
什么是MongoDB分片?看完这篇你就知道了
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
一、分片
分片,也叫做分区,是一种常用的数据库优化技术。其含义就是将数据拆分,将数据分散到不同机器上的过程。这样就能够使得系统可以存储更多的数据,处于更大的负载。
几乎所有的数据库软件都可以进行手动分片,通过应用程序管理不同服务器上的不同数据,查询也需要寻找正确的服务器。这样虽然可以减轻负载,但是却难以维护,比如我们向集群添加节点或者删除节点,都需要对应的调整数据的分布。
MongoDB在这一点上做得不错,它支持自动分片,集群可以自动切分数据,达到负载均衡,从而使管理人员可以摆脱手动分片。
二、mongo的分片
下面说说分片的原理。MongoDB分片的基本思想就是将集合切分成小块,这些块分散到若干片里面,每个片只负责总数据的一部分。
应用程序不需要知道哪些片对应哪些数据,也不需要知道数据是否已经拆分。MongoDB通过另外一个独立的路由进程mongos来实现这个功能。
mongos路由进程知道所有数据的存放位置,所以应用可以连接它来正常发送请求。而对于应用来说,自己只知道连接了一个普通的mongod。也就是说,mongos对应用隐藏了分片的细节。
为什么要隐藏了?其实就是为了拓展的时候,不必修改应用程序的代码。
应用场景
说完了原理,那什么时候需要用到分片呢?有以下几种情况:
机器的磁盘不够用了;
单个mongodb已经不再满足性能需要;
想将大量数据放入内存提高性能。
一般来说,先从不分片开始,然后在需要的时候将其转换成分片。
片键
设置分片时,需要从集合里面选一个键,用该键的值作为数据拆分的依据。这个键成为片键。
假设有个文档集合表示的是人员,如果选择名字”name”做为片键,第一篇可能会存放名字以A-F开头的文档;第二片存G-P开头的文档;第三篇存Q-Z的文档。
随着增加或删除片,MongoDB会重新平衡数据,使得每片的流量比较均衡,数据量也在合理范围内。
那么我们应该如何选择片键呢?
如果我们选择了时间属性的键作为片键,那么随着时间增长,所有的文档都会以最后一片插入。这就不适合写入操作负载很高的情况,但是查询起来就比较方便。
