
DataWorks使用MaxCompute分析IP来源最佳实践编写UDF函数?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
DataWorks使用MaxCompute分析IP来源的最佳实践编写UDF函数如下:
import ip2region
def ip_to_location(ip):
with open('ip2region.db', 'rb') as f:
region = ip2region.IP2Region(f)
return region.memory_search(ip)
在DataWorks中创建一个新的UDF任务,选择Python作为编程语言,并将上述代码粘贴到代码编辑器中。
在UDF任务的参数配置中,添加一个输入参数,用于接收需要转换的IP地址。
在UDF任务的返回值配置中,添加一个输出参数,用于返回转换后的地理位置信息。
保存并运行UDF任务,测试其功能是否正常。
在DataWorks的数据集成任务中,使用新创建的UDF函数来分析IP来源。例如,可以在数据源表中添加一个新列,用于存储每个记录的地理位置信息。
SELECT *, ip_to_location(ip) as location FROM your_table;
通过编写Python UDF,将点号分割的IP地址转化为整数类型的IP地址,本示例使用DataWorks的PyODPS完成。详情请参见创建PyODPS 2节点。进入数据开发页面。登录DataWorks控制台。在左侧导航栏,单击工作空间列表。单击相应工作空间后的进入数据开发。新建Python资源。右键单击业务流程,选择新建 > MaxCompute > 资源 > Python。在新建资源对话框中,填写资源名称,并勾选上传为ODPS资源,单击确定。在Python资源中输入如下代码。from odps.udf import annotate@annotate("string->bigint")class ipint(object):def evaluate(self, ip):try:return reduce(lambda x, y: (x << 8) + y, map(int, ip.split('.')))except:return 0单击提交。新建函数。右键单击已创建的业务流程,选择新建 > MaxCompute > 函数。在新建函数对话框中,输入函数名称,单击提交。说明 如果绑定了多个MaxCompute引擎,则需要选择MaxCompute引擎实例。在函数的编辑页面,配置各项参数。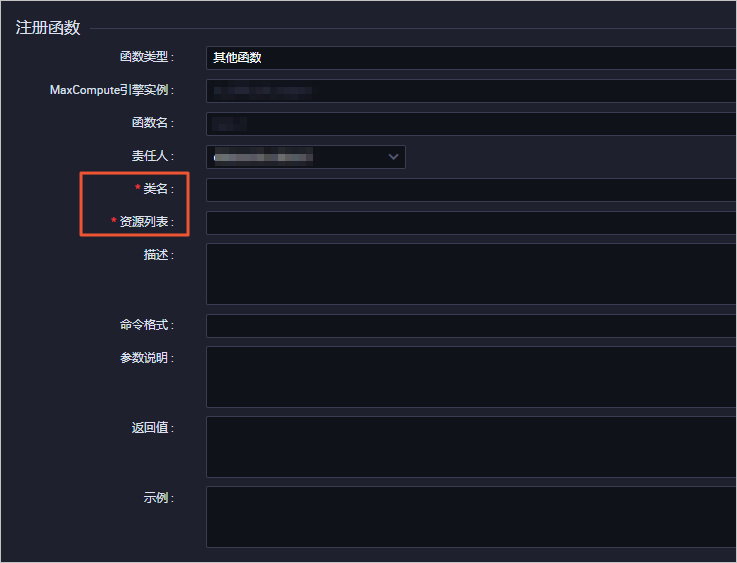
参数 描述
函数类型 选择函数类型,包括数学运算函数、聚合函数、字符串处理函数、日期函数、窗口函数和其他函数。
MaxCompute引擎实例 默认不可以修改。
函数名 UDF函数名,即SQL中引用该函数所使用的名称。需要全局唯一,且注册函数后不支持修改。
责任人 默认显示。
类名 实现UDF的主类名,必填。
资源列表 完整的文件名称,支持模糊匹配查找本工作空间中已添加的资源,必填。 多个文件之间,使用英文逗号(,)分隔。
描述 针对当前UDF作用的简单描述。
命令格式 该UDF的具体使用方法示例,例如test。
参数说明 支持输入的参数类型以及返回参数类型的具体说明。
返回值 返回值,例如1,非必填项。
示例 函数中的示例,非必填项。单击工具栏中的//help-static-aliyun-doc.aliyuncs
https://help.aliyun.com/document_detail/98399.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks中使用MaxCompute分析IP来源的最佳实践编写UDF函数的步骤如下:
在编写UDF代码时,需要注意以下几点:
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


