大多数用户对 SQL 的语法并不陌生,简单地说,MaxCompute SQL 就是用于查询和分析 MaxCompute 中的大规模数据。目前 SQL 的主要功能可以概括如下:
支持各类运算符。
通过 DDL 语句对表、分区以及视图进行管理。
通过 Select 语句查询表中的记录,通过 Where 语句过滤表中的记录。
通过 Insert 语句插入数据、更新数据。
通过等值连接 Join 操作,支持两张表的关联。支持多张小表的 mapjoin。
支持通过内置函数和自定义函数来进行计算。
支持正则表达式。
这里只简要介绍 MaxCompute SQL 使用中需要注意的问题,不再做操作示例。
注意:
MaxCompute SQL 不支持事务、索引及 Update/Delete 等操作,同时 MaxCompute 的 SQL语法与 Oracle,MySQL 有一定差别,您无法将其他数据库中的 SQL 语句无缝迁移到 MaxCompute 上来,更多差异请参见 与其他 SQL 语法的差异。
在使用方式上,MaxCompute 作业提交后会有几十秒到数分钟不等的排队调度,所以适合处理跑批作业,一次作业批量处理海量数据,不适合直接对接需要每秒处理几千至数万笔事务的前台业务系统。
关于 SQL 的操作详细示例,请参见 SQL 模块。
DDL语句
简单的 DDL 操作包括创建表、添加分区、查看表和分区信息、修改表、删除表和分区。关于这部分的介绍,请参见
创建/查看/删除表。
Select 语句
group by 语句的 key 可以是输入表的列名,也可以是由输入表的列构成的表达式,不可以是 Select 语句的输出列。
-
select substr(col2, 2) from tbl group by substr(col2, 2); -- 可以,group by的key可以是输入表的列构成的表达式;
- select col2 from tbl group by substr(col2, 2); -- 不可以,group by的key不在select语句的列中;
- select substr(col2, 2) as c from tbl group by c; -- 不可以,group by的key 不可以是列的别名,即select语句的输出列;
有这样的限制是因为:在通常的 SQL 解析中,group by 的操作是先于 Select 操作的,因此 group by 只能接受输入表的列或表达式为 key。
order by 必须与 limit 联用。
sort by 前必须加 distribute by。
order by/sort by/distribute by 的 key 必须是 Select 语句的输出列,即列的别名。如下所示:
-
select col2 as c from tbl order by col2 limit 100 -- 不可以,order by的key不是select语句的输出列,即列的别名
- select col2 from tbl order by col2 limit 100; -- 可以,当select语句的输出列没有别名时,使用列名作为别名。
有这样的限制是因为:在通常的 SQL 解析中, order by/sort by/distribute by 是后于 Select 操作的,因此它们只能接受 Select 语句的输出列为 key。
Insert 语句
向某个分区插入数据时,分区列不可以出现在 Select 列表中。
-
insert overwrite table sale_detail_insert partition (sale_date='2013', region='china')
- select shop_name, customer_id, total_price, sale_date, region from sale_detail;
- -- 报错返回,sale_date, region为分区列,不可以出现在静态分区的 insert 语句中。
动态分区插入时,动态分区列必须在 Select 列表中。
-
insert overwrite table sale_detail_dypart partition (sale_date='2013', region)
- select shop_name,customer_id,total_price from sale_detail;
