示例项目
本项目是一个完整的可编译可运行的项目,包括 MapReduce、Pig、Hive 和 Spark 示例代码。请
查看开源项目,详情如下:
[backcolor=transparent]MapReduce
[backcolor=transparent]Hive
[backcolor=transparent]Pig
- sample.pig:Pig 处理 OSS 数据实例。
[backcolor=transparent]Spark
SparkPi: 计算 Pi。
SparkWordCount: 单词统计。
LinearRegression: 线性回归。
OSSSample: OSS 使用示例。
ONSSample: ONS 使用示例。
ODPSSample: ODPS 使用示例。
MNSSample:MNS 使用示例。
LoghubSample:Loghub 使用示例。
依赖资源
[backcolor=transparent]测试数据(data 目录下):
The_Sorrows_of_Young_Werther.txt:可作为 WordCount(MapReduce/Spark)的输入数据。
patterns.txt:WordCount(MapReduce)作业的过滤字符。
u.data:sample.hive 脚本的测试表数据。
abalone:线性回归算法测试数据。
[backcolor=transparent]依赖jar包(lib目录下)
- tutorial.jar:sample.pig作业需要的依赖jar包
准备工作
本项目提供了一些测试数据,您可以简单地将其上传到 OSS 中即可使用。其他示例,例如ODPS、MNS、ONS 和 LogService 等等,需要您自己准备数据如下:
基本概念
OSSURI:oss://accessKeyId:accessKeySecret@bucket.endpoint/a/b/c.txt,用户在作业中指定输入输出数据源时使用,可以类比 hdfs://。
阿里云 AccessKeyId/AccessKeySecret 是您访问阿里云 API 的密钥,您可以在这里获取。
集群运行
Spark
SparkWordCount: spark-submit --class SparkWordCount examples-1.0-SNAPSHOT-shaded.jar <inputPath> <outputPath> <numPartition>
参数说明如下:
inputPath: 输入数据路径。
outputPath: 输出路径。
numPartition: 输入数据 RDD 分片数目。
SparkPi: spark-submit --class SparkPi examples-1.0-SNAPSHOT-shaded.jar
OSSSample:spark-submit --class OSSSample examples-1.0-SNAPSHOT-shaded.jar <inputPath> <numPartition>
