
通过python爬虫对百度或谷歌的单个检索结果网页爬虫,能否在获取的代码中取得返回结果数,
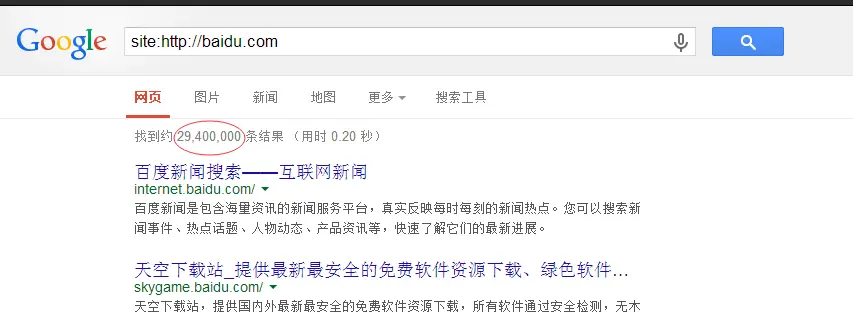
从爬虫返回的代码获得29,400这个数值,我在爬取到的代码中没有发现,不知道是不是因为这个数值是动态生成,所以不会返回。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
看了下页面源码,的确没有这个,是放在一个<div id="resultStats">标签中。应该是js计算得到之后绘制上去的######回复 @Feng_Yu : 常见的就是ajax的计算结果,比如oschina的动弹,知乎的折叠回复,都暗藏在ajax中,需要单独发起一个请求获取######回复 @Disappeared_man : 没有。这个是js计算得到的。通常想爬这种js计算后得到的结果一般是有两种方案。一种是找到那段js代码,读懂算法,然后自己写代码实现这段js的功能。另一种是调用一个浏览器,让浏览器访问页面之后执行页面的js,拿回浏览器返回的源码######谢谢。我也不知道为什么,有的时候点了看审查元素,然后再看源码就会出现,但是爬虫每次都不会出现。请问有没有什么好的解决方案??###### 
我这里有啊,如果你的没有的话你就看看是哪个请求把数字填充上去的,然后你爬虫再去请求一下这个地址就OK ######你这个是js绘制后的页面。你试试直接curl访问页面,拿到的源码中就没有这个######selenium + phantomJS