- --失败返回,动态分区插入时,动态分区列必须在select列表中
Join 操作
MaxCompute SQL 支持的 Join 操作类型包括:{LEFT OUTER|RIGHT OUTER|FULL OUTER|INNER} JOIN。
目前最多支持 16 个并发 Join 操作。
在 mapjoin 中,最多支持 6 张小表的 mapjoin。
Union All
Union All 可以把多个 Select 操作返回的结果,联合成一个数据集。它会返回所有的结果,但是不会执行去重。MaxCompute 不支持直接对顶级的两个查询结果进行 Union 操作,需要写成子查询的形式。
注意:
Union All 连接的两个 Select 查询语句,两个 Select 的列个数、列名称、列类型必须严格一致。如果原名称不一致,可以通过别名设置成相同的名称。
其他
MaxCompute SQL 目前最多支持 128 个并发 Union 操作。
最多支持 128 个并发 insert overwrite/into 操作。
SQL 优化实例
Join 语句中 Where 条件的位置
当两个表进行 Join 操作的时候,主表的 Where 限制可以写在最后,但从表分区限制条件不要写在 Where 条件里,建议写在 ON 条件或者子查询中。主表的分区限制条件可以写在 Where 条件里(最好先用子查询过滤)。
参考下面几个 SQL 语句:
- select * from A join (select * from B where dt=20150301)B on B.id=A.id where A.dt=20150301;
- select * from A join B on B.id=A.id where B.dt=20150301; --不允许
- select * from (select * from A where dt=20150301)A join (select * from B where dt=20150301)B on B.id=A.id;
第二个语句会先 Join,后进行分区裁剪,数据量变大,性能下降。在实际使用过程中,应该尽量避免第二种用法。
数据倾斜
产生数据倾斜的根本原因是:有少数 Worker 处理的数据量远远超过其他 Worker 处理的数据量,从而导致少数 Worker 的运行时长远远超过其他的平均运行时长,进而导致整个任务运行时间超长,造成任务延迟。
更多数据倾斜优化的详情请参见
计算长尾调优。
Join 造成的数据倾斜
造成 Join 数据倾斜的原因是:Join on 的 key 分布不均匀。假设还是上面的例子,现在将大表 A 和一张小表 B 进行 Join 操作,运行如下语句:
- select * from A join B on A.value= B.value;
此时 copy logview 的链接并打开 webcosole 页面,双击执行 Join 操作的 fuxi job 可以看到:此时在 [Long-tails] 区域有长尾,表示数据已经倾斜了。如下图所示:
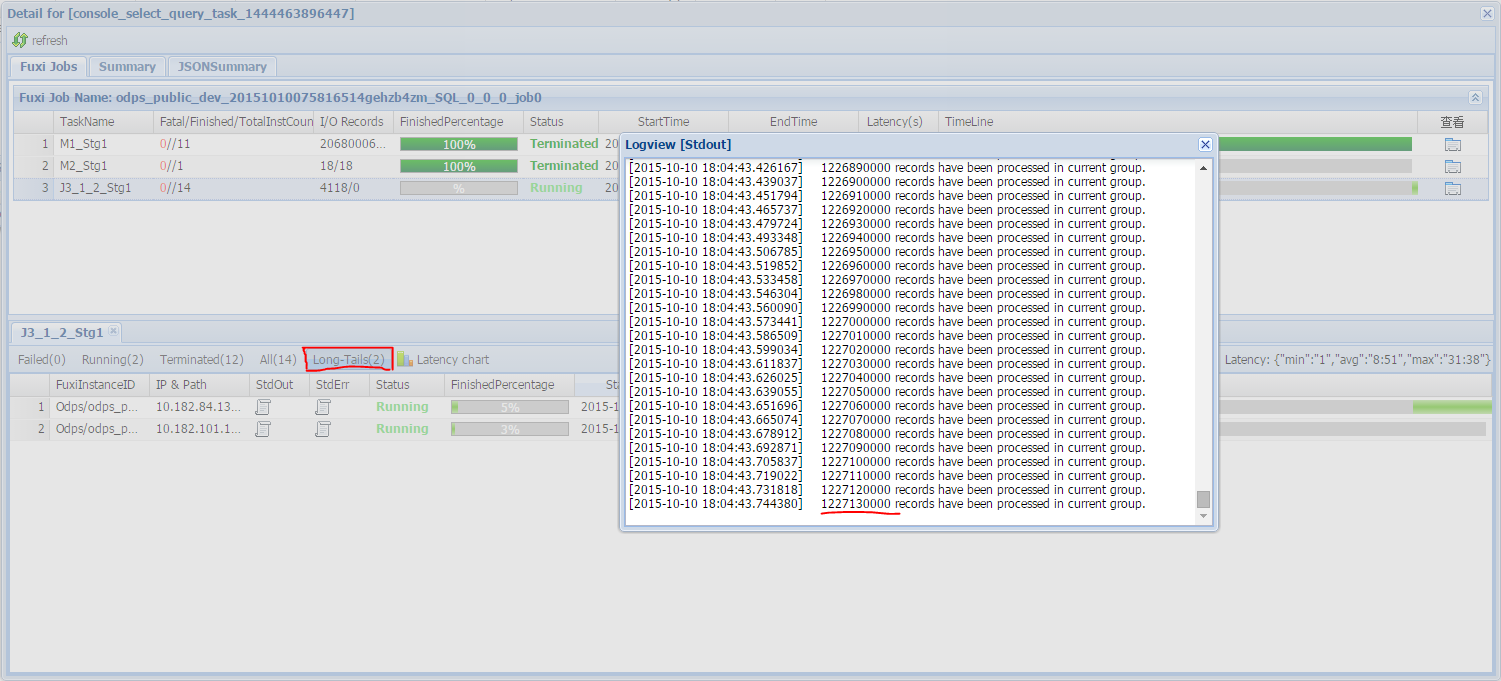
此时可以通过如下方法进行优化:
由于表 B 是个小表并且没有超过 512MB,我们将上面的语句优化成 mapjoin 语句再执行,语句如下:
- select /*+ MAPJOIN(B) */ * from A join B on A.value= B.value;
或者将倾斜的 key 用单独的逻辑来处理,例如经常发生两边的 key 中有大量 null 数据导致了倾斜。则需要在 Join 前先过滤掉 null 的数据或者补上随机数,然后再进行 Join。示例如下:
- select * from A join B
- on case when A.value is null then concat('value',rand() ) else A.value end = B.value;
在实际场景中,如果您知道数据倾斜了,但无法获取导致数据倾斜的 key 信息,那么可以使用一个通用的方案,查看数据倾斜。如下所示:
- 例如:select * from a join b on a.key=b.key; 产生数据倾斜。
- 您可以执行:
- ```sql
- select left.key, left.cnt * right.cnt from
- (select key, count(*) as cnt from a group by key) left
- join
- (select key, count(*) as cnt from b group by key) right
- on left.key=right.key;
查看 key 的分布,可以判断 a join b 时是否会有数据倾斜。
group by 倾斜
造成 group by 倾斜的原因是:group by 的 key 分布不均匀。
假设表A内有两个字段(key, value),表内的数据量足够大,并且 key 的值分布不均,运行语句如下所示:
- select key,count(value) from A group by key;
当表中的数据足够大的时候,您会在 webcosole 页面看见长尾。若想解决这个问题,您需要在执行 SQL 前设置防倾斜的参数,设置语句为set odps.sql.groupby.skewindata=true。
错误使用动态分区造成的数据倾斜
动态分区的 SQL,在 MaxCompute 中会默认增加一个 Reduce,用来将相同分区的数据合并在一起。这样做的好处,如下所示:
减少 MaxCompute 系统产生的小文件,使后续处理更快。
避免一个 Worker 输出文件很多时占用内存过大。
但是也正是因为这个 Reduce 的引入导致分区数据如果有倾斜的话,会发生长尾。因为相同的数据最多只会有 10 个 Worker 处理,所以数据量大,则会发生长尾。
示例如下:
- insert overwrite table A2 partition(dt)
- select
- split_part(value,'\t',1) as field1,
- split_part(value,'\t',2) as field2,
- dt
- from A
- where dt='20151010';
这种情况下,没有必要使用动态分区,所以可以改为如下语句:
- insert overwrite table A2 partition(dt='20151010')
- select
- split_part(value,'\t',1) as field1,
- split_part(value,'\t',2) as field2
- from A
- where dt='20151010';
窗口函数的优化
如果您的 SQL 语句中用到了窗口函数,一般情况下每个窗口函数会形成一个 Reduce 作业。如果窗口函数略多,那么就会消耗资源。在某些特定场景下,窗口函数是可以进行优化的。
窗口函数 over 后面要完全相同,相同的分组和排序条件。
其次,多个窗口函数在同一层 SQL 执行。
符合上述两个条件的窗口函数会合并为一个 Reduce 执行。SQL 示例如下所示:
- select
- rank()over(partition by A order by B desc) as rank,
- row_number()over(partition by A order by B desc) as row_num
- from MyTable;
子查询改 Join
例如有一个子查询,如下所示:
- SELECT * FROM table_a a WHERE a.col1 IN (SELECT col1 FROM table_b b WHERE xxx);
当此语句中的 table_b 子查询返回的 col1 的个数超过 1000 个,系统将会报错如:records returned from subquery exceeded limit of 1000。此时您可以使用 Join 语句来代替,如下所示:
- SELECT a.* FROM table_a a JOIN (SELECT DISTINCT col1 FROM table_b b WHERE xxx) c ON (a.col1 = c.col1)
注意:
如果没用 Distinct,而子查询 c 返回的结果里有相同的 col1 的值,可能会导致 a 表的结果数变多。
因为 Distinct 子句会导致查询全落到一个 Worker 里,如果子查询数据量比较大的话,可能会导致查询比较慢。
如果已经从业务上控制了子查询里的 col1 不可能会重复,比如查的是主键字段,为了提高性能,可以把 Distinct 去掉。