参数说明如下:
inputPath: 输入数据路径。
numPartition:输入数据RDD分片数目。
ONSSample: spark-submit --class ONSSample examples-1.0-SNAPSHOT-shaded.jar <accessKeyId> <accessKeySecret> <consumerId> <topic> <subExpression> <parallelism>
参数说明如下:
accessKeyId: 阿里云 AccessKeyId。
accessKeySecret:阿里云 AccessKeySecret。
consumerId: 请参考 Consumer ID 说明。
topic: 每个消息队列都有一个 topic。
subExpression: 参考消息过滤。
parallelism:指定多少个接 收 器来消费队列消息。
ODPSSample: spark-submit --class ODPSSample examples-1.0-SNAPSHOT-shaded.jar <accessKeyId> <accessKeySecret> <envType> <project> <table> <numPartitions>
参数说明如下:
accessKeyId: 阿里云 AccessKeyId。
accessKeySecret:阿里云 AccessKeySecret。
envType: 0 表示公网环境,1 表示内网环境。如果是本地调试选择 0,如果是在 E-MapReduce 上执行请选择 1。
project:请参考ODPS-快速开始。
table:请参考 ODPS 术语介绍。
numPartition:输入数据 RDD 分片数目。
MNSSample: spark-submit --class MNSSample examples-1.0-SNAPSHOT-shaded.jar <queueName> <accessKeyId> <accessKeySecret> <endpoint>
参数说明如下:
queueName:队列名,请参考 MNS 名词解释。
accessKeyId: 阿里云 AccessKeyId。
accessKeySecret:阿里云 AccessKeySecret。
endpoint:队列数据访问地址。
LoghubSample: spark-submit --class LoghubSample examples-1.0-SNAPSHOT-shaded.jar <sls project> <sls logstore> <loghub group name> <sls endpoint> <access key id> <access key secret> <batch interval seconds>
参数说明如下:
sls project: LogService 项目名。
