
简单线性回归
利用简单的线性回归去预测食品交易的利润。假设你是一个餐厅的CEO,最近考虑在其他城市开一家新的分店。连锁店已经在各个城市有交易,并且你有各个城市的收益和人口数据,你想知道城市的人口对一个新的食品交易的预期利润影响有多大。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
检查数据
首先检查“ex1data1”文件中的数据。“txt”在“我的存储库”的“数据”目录中。首先导入一些库。
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
现在开始运行,使用Pandas把数据加载到数据帧里,并且使用“head”函数显示前几行。
path= os.getcwd()+ '\data\ex1data1.txt'
data= pd.read_csv(path, header=None, names=['Population','Profit'])
data.head()
Population Profit
0 6.1101 17.5920
1 5.5277 9.1302
2 8.5186 13.6620
3 7.0032 11.8540
4 5.8598 6.8233
Pandas提供的另外一个有用的函数是”describe”函数,它能在数据集上计算一些基本统计数据,这有助于在项目的探索性分析阶段获得数据的“feel”。
data.describe()
Population Profit
count 97.000000 97.000000
mean 8.159800 5.839135
std 3.869884 5.510262
min 5.026900 -2.680700
25% 5.707700 1.986900
50% 6.589400 4.562300
75% 8.578100 7.046700
max 22.203000 24.147000
检查有相关的统计数据可能会有帮助,但有时需要找到方法使它可视化。这个数据集只有一个因变量,我们可以把它放到散点图中以便更好地了解它。我们可以使用pandas为它提供的“plot”函数,这实际上只是matplotlib的一个包装器。
data.plot(kind='scatter', x='Population', y='Profit', figsize=(12,8))
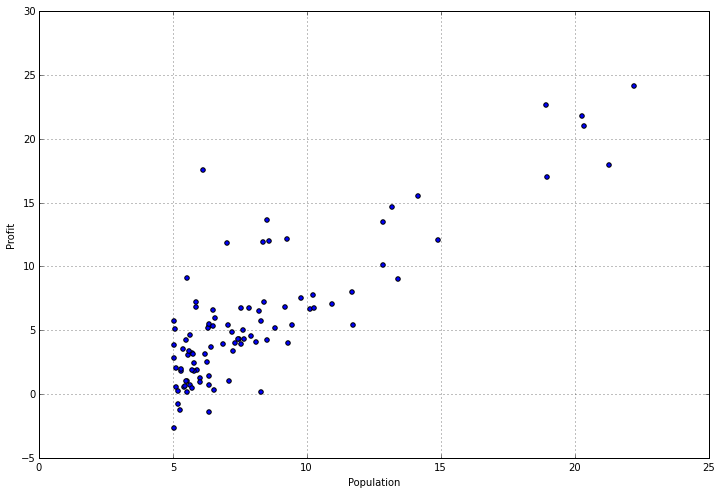
我们可以清楚地看到,随着城市规模的增加,利润呈线性增长。现在让我们进入有趣的部分——从零开始实现python中的线性回归算法。
实现简单的线性回归
线性回归是建立因变量和一个或多个自变量之间关系的一种方法(如果只有一个自变量就是简单线性回归;如果是多个自变量就是多重线性回归)。我们试图使用参数theta创建数据X的线性模型,它描述了数据的方差,给出新的数据点,我们可以在不知道实际结果的情况下准确地预测。
在实现过程中,我们使用叫做梯度下降的优化技术寻找参数theta。如果你熟悉线性回归,你可能会意识到有另一种方法可以找到线性模型的最优参数,就是做“正态方程”,它可以用一系列矩阵运算来解决这个问题。然而,这种方法的问题就是在大数据集中不能很好地扩展,相比之下,我们可以使用梯度下降和其他优化方法的变体来扩展到无限大小的数据集,因此对于机器学习问题,梯度下降更实用。
理论知识已经足够了,下面我们写一些代码。我们首先要写的就是成本函数,成本函数通过计算模型参数和实际数据点之间的误差来计算模型预测的误差,从而评估模型的质量。例如,如果给定城市的人口数量是4,但是我们预测是7,我们的误差就是 (7-4)^2 = 3^2 = 9(假设为L2或“最小二乘法”损失函数)。我们为X中的每个数据点执行此操作,并对结果求和以获取成本。下面是函数:
def computeCost(X, y, theta):
inner= np.power(((X* theta.T)- y),2)
return np.sum(inner)/ (2 * len(X))
注意,这里没有循环。我们利用numpy的linear algrebra功能将结果计算为一系列矩阵运算。这比不优化的“for”循环的效率要高得多。
为了使这个成本函数与我们上面创建的pandas数据框架无缝对接,我们需要做一些操作。首先,在开始插入一列1s的数据帧使矩阵运算正常工作。然后把数据分离成自变量X和因变量y。
# append a ones column to the front of the data set
data.insert(0,'Ones',1)
# set X (training data) and y (target variable)
cols= data.shape[1]
X= data.iloc[:,0:cols-1]
y= data.iloc[:,cols-1:cols]
最后把数据框架转换为numpy矩阵并实例化参数matirx。
