
下面是对LevelDB、TreeDB、SQLite3 这几个数据库的性能对比测试,分别使用了LevelDB (revision 39) SQLite3 (version 3.7.6.3) 及 Kyoto Cabinet’s (version 1.2.67)这三个版本的数据库。 测试机器配置:six-core Intel(R) Xeon(R) CPU X5650 @ 2.67GHz, with 12288 KB of total L3 cache and 12 GB of DDR3 RAM at 1333 MHz 文件系统:测试脚本分别跑在两台机器上,其文件系统一台为ext3(磁盘为 SATA Hitachi HDS721050CLA362),一台为ext4(配备磁盘 SATA Samsung HD502HJ) 性能测试源码:
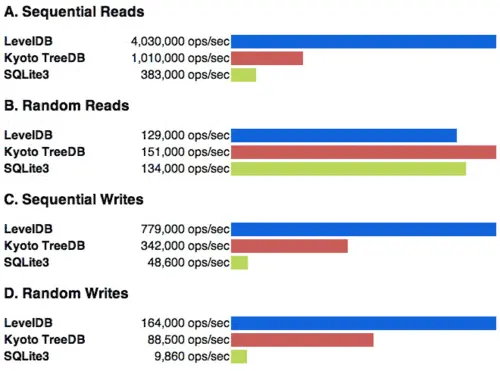 结果显示,在顺序读写和随机写上,LevelDB 在性能上都遥遥领先,在随机读上面 Kyoto Cabinet 引擎稍快一些。
结果显示,在顺序读写和随机写上,LevelDB 在性能上都遥遥领先,在随机读上面 Kyoto Cabinet 引擎稍快一些。
 LevelDB在Value较长时性能比较低,这是由于LevelDB对每一次写操作都会至少进行两次写动作,一次是写数据文件,另一次是写日志文件。这里慢的主要原因是LevelDB在进行这些操作时对值进行了过多的Copy。
LevelDB在Value较长时性能比较低,这是由于LevelDB对每一次写操作都会至少进行两次写动作,一次是写数据文件,另一次是写日志文件。这里慢的主要原因是LevelDB在进行这些操作时对值进行了过多的Copy。
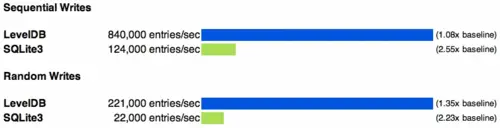 上面结果是由于LevelDB数据的组织方式,导致顺序写和随机写在性能上都变化不大。
上面结果是由于LevelDB数据的组织方式,导致顺序写和随机写在性能上都变化不大。
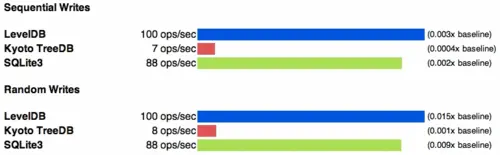 如果你看一下ext4文件系统下的测试数据,你会发现ext3和ext4在表现上非常不同。
如果你看一下ext4文件系统下的测试数据,你会发现ext3和ext4在表现上非常不同。
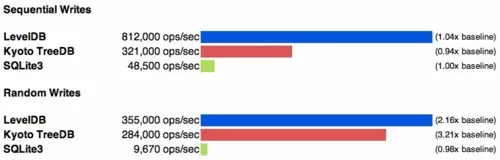
 LevelDB开启压缩比不开启压缩效率更高,而TreeDB则相反,这可能是由于TreeDB采用的压缩算法(LZO)与LevelDB采用的压缩算法(Snappy)相比计算代价更高。
LevelDB开启压缩比不开启压缩效率更高,而TreeDB则相反,这可能是由于TreeDB采用的压缩算法(LZO)与LevelDB采用的压缩算法(Snappy)相比计算代价更高。
 SQLite 在采用了大内存后性能变化并不大,而 LevelDB 和 TreeDB 的随机写性能却有显著提高。LevelDB 在增大内存后性能提升的原因是其write buffer 更大,从而减少了创建的sorted file的次数。减少了磁盘IO。而 TreeDB 的性能提升原因是由于其数据库的更大部分被映射到内存中了。
SQLite 在采用了大内存后性能变化并不大,而 LevelDB 和 TreeDB 的随机写性能却有显著提高。LevelDB 在增大内存后性能提升的原因是其write buffer 更大,从而减少了创建的sorted file的次数。减少了磁盘IO。而 TreeDB 的性能提升原因是由于其数据库的更大部分被映射到内存中了。
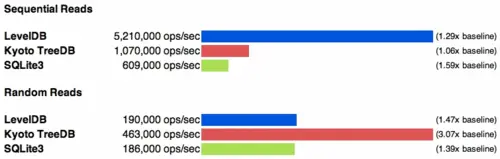 从结果可以看到,增大Cache在数据库读性能上都有所提升,其中最为显著的是TreeDB,其随机读性能大幅提升。主要是由于有足够的内存使得其所有读操作都几乎是在内存中进行。
从结果可以看到,增大Cache在数据库读性能上都有所提升,其中最为显著的是TreeDB,其随机读性能大幅提升。主要是由于有足够的内存使得其所有读操作都几乎是在内存中进行。
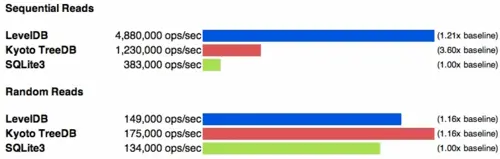 结果可以看到,取消压缩对读取性能提升不是特别大,当然,如果你的数据都在内存中的话,执行解压操作也不会对性能造成太大影响。 原文:
leveldb.googlecode.com 译文:
http://blog.nosqlfan.com/html/2819.html -*-*-
结果可以看到,取消压缩对读取性能提升不是特别大,当然,如果你的数据都在内存中的话,执行解压操作也不会对性能造成太大影响。 原文:
leveldb.googlecode.com 译文:
http://blog.nosqlfan.com/html/2819.html -*-*-
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
学习了~######mark.######最烦有人在博客,或者网上发项目测试数据,因为影响测试数据的因素有很多,参考价值真的不大。###### mysql都没学会...有空看看leveldb######leveldb 这么棒? 没用过哦...######leveldb, bravo, bravooooooooo! ######对进行比较的这几个选手的选择感到奇怪。为什么不是和mysql,mongodb之类使用率比较高的数据库进行对比呢?sqlite3? Kyoto Cabinet’s?我真不太熟,求指教。######leveldb的定位于mysql和mongodb差别很大,leveldb更类似于memcached/redis,属于kv的缓存,sqlite轻量级在本地小规模缓存和数据存储用得多,至于KC,确实选择的有点。。。,IMHO其实能和memcached/redis benchmark下更有价值###### 看起来 LevelDB 很棒!######数据库的数据量是多少? 4G?######这个不是LevelDB里面的文档么
mysql都没学会...有空看看leveldb######leveldb 这么棒? 没用过哦...######leveldb, bravo, bravooooooooo! ######对进行比较的这几个选手的选择感到奇怪。为什么不是和mysql,mongodb之类使用率比较高的数据库进行对比呢?sqlite3? Kyoto Cabinet’s?我真不太熟,求指教。######leveldb的定位于mysql和mongodb差别很大,leveldb更类似于memcached/redis,属于kv的缓存,sqlite轻量级在本地小规模缓存和数据存储用得多,至于KC,确实选择的有点。。。,IMHO其实能和memcached/redis benchmark下更有价值###### 看起来 LevelDB 很棒!######数据库的数据量是多少? 4G?######这个不是LevelDB里面的文档么