sls logstore:日志库名。
loghub group name:作业中消费日志数据的组名,可以任意取。sls project 和 sls store 相同时,相同组名的作业会协同消费 sls store 中的数据;不同组名的作业会相互隔离地消费 sls store 中的数据。
sls endpoint: 请参考日志服务入口。
accessKeyId: 阿里云 AccessKeyId。
accessKeySecret:阿里云 AccessKeySecret。
batch interval seconds: Spark Streaming 作业的批次间隔,单位为秒。
LinearRegression: spark-submit --class LinearRegression examples-1.0-SNAPSHOT-shaded.jar <inputPath> <numPartitions>
参数说明如下:
inputPath:输入数据。
numPartition:输入数据 RDD 分片数目。
Mapreduce
WordCount: hadoop jar examples-1.0-SNAPSHOT-shaded.jar WordCount -Dwordcount.case.sensitive=true <inputPath> <outputPath> -skip <patternPath>
参数说明如下:
inputPathl:输入数据路径。
outputPath:输出路径。
patternPath:过滤字符文件,可以使用 data/patterns.txt。
Hive
hive -f sample.hive -hiveconf inputPath=<inputPath>
参数说明如下:inputPath:输入数据路径。
Pig
pig -x mapreduce -f sample.pig -param tutorial=<tutorialJarPath> -param input=<inputPath> -param result=<resultPath>
参数说明如下:
tutorialJarPath:依赖 Jar 包,可使用 lib/tutorial.jar。
inputPath:输入数据路径。
resultPath:输出路径。
注意:
- [backcolor=transparent]-[backcolor=transparent] [backcolor=transparent]在[backcolor=transparent] E[backcolor=transparent]-[backcolor=transparent]MapReduce[backcolor=transparent] [backcolor=transparent]上使用时,请将测试数据和依赖[backcolor=transparent] jar [backcolor=transparent]包上传到[backcolor=transparent] OSS [backcolor=transparent]中,路径规则遵循[backcolor=transparent] OSSURI [backcolor=transparent]定义,见上。
