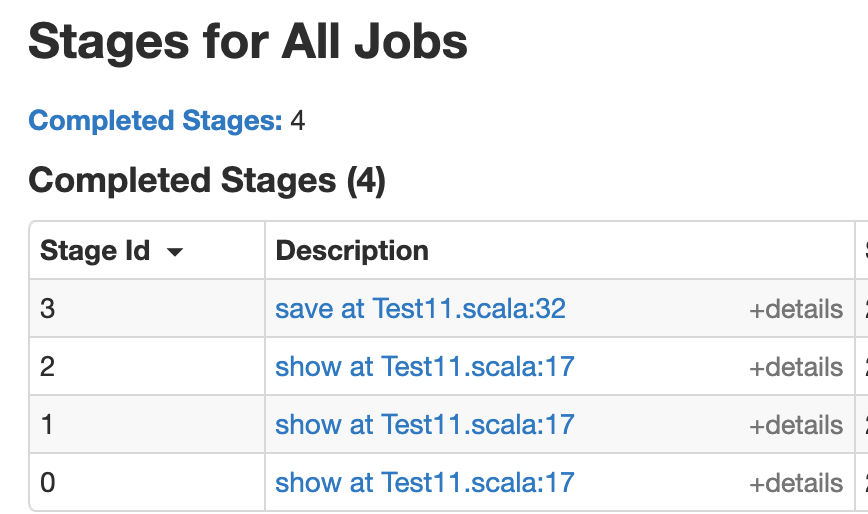
 这个任务生成了6个分区: 一个行动算子是会生成一个job,为啥这两个行动算子一个生成三个job,一个生成1一个job? 求大佬解答,万分感谢
这个任务生成了6个分区: 一个行动算子是会生成一个job,为啥这两个行动算子一个生成三个job,一个生成1一个job? 求大佬解答,万分感谢
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
您的问题涉及大数据处理中的一些概念,特别是与Apache Spark相关的依赖关系和Job的生成机制。下面我将尝试为您解答:
在Apache Spark中,RDD(弹性分布式数据集)之间的依赖关系分为两种类型:窄依赖(Narrow Dependency)和宽依赖(Wide Dependency)。
窄依赖(Narrow Dependency)指的是每个父RDD的分区最多被一个子RDD的分区所依赖。这种依赖模式下,数据可以在节点内部或者通过网络中的少量传输来完成计算,不需要进行大规模的数据洗牌(shuffle)。例如,map、filter等操作通常产生窄依赖。
宽依赖(Wide Dependency)则意味着一个父RDD的分区可能被多个子RDD的分区所依赖,这通常发生在需要通过某种键值对重新组织数据的操作上,如groupByKey、reduceByKey等。宽依赖会触发数据洗牌,因为需要将数据跨节点重新分布以满足计算需求。
您提到的“增加分区为宽依赖,会产生shuffle,为什么还是OnetoOneDep”这里可能存在一些混淆。实际上,增加分区的操作本身并不直接定义依赖关系的类型。如果增加分区的操作是在不改变数据分布逻辑的基础上进行的(比如通过repartition或者coalesce操作,并且没有涉及到基于键的聚合或重分配),那么它仍然可以保持窄依赖。但如果是通过上述提及的key-based操作导致数据重新分布,则属于宽依赖。
在Spark中,一个Job是由一个Action(行动算子)触发的计算任务集合。当执行到Action时,Spark会分析从该Action回溯到最近的RDD(即结果RDD)的所有依赖关系,这个过程会形成一个DAG(有向无环图),并根据依赖关系切分成多个Stage(阶段),每个Stage包含一系列连续的Task(任务)。
关于您提到的“一个任务生成了6个分区:一个行动算子是会生成一个job,为啥这两个行动算子一个生成三个job,一个生成1个job?”的情况,这通常取决于以下几个因素: - 行动算子的特性:不同的Action可能会有不同的执行策略,某些特定的操作可能导致Spark规划出更多的Stages,进而生成多个Job。 - 依赖链路:如果两个Action之间存在复杂的依赖关系,尤其是当这些依赖涉及到不同类型的依赖(窄依赖和宽依赖混合),Spark可能会为了优化执行效率而将它们划分为不同的Job。 - 配置设置:Spark的配置(如shuffle文件的合并策略、task的并行度等)也可能影响Job的划分。
具体到您的情况,没有具体的代码或上下文信息,很难给出确切的原因。但通常情况下,如果一个Action触发了多个Job,那可能是由于该Action导致的计算逻辑复杂,需要通过多个Stage来完成,每个Stage对应一个Job;而另一个Action可能直接作用于一个简单的窄依赖链上,因此只生成了一个Job。
希望这些解释能帮助您理解Spark中的依赖关系和Job生成机制。如果有更具体的问题或场景,欢迎继续提问!
阿里云EMR是云原生开源大数据平台,为客户提供简单易集成的Hadoop、Hive、Spark、Flink、Presto、ClickHouse、StarRocks、Delta、Hudi等开源大数据计算和存储引擎,计算资源可以根据业务的需要调整。EMR可以部署在阿里云公有云的ECS和ACK平台。
