
程序逻辑:get访问登录页面,获取登录页面验证码地址和相关参数,整合数据,手动输入验证码,post请求登录重定向页面
测试结果:开始是验证码总是错误,后来是只要输入正确的验证码就报错,
urllib2.HTTPError: HTTP Error 404: Not Found
但是输入错误的验证码会返回“验证码错误”的登录界面html
下面是header和data:
header:
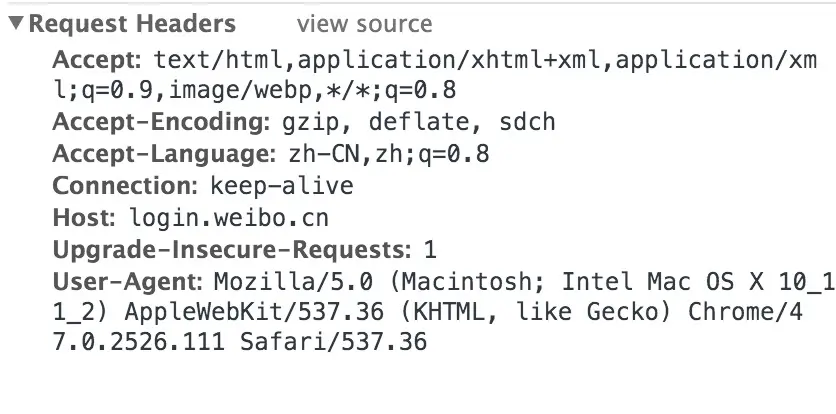
data:
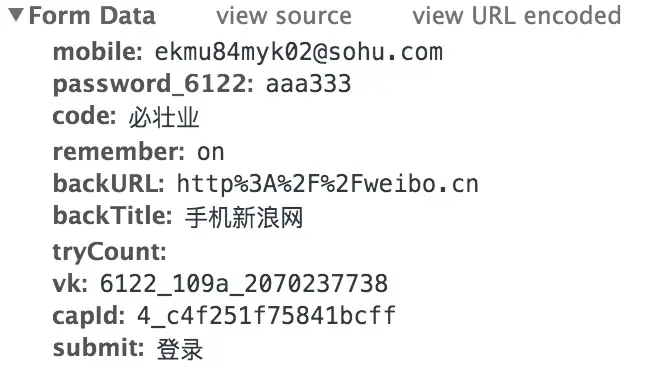
最后是代码:
#coding:utf-8
import urllib2
import cookielib
import urllib
import re
import requests
from StringIO import StringIO
import gzip
from PIL import Image
from lxml import etree
#第一步,我要得到登录界面的html
#需要url,header
def getCaptcha():
url='https://login.weibo.cn/login/'
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Host':'login.weibo.cn',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36'
}
request=urllib2.Request(url,headers=headers)
response=urllib2.urlopen(request)
return response.read()
def getPictureurl(html):
selector=etree.HTML(html)
password=selector.xpath('//input[@type="password"]/@name ')[0]
vk=selector.xpath('//input[@name="vk"]/@value ')[0]
action=selector.xpath('//form[@method="post"]/@action')[0]
code_url=selector.xpath('//img/@src')[0]
capld=code_url[code_url.find('cpt=')+4:]
path="/Users/jochuang/testcccc/pythonfetch/1.jpg"
code_picture=urllib.urlretrieve(code_url,path)
code=openPicture(path)
post(vk,action,capld,code,password)
def openPicture(path):
im=Image.open(path)
im.show()
code_number=raw_input('请输入验证码\n')
return code_number
def post(vk,action,capld,code,password):
email='ekmu84myk02@sohu.com'
password_input='aaa333'
data={
"mobile": email,
password: password_input,
"code": code,
"remember": "on",
"backURL": "http%3A%2F%2Fweibo.cn",
"backTitle": "手机新浪网",
"tryCount": "",
"vk": vk,
"capId": capld,
"submit": "登录"
}
new_url='https://login.weibo.cn/login/'+action
print new_url
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Host':'login.weibo.cn',
'Upgrade-Insecure-Requests':'1',
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.111 Safari/537.36'
}
data1=urllib.urlencode(data)
print data1
request=urllib2.Request(new_url,headers=headers,data=data1)
response=urllib2.urlopen(request)
print response.read()
if __name__=='__main__':
html=getCaptcha()
getPictureurl(html)
请教各位解惑,多谢
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
urllib2使用 CookieJar,httplib2可以使用文件管理。
httplib2可以参考 http://www.oschina.net/code/snippet_273719_54445这里的实现方式
urllib2使用 CookieJar,httplib2可以使用文件管理。
httplib2可以参考 http://www.oschina.net/code/snippet_273719_54445这里的实现方式
urllib2使用 CookieJar,httplib2可以使用文件管理。
httplib2可以参考 http://www.oschina.net/code/snippet_273719_54445这里的实现方式
