
1.单步执行发现 在483行print_func=printf时,printf指向A0地址 486行:print_func("===...)打印信息正常 497行:进入debug_mm_overview(print_func)后print_func地址A1=A0+1; 经过测试直接调用debug_mm_overview(NULL)时,是能正常运行的,此时相当于print_func赋值为NULL,在debug_mm_overview()函数里会重新给print_func赋值为printf 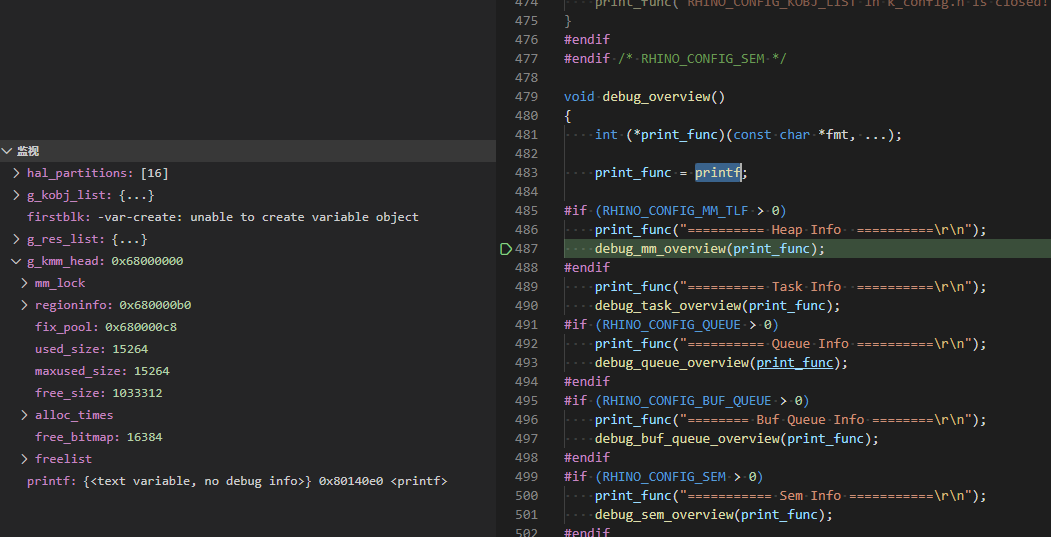 如上图printf为一个地址,到了下图print_func就加一了,导致他又不是NULL,地址又不正确,一调用打印就直接硬件错误死循环了
如上图printf为一个地址,到了下图print_func就加一了,导致他又不是NULL,地址又不正确,一调用打印就直接硬件错误死循环了 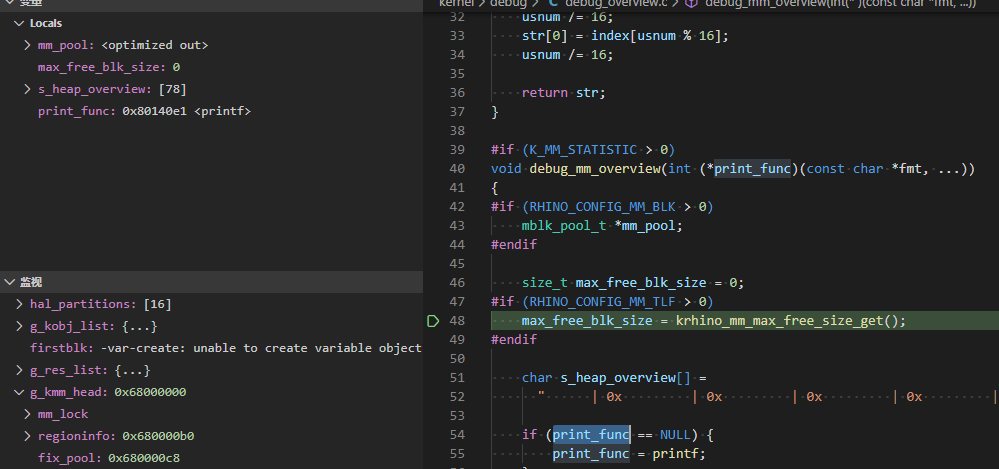 这个问题咋个处理?主要还是想知道为什么会这样 顺带提一下,不知道是不是我外扩了SRAM,并将堆放到外部SRAM造成的。反正放在内部的时候也是执行就跳硬件错误的。
这个问题咋个处理?主要还是想知道为什么会这样 顺带提一下,不知道是不是我外扩了SRAM,并将堆放到外部SRAM造成的。反正放在内部的时候也是执行就跳硬件错误的。
解决思路:外部SRAM的硬件时间配置在临界点,不稳定增加了一个数量级就好了。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
从您的描述来看,这个问题涉及到嵌入式系统中的程序执行、内存管理和硬件交互。您遇到的问题可能与以下几个方面有关:
地址偏移:您提到的print_func在进入debug_mm_overview函数前后地址发生了变化(A0变为A1),这可能是由于函数调用时的栈帧调整导致的。在很多架构中,函数调用会修改栈指针,从而影响到栈上变量的地址。如果print_func是作为局部变量或者通过某些方式传递给函数的,它的地址可能会因为栈的变化而改变。
外扩SRAM配置问题:您怀疑问题可能与外扩SRAM及其配置相关。确实,如果SRAM的时序参数配置不当(如读写周期、等待状态等),可能导致访问时出现错误或不稳定现象。增加访问时间(数量级)可能帮助解决了时序上的临界问题,确保了数据的正确读取。
堆管理问题:将堆放到外部SRAM后,需要确保操作系统或运行库正确地识别并管理这块内存区域。如果堆管理器没有正确配置或初始化外部SRAM,可能会导致内存分配和释放操作出现问题,进而影响到像printf这样的全局函数指针的正确性。
解决思路及建议:
检查栈空间:确认print_func变量是否在栈上,如果是,理解其在函数调用前后的地址变化是正常的。考虑是否可以将其声明为静态变量或全局变量以保持地址不变。
验证SRAM配置:再次审查SRAM的时序设置,包括但不限于读写周期、片选延迟、等待状态等,确保它们与SRAM的实际规格相匹配,并留有足够的余量以应对速度差异。
堆管理配置:如果使用了动态内存分配,确保动态内存管理器(如malloc/free)正确识别并使用外部SRAM。可能需要对链接脚本或内存管理初始化代码进行调整。
调试工具辅助:使用更详细的调试工具(如JTAG调试器)来监控函数调用期间的寄存器变化、内存访问情况,以及堆栈指针的变动,这有助于定位问题的具体原因。
代码审查:检查debug_mm_overview函数内部是否有意或无意修改了print_func的值,确保没有逻辑错误导致其指向无效地址。
综上所述,问题可能源于多个层面,需要综合分析和调试才能找到确切原因并解决。