如果我们选择了分布均匀的片键,就会提高写入操作的负载能力,但是就会影响查询的性能。
我们也可以选择复合片键,将两个属性键结合为一个片键。
其实和索引的原理相似,事实上,片键也是最常用的索引。
三、分片你来试试
1、mongodb分片的基本结构包括:多个数据库节点shard、configserver、mongos组成。
·shard1、shard.....:mongodb服务的片节点。存储数据。
·configserver:维护meta信息,判断某条数据存储到哪台节点的服务器上。本身不存储数据
·mongs:查询数据时,要先找到configserver,询问查询的数据到哪个shard上取数据。
2、搭建shard分片节点服务器。首先启动27017和27018两个实例节点做分片服务器。
①、创建服务器存储数据的数据库路径和log路径。其中m17,m18作为分片服务器,m20作为configserver服务器。
②、启动两个分片服务器实例
-storageEngine=mmapv1
-storageEngine=mmapv1
 ③、启动configsvr服务器
③、启动configsvr服务器
-storageEngine=mmapv1
 --dbpath:指定数据库路径
--dbpath:指定数据库路径
--logpath:指定日志存放路径
--fork:后台运行
--port:设置启动的端口
--replSet:设置同一个复制集,复制集的名称自定义
--journal:32linux需要这个参数才能启动,64位不需要这个参数
--smallfiles:启动时占用较小的空间,如果空间不是很缺少,一般不需要这个参数
--storageEngine:设置数据库的引擎,由于不支持wiredTiger引擎,需要切换支持的引擎,64位系统不需要切换引擎。
④、启动mongos路由
--configdb:启动mongs路由需要指明哪个configsvr为他服务,所以后面填写为他服务的configsvr服务器的地址。
⑤、链接mongos添加分片服务器
链接mongos: ./bin/mongo --port 30000
添加分片:
sh.addShard('127.0.0.1:27018')