# convert from data frames to numpy matrices
X= np.matrix(X.values)
y= np.matrix(y.values)
theta= np.matrix(np.array([0,0]))
在调试矩阵运算时要查看正在处理的矩阵的形状。矩阵乘法看起来像(i x j)*(j x k)=(i x k),其中i、j和k是矩阵相对维度的形状。
X.shape, theta.shape, y.shape
((97L, 2L), (1L, 2L), (97L, 1L))
调试一下成本函数。参数已经被初始化为0,所以解不是最优的,但是我们可以看看它是否有效。
computeCost(X, y, theta)
32.072733877455676
目前为止一切都很顺利。现在我们需要使用练习文本中定义的更新规则来定义一个函数,来对参数theta执行梯度下降。这是梯度下降的函数:
def gradientDescent(X, y, theta, alpha, iters):
temp= np.matrix(np.zeros(theta.shape))
parameters= int(theta.ravel().shape[1])
cost= np.zeros(iters)
for iin range(iters):
error= (X* theta.T)- y
for jin range(parameters):
term= np.multiply(error, X[:,j])
temp[0,j]= theta[0,j]- ((alpha/ len(X))* np.sum(term))
theta= temp
cost[i]= computeCost(X, y, theta)
return theta, cost
梯度下降的就是计算出每一个迭代的误差项的梯度,以找出适当的方向来移动参数向量。换句话说,就是计算对参数的修改以减少错误,从而使我们的解决方案更接近最佳解决方案。
我们再一次依赖于numpy和线性代数求解,你可能注意到我的实现不是100%的优化,事实上,有完全去除内循环和一次性更新所有参数的方法。我把它留给读者去完成。
现在我们已经有了一种评估解决方案的方法,并且找到一个好的解决方案,把它应用到我们的数据集中。
# initialize variables for learning rate and iterations
alpha= 0.01
iters= 1000
# perform gradient descent to "fit" the model parameters
g, cost= gradientDescent(X, y, theta, alpha, iters)
g
矩阵x([[-3.24140214, 1.1272942 ]])
注意我们已经初始化了一些新的变量。梯度下降函数中有叫做alpha和iters的参数。alpha是学习速率-它是参数更新规则中的一个因素,它帮助决定算法收敛到最优解的速度。iters是迭代次数。没有严格的规则去规定如何初始化这些参数,但是通常会涉及到试错法。
现在有一个参数向量描述数据集的最优线性模型,一个快速评估回归模型的方法就是观察数据集上的解决方案的总误差:
computeCost(X, y, g)
4.5159555030789118
这要比32好很多。
查看结果
我们将使用matplotlib来可视化我们的解决方案。我们在数据的散点图上覆盖一条线表示我们的模型,看它是否合适。我们使用numpy的“linspace”函数在我们的数据范围内创建一系列均匀间隔的点,然后用我们的模型“评估”这些点,看预期的利润会是多少。我们把它变成线形图。
x= np.linspace(data.Population.min(), data.Population.max(),100)
f= g[0,0]+ (g[0,1]* x)
fig, ax= plt.subplots(figsize=(12,8))
ax.plot(x, f,'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
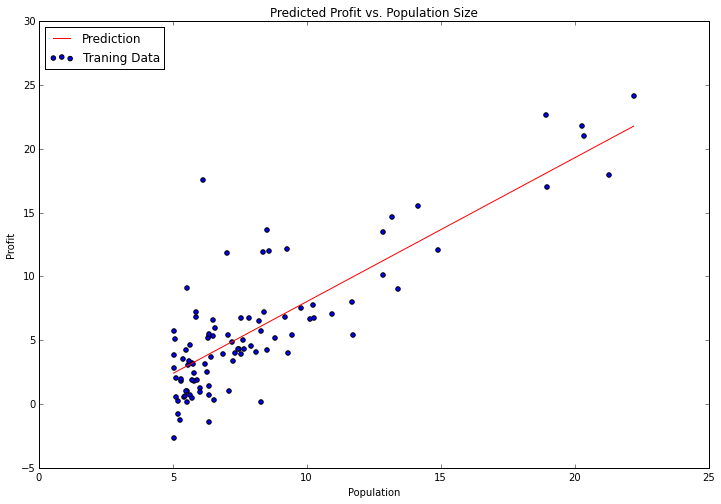
我们的解决方案看起来是数据集的最优线性模型。梯度体系函数会在每个训练迭代中输出一个成本向量,我们可以出绘制出线形图。
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(np.arange(iters), cost, 'r')
ax.set_xlabel('Iterations')
ax.set_ylabel('Cost')
ax.set_title('Error vs. Training Epoch')
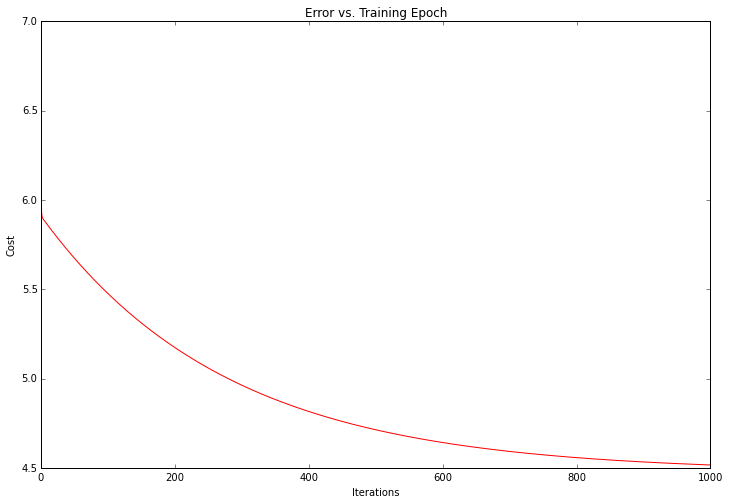
成本一直在降低——这就是凸优化问题的一个示例。如果你要绘制问题的整个解决方案空间,它看起来会像一个碗的形状,“盆地”表示最优解。