- [backcolor=transparent]-[backcolor=transparent] [backcolor=transparent]如果集群中使用,可以放在机器本地。
本地运行
这里主要介绍如何在本地运行 Spark 程序访问阿里云数据源,例如 OSS 等。如果希望本地调试运行,最好借助一些开发工具,例如 Intellij IDEA 或者 Eclipse,尤其是对于 Windows环境,否则需要在 Windows 机器上配置 Hadoop 和 Spark 运行环境。
Intellij IDEA
准备工作
安装Intellij IDEA,Maven, Intellij IDEA Maven插件,Scala,Intellij IDEA Scala插件。
开发流程
双击进入 SparkWordCount.scala。
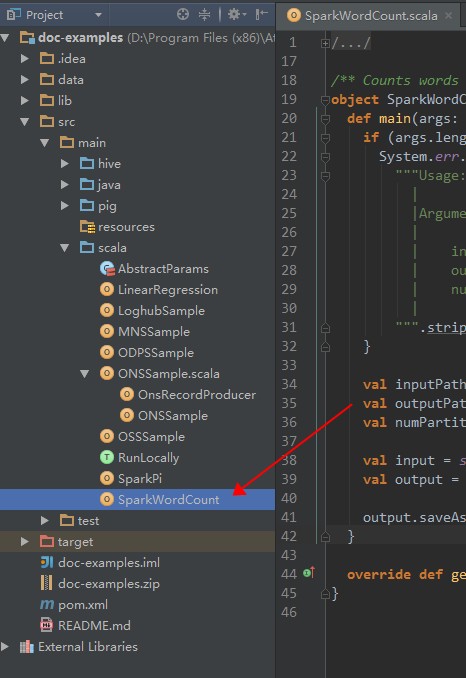
从下图箭头所指处进入作业配置界面。
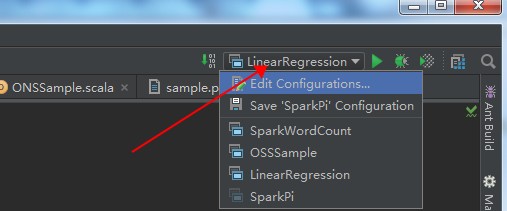
选择 SparkWordCount,在作业参数框中按照所需传入作业参数。

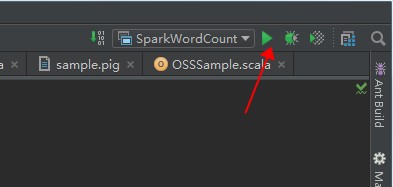
点击 [backcolor=transparent]OK。
点击[backcolor=transparent]运行按钮,执行作业。
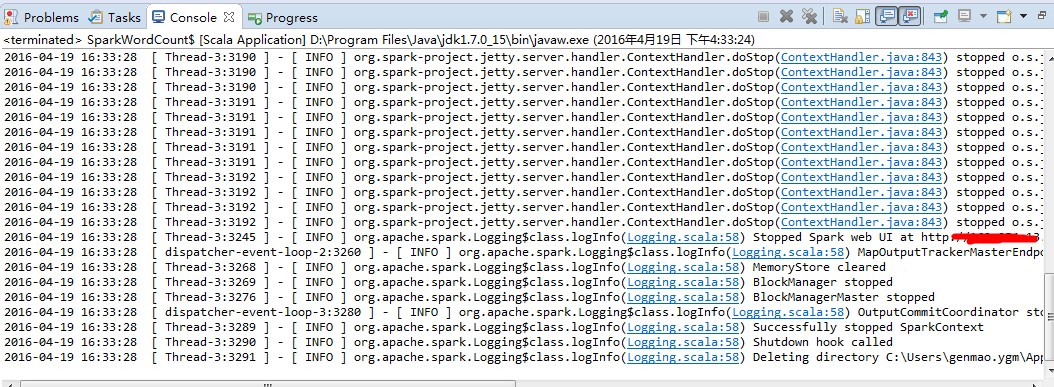
查看作业执行日志
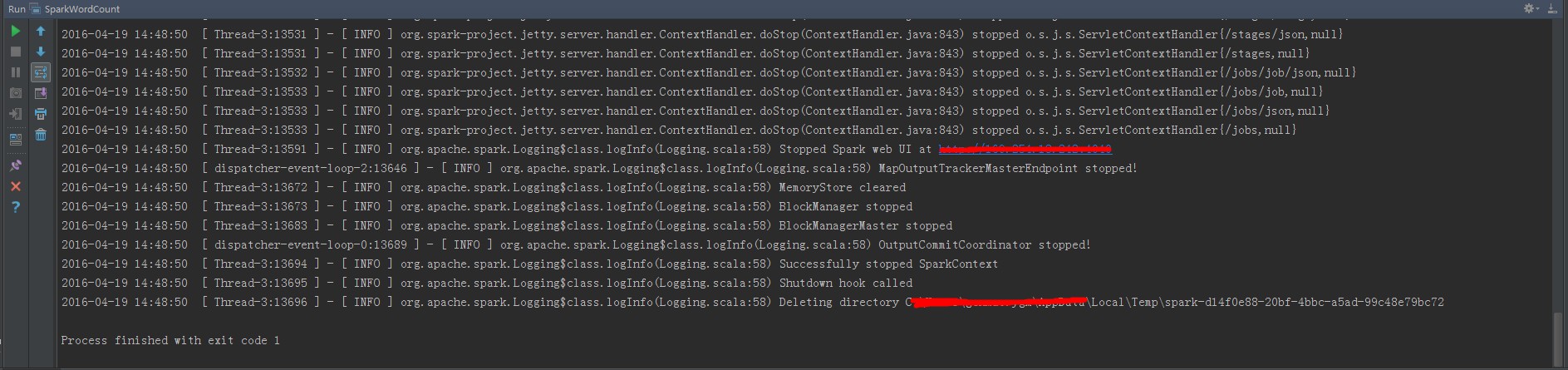
Scala IDE for Eclipse
准备工作
安装 Scala IDE for Eclipse、Maven、Eclipse Maven 插件。
开发流程
请根据以下图示导入项目。
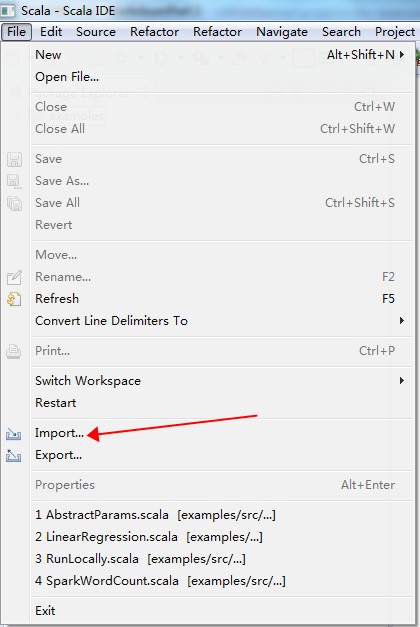
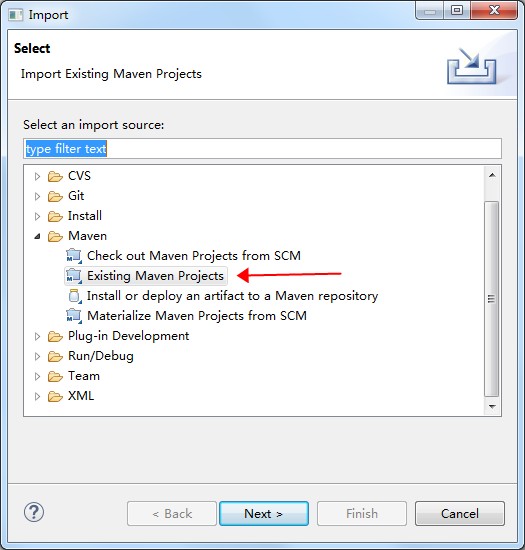
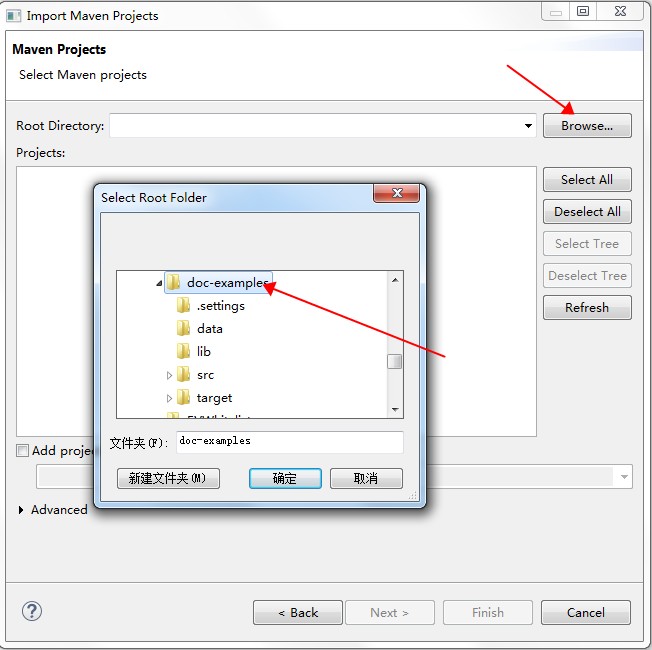
Run As Maven build,快捷键是“Alt + Shilft + X, M”;也可以在项目名上右键,“Run As”选择“Maven build”。
等待编译完后,在需要运行的作业上右键,选择“Run Configuration”,进入配置页。
在配置页中,选择 Scala Application,并配置作业的 Main Class 和参数等等。如下图所示:
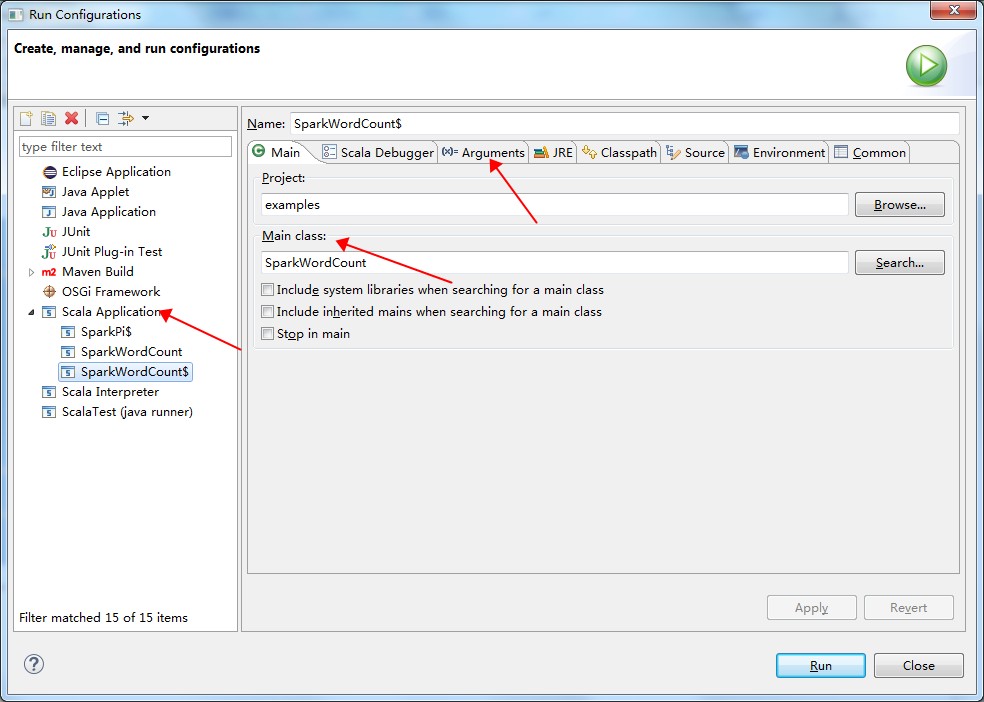
点击“Run”。
查看控制台输出日志,如下图所示: