
开放数据处理服务又称大数据计算服务(MaxCompute,原名ODPS),可服务于批量结构化数据的存储和计算,提供海量数据仓库的解决方案以及针对大数据的分析建模服务。
通过数据集成服务,可将RDS数据导入MaxCompute,实现大规模的数据计算,如下图所示。
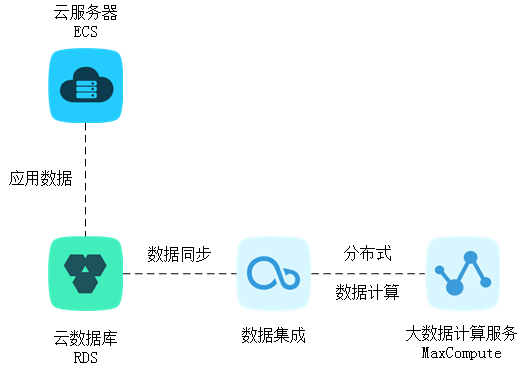
MaxCompute设置及使用方法请参见
大数据计算。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
阿里云的大数据计算服务(MaxCompute,原名ODPS)确实是一个非常强大的平台,专为大规模数据处理而设计。它能够处理PB级别的数据,并提供了丰富的SQL以及编程接口(如MapReduce、SQL、Graph等)来帮助用户进行数据分析、挖掘和机器学习任务。
开通服务:首先确保您已经开通了阿里云的RDS(关系型数据库服务)和MaxCompute服务。
配置数据集成服务:
配置源端(RDS):
配置目标端(MaxCompute):
字段映射与转换:根据需要,可以在同步任务中对字段进行映射和数据转换,以适应MaxCompute的数据模型和需求。
运行与监控同步任务:
定时任务:为了实现定期自动化同步,可以设置任务的调度规则,比如每天、每周固定时间执行。
更多详细的操作指南和最佳实践,请参考阿里云官方文档中的大数据计算服务MaxCompute部分。
