
MaxCompute2.0新增了一套
非结构化数据处理框架,支持通过外部表的方式直接访问OSS,OTS等。Studio对此提供了一些代码模板支持,方便用户快速开发。
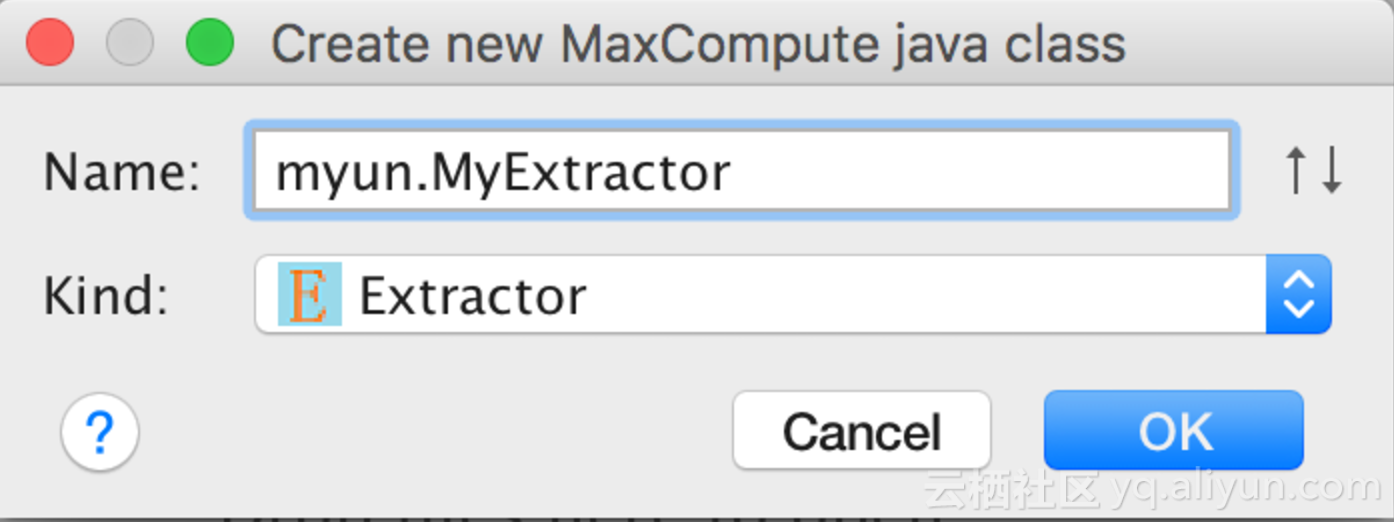
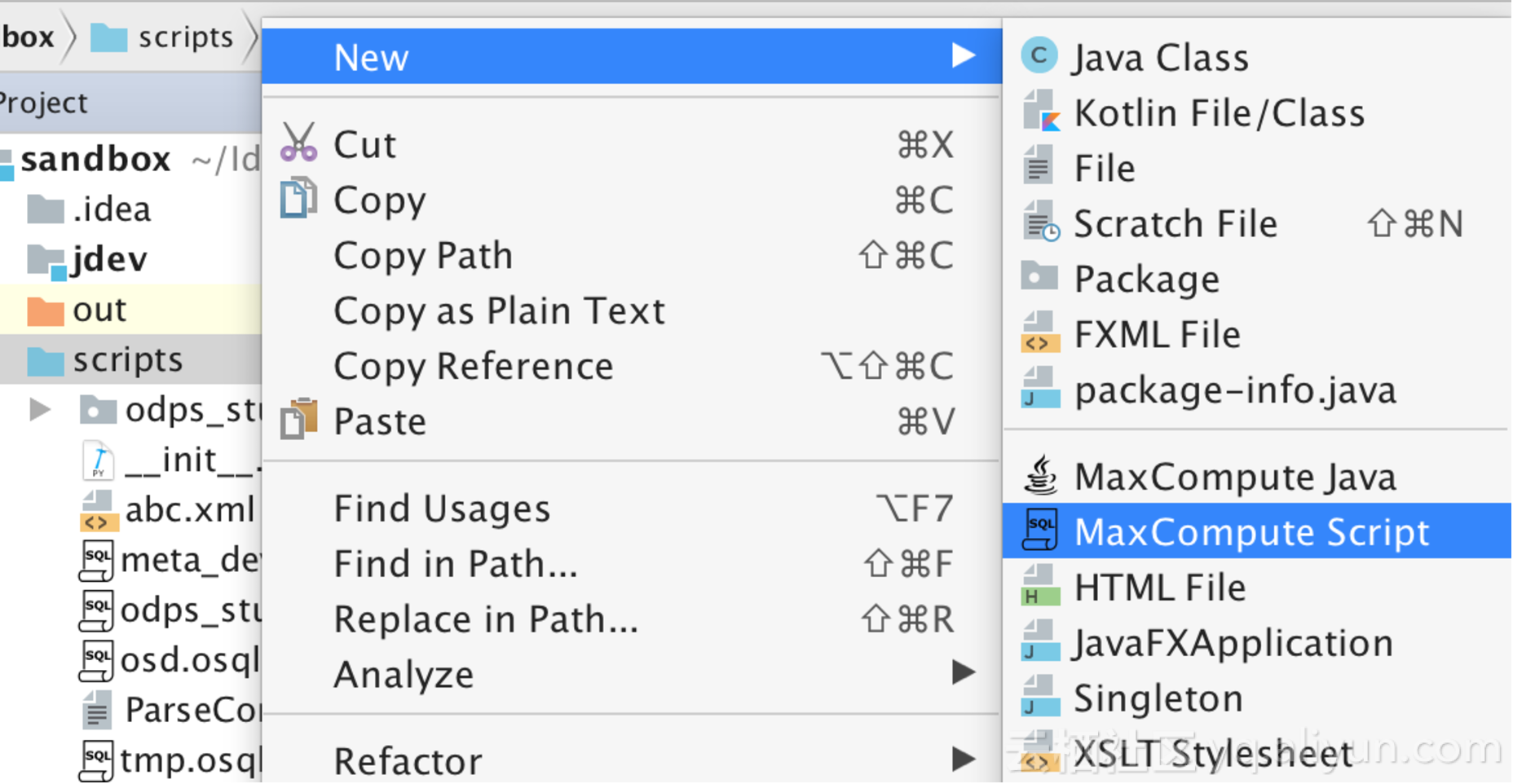
编写StorageHandler/Extractor/Outputter
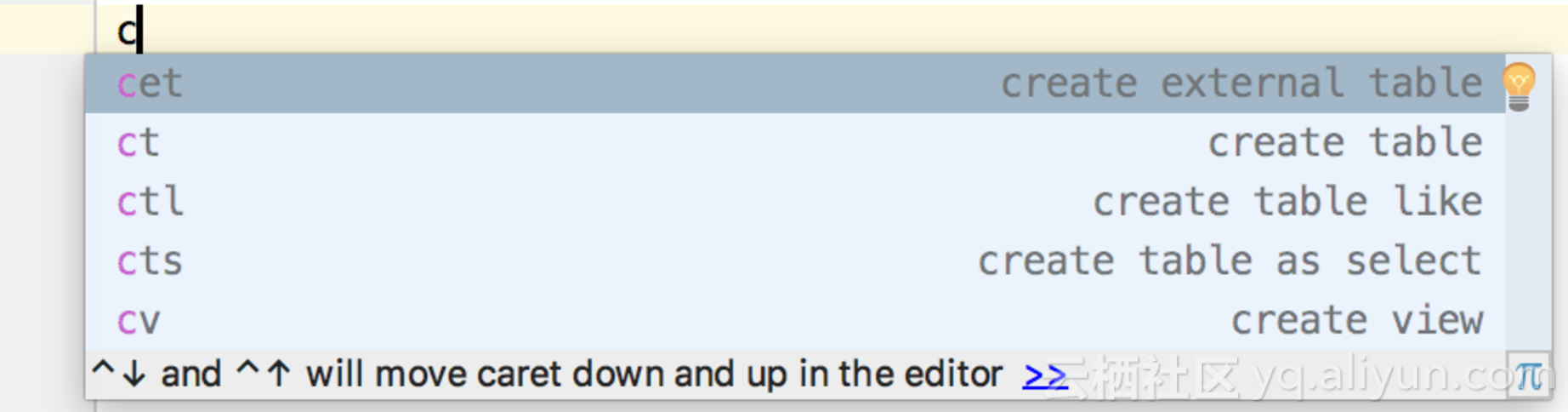 然后修改外部表名称,列及类型,StorageHanlder类路径,配置参数,外部路径,jar名等,修改完成后点击运行脚本,创建该外部表。
然后修改外部表名称,列及类型,StorageHanlder类路径,配置参数,外部路径,jar名等,修改完成后点击运行脚本,创建该外部表。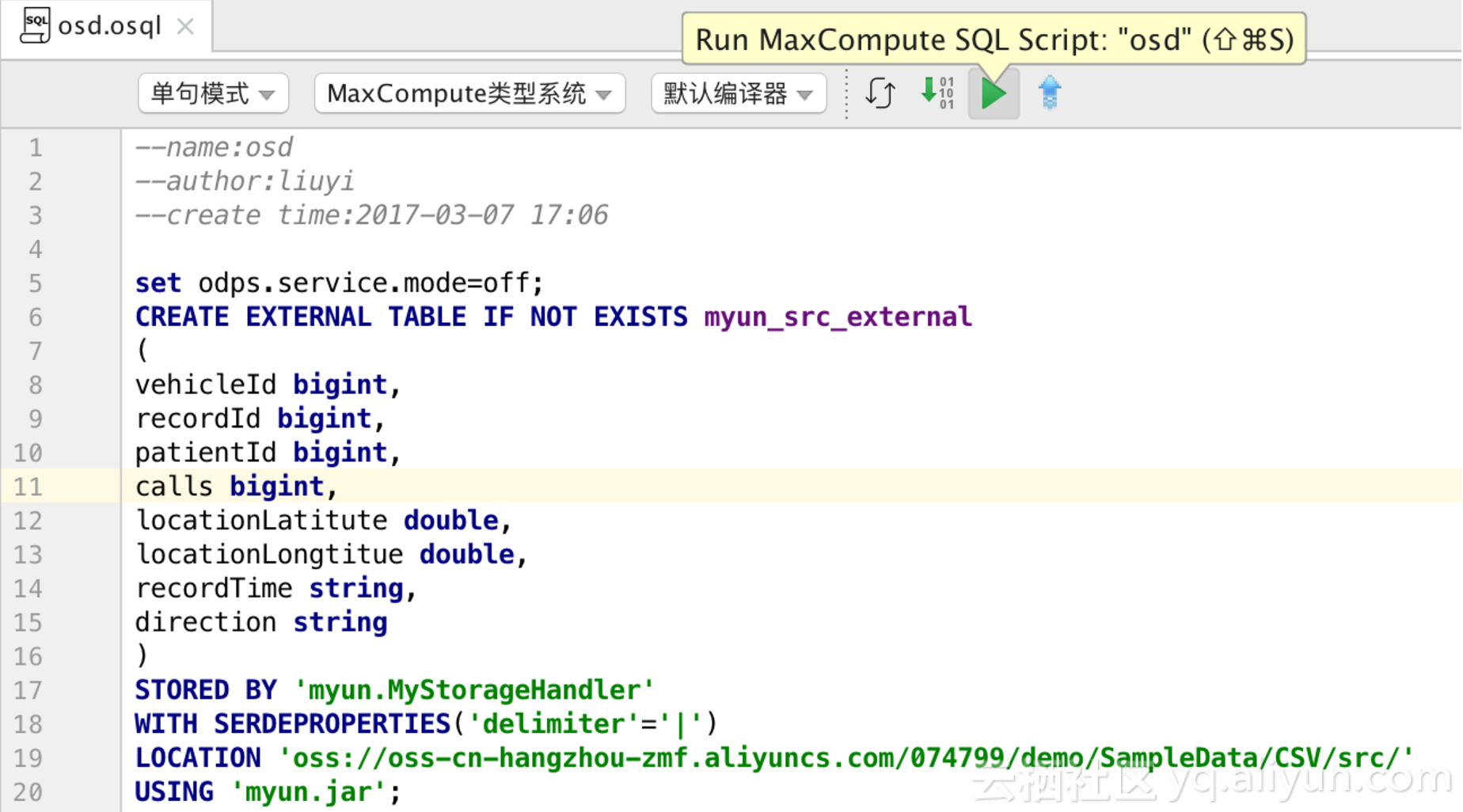