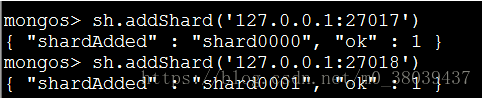 查看添加分片状态:
查看添加分片状态: 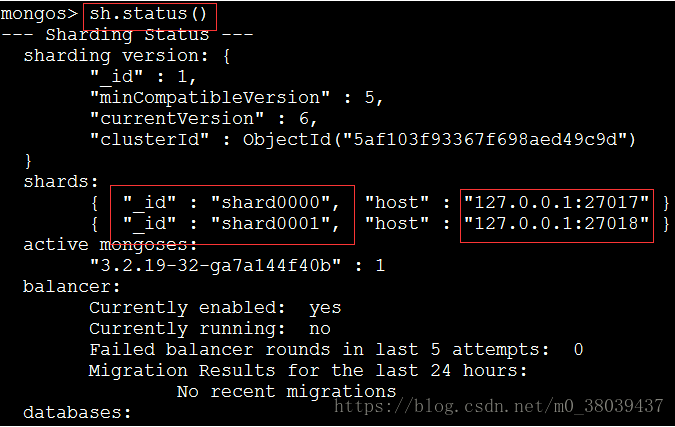 ⑥、启动数据库分片功能
⑥、启动数据库分片功能
 shop为需要开启分片功能的数据库。
shop为需要开启分片功能的数据库。
查看shop数据库是否开启了分片功能
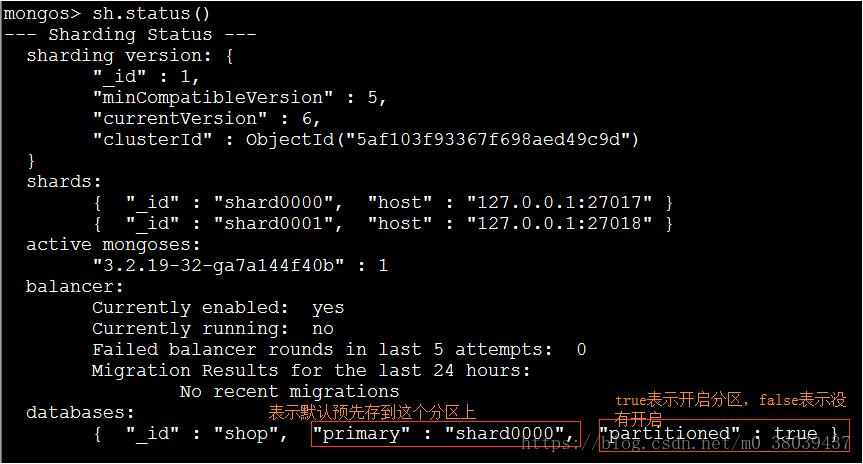
⑦、设置数据库表格分片
将shop数据库下的goods表格根据goods_id字段进行分片。
添加分片语法:
Field是collection的一个字段,系统将会利用filed的值,来计算应该分到哪一个片上。
这个filed叫“片键”,shard key。  ⑧、修改chunk的单位大小,达到调整每个chunk存放的数据量。
⑧、修改chunk的单位大小,达到调整每个chunk存放的数据量。
chunk工作原理:
mongodb分片是以chunk为单位进行分片,当其中的一个节点(27017节点)上存放的chunk比另一个节点(27018)上存放的chunk大于3倍时,那么27017节点上将会将部分chunk移动到27018节点上,来维护各个节点片之间数据的均衡。
查看默认chunk的大小
a、首先保证分片的数据库下有数据,如果没有则插入一条数据。
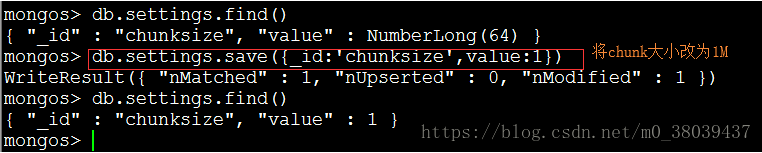
b、查看chunk大小 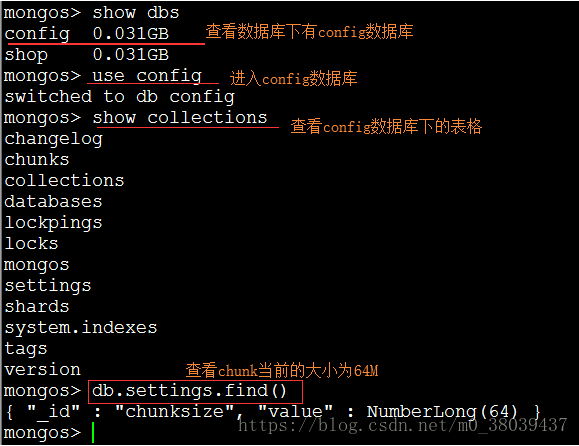 c、设置chunk大小
c、设置chunk大小
⑨、批量添加数据,查看分片数据。
添加了一百万条数据后,在查看数据在分片上存储的数据。
查看chunk在每个分配上的数量。 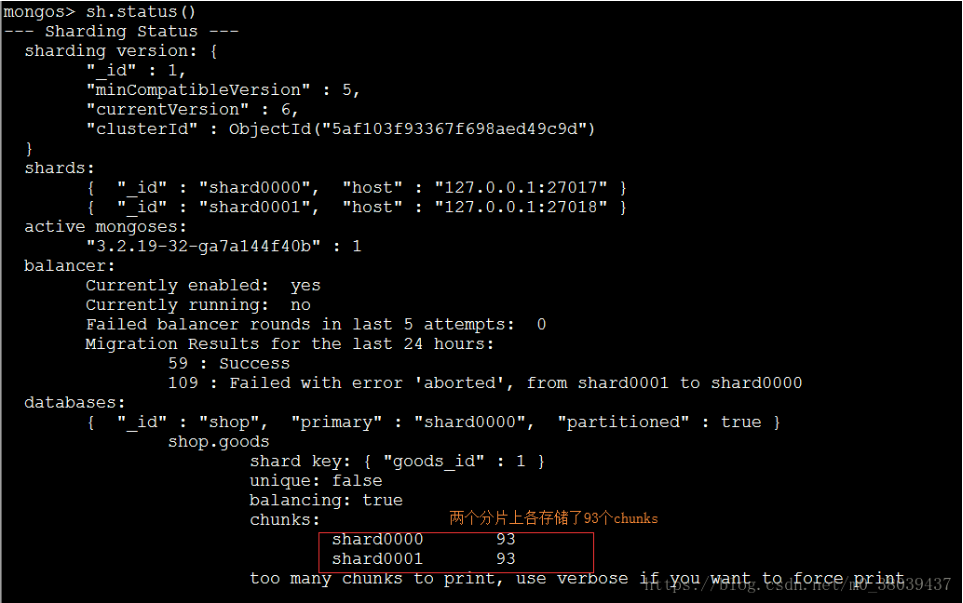 查看27017分片的数据条数
查看27017分片的数据条数
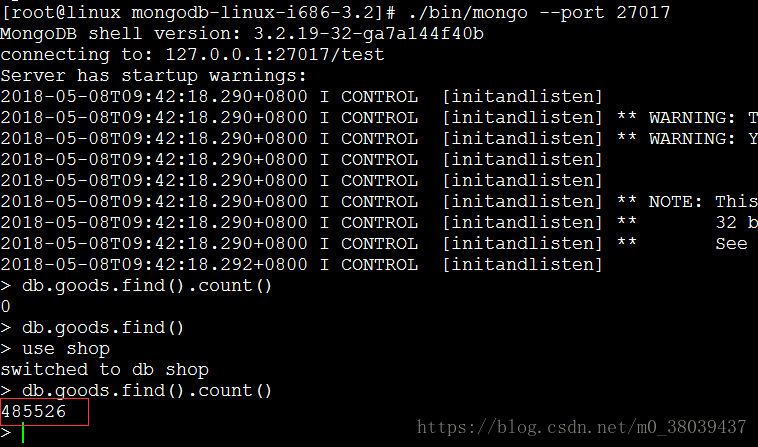 查看27018分片上的数据条数
查看27018分片上的数据条数 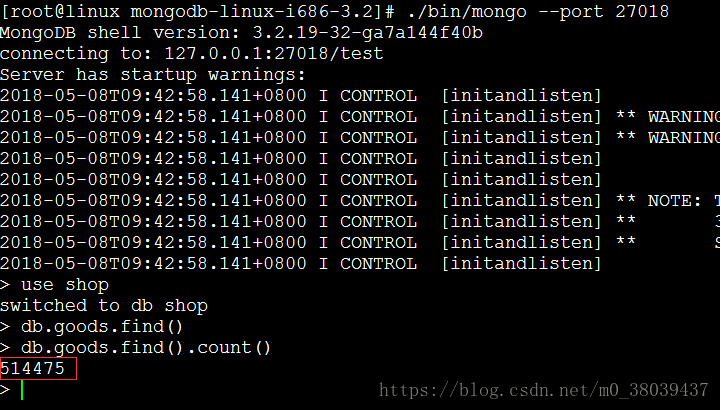 到这里,分片就完成了。
到这里,分片就完成了。
