
Flink中的序列化是如何做的?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink实现了自己的序列化框架,Flink处理的数据流通常是一种类型,所以可以只保存一份对象Schema信息,节省存储空间。又因为对象类型固定,所以可以通过偏移量存取。
Java支持任意Java或Scala类型,类型信息由TypeInformation类表示,TypeInformation支持以下几种类型:
BasicTypeInfo:任意Java 基本类型或String类型。
BasicArrayTypeInfo:任意Java基本类型数组或String数组。
WritableTypeInfo:任意Hadoop Writable接口的实现类。
TupleTypeInfo:任意的Flink Tuple类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
GenericTypeInfo: 任意无法匹配之前几种类型的类。
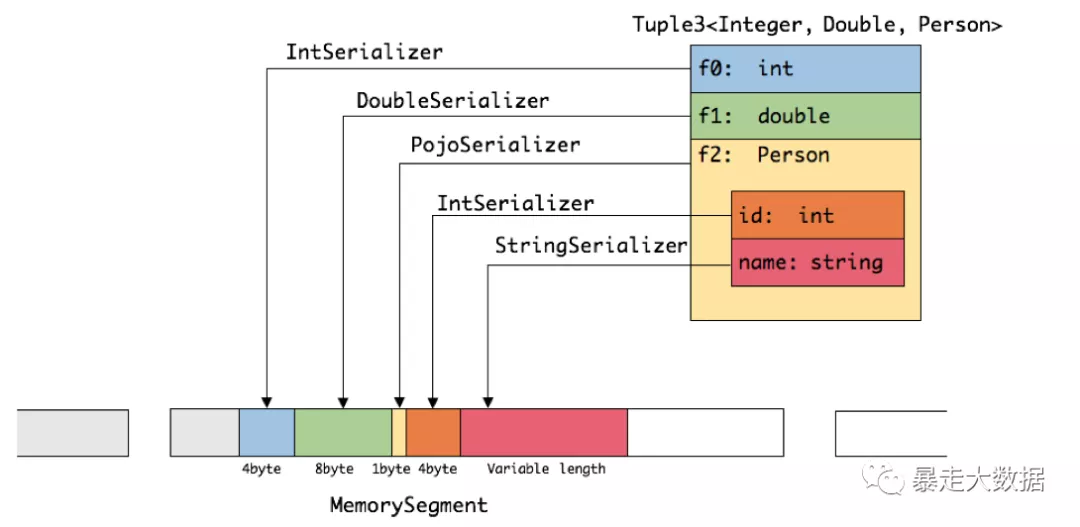
针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。每个TypeInformation中,都包含了serializer,类型会自动通过serializer进行序列化,然后用Java Unsafe接口写入MemorySegments。如下图展示 一个内嵌型的Tuple3<integer,double,person> 对象的序列化过程:
操纵二进制数据: Flink提供了如group、sort、join等操作,这些操作都需要访问海量数据。以sort为例:首先,Flink会从MemoryManager中申请一批 MemorySegment,用来存放排序的数据。 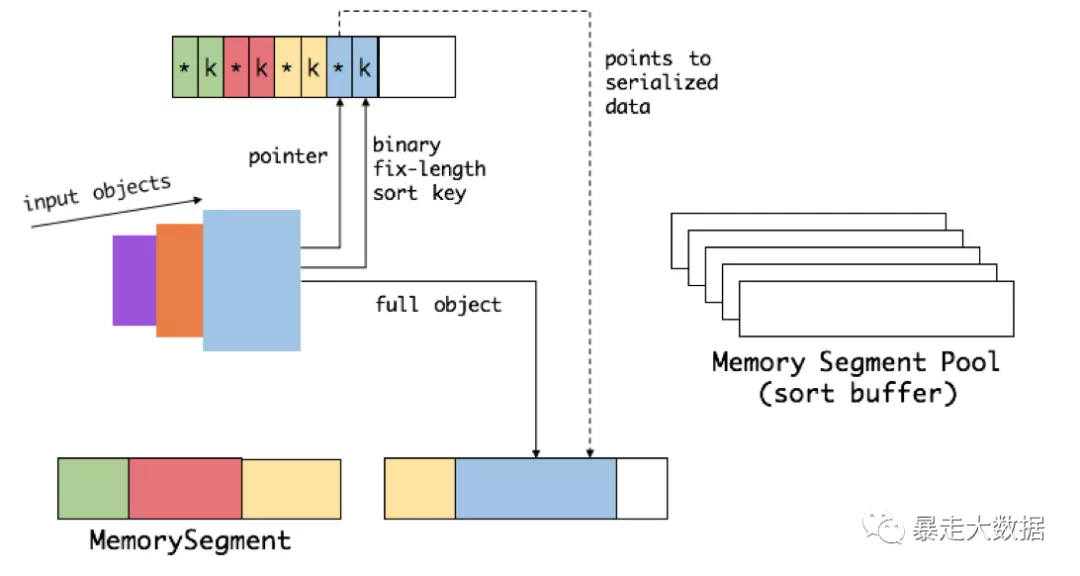
这些内存会分为两部分,一个区域是用来存放所有对象完整的二进制数据。另一个区域用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。将实际的数据和point+key分开存放有两个目的。
第一,交换定长块(key+pointer)更高效,不用交换真实的数据也不用移动其他key和pointer;
第二,这样做是缓存友好的,因为key都是连续存储在内存中的,可以增加cache命中。排序会先比较 key 大小,这样就可以直接用二进制的 key 比较而不需要反序列化出整个对象。访问排序后的数据,可以沿着排好序的key+pointer顺序访问,通过 pointer 找到对应的真实数据。