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
MaxCompute 2.0 引入的非结构化数据处理框架极大地增强了对诸如OSS(对象存储服务)、OTS(开放表存储)等阿里云存储服务中非结构化数据的处理能力。通过外部表功能,用户可以直接在MaxCompute中查询和分析这些存储在外部系统中的数据,而无需先将数据导入MaxCompute内部表,这大大提升了数据处理的灵活性和效率。
在阿里云DataWorks(原Data IDE)的Studio中,你可以利用提供的代码模板快速开发这些组件。按照指引创建MaxCompute Java Module,并选择相应的类型(Extractor、Outputter或StorageHandler),Studio会自动生成基础代码框架,你只需在此基础上实现具体的逻辑。
完成编写后,你需要将Java程序打包成JAR文件,并上传至MaxCompute作为资源。这个过程可以通过DataWorks的发布流程或者使用MaxCompute客户端命令行工具来完成。确保你的JAR包包含所有必要的依赖,并且正确设置了访问权限和配置参数。
接下来,在DataWorks Studio中创建MaxCompute SQL脚本,使用预设的live template快速生成创建外部表的SQL语句。在这个脚本中,你需要指定外部表的名称、列定义、使用的StorageHandler类路径、外部数据源的配置参数、外部数据的路径以及之前上传的JAR包名称。执行该脚本后,MaxCompute就会创建一个指向外部数据源的外部表。
一旦外部表创建成功,你就可以像操作普通MaxCompute表一样进行查询了。例如,使用SELECT语句来检索数据,或者执行更复杂的分析任务,如JOIN操作、聚合函数等,从而充分利用MaxCompute强大的计算能力来处理和分析非结构化数据。
综上所述,MaxCompute 2.0的非结构化数据处理框架通过简化外部数据接入、提供丰富的API支持和便捷的开发工具,使得处理大规模非结构化数据变得更加高效和灵活。
