
1.协同过滤算法
协同过滤(Collaborative Filtering)是推荐领域比较经典的一个算法。
所谓协同过滤就是,根据用户的喜好或者近期的行为以及志趣相同的用户的爱好来给用户进行推荐物品,目前应用比较广泛的协同过滤算法有两种模式,一种是基于邻域(neighborhood methods),另外一种就是隐语义模型(latent factor models),对于邻域这种方法主要为以下两种方法:
- 基于用户的协同过滤算法(UserCF):将兴趣相同的用户群体聚类,然后为用户推荐与自己兴趣相同的用户喜欢的产品,比如A和B的兴趣相同,都喜欢运动,如果A喜欢羽毛球,那么我们猜测B也会喜欢羽毛球,所以向B推荐羽毛球
- 基于物品的协同过滤算法(ItemCF):为用户推荐和他近期喜欢的物品相似的物品,比如A近期疯狂买了些学习用品,那么我们猜测A进去想要进行学习,所以我们计算与A近期买的学习用品相似的产品,然后为其推荐
两种算法不同的地方就是UserCF是计算用户之间的相似度,而ItemCF是要计算物品与物品之间的相似度。
既然要计算相似度,那么就需要定义衡量相似度的指标,用来描述物品与物品,用户与用户之间的相似度。
2.相似性度量方法
2.1 杰卡德(Jaccard)相似系数
这个是用来衡量两个集合相似度的一种指标。Jaccard相似系数就是两个用户A和B产生交集的物品数量占两个用户所有物品并集的比例。
很好理解如果两个人购买的物品交集越多说明两个人的购买欲望相同,两个人的兴趣爱好就越相同。
其中,
2.2 余弦相似度
在几何中,我们衡量两个向量是否相似就是看两个向量之间的夹角,如果夹角越小则说明两个向量越接近,其实它和Jaccard公式就是差个分母,Jaccard的分母是用户物品的并集,而余弦相似度就是物品数量的乘积,公式如下(该公式是针对集合来说):
但是这种度量方法与局限性,一般我们的数据都是结构化数据,都是二维表格进行表示,而每行或者每列都是一个向量,所以大多数情况我们都是使用向量公式进行度量,计算不同向量之间的相似度,而不是集合,公式如下:
分子为两个向量的内积,分母是两个向量模长的乘积。
但是一般情况下我们的数据会非常多,会导致数据矩阵非常稀疏,导致向量中的0特别多,所以当数据量特别大的时候才会选择集合的方式进行度量,数据不多的情况就可以使用向量形式进行度量。
from sklearn.metrics.pairwise import cosine_similarity
cosine_similarity(np.random.rand(3,5))
>>>
array([[1. , 0.60668189, 0.64782216],
[0.60668189, 1. , 0.77366842],
[0.64782216, 0.77366842, 1. ]])
2.3 皮尔逊相关系数
皮尔逊相关系数就是我们概率统计中学过的相关系数,取值为【-1,1】,越接近1越是正相关,越接近-1越是负相关,如果为0,则表明二者不相关。
其实皮尔逊相关系数的计算方法与余弦相似度的计算方式很相似,我们把上面的余弦相似度公式写成求和形式:
其中
皮尔逊相关系数的公式为:
其中
np.corrcoef(np.random.rand(3,5))
>>>
array([[1. , 0.3614897 , 0.80524819],
[0.3614897 , 1. , 0.84032913],
[0.80524819, 0.84032913, 1. ]])
3.基于用户的协同过滤(UserCF)
基于用户的协同过滤算法的思想就是,当我们需要对A进行推荐物品的时候,我们会找到与A兴趣爱好相同的用户,然后把这些用户喜欢的物品推荐给A用户。
UserCF算法可以说主要有两大步骤:
- 找到与用户A兴趣爱好相同的用户群体
- 将该群体用户喜欢的物品推荐给A
其实第一步很容易,就是基于相似度进行计算不同用户之间的相似程度,找到与目标用户最相似的前n个用户群体。
那么第二步怎么弄呢?我们现在已经找到了用户群体,然后我们会将该群体喜欢的物品推荐给A,那么我们怎么衡量用户A对推荐物品的喜爱程度呢?说白了就是我们不能将这个群体所有的物品都推荐,数量太多,那么如果找到A之前未见过,而且它喜欢的物品呢,那么肯定是要给这个物品进行打分的。
比如用户A没有买过物品1,但是与A兴趣相近的用户B和C都买了物品1,而且都会物品1打了分,现在如何衡量用户A对物品1的喜爱程度呢?
在一定程度,我们可以将B和C对物品1的得分进行加权作为A对物品1的得分,然后最终将所有物品的评分进行排序,然后推荐分数最高的物品。
UserCF算法两个步骤:
- 首先根据user-item表的打分情况,计算目标用户和其余用户的相似度,找到与目标用户最相似的前n个用户。
- 根据这n个用户对物品5的评分情况与目标用户的相似度猜测目标用户对物品5的评分,如果评分最终很高,就把这个物品推荐给A,否则不推荐。
那么现在的问题就是如何计算这个最终得分。
方式一:利用用户相似度和相似用户的评分进行加权获得最终评分
上式中的
方式二:基于评分差值进行加权
但是这样是会存在问题的,就是不同用户的评分标准不一样,有的人天生会打高分,尽管对于有些物品不喜欢,但是他们仍给较高的分数,会导致分数差较低,有的人打的分很低,这样就会导致结果不准确,解决策略就是用不同物品打分与物品均值的差,因为这样就不会产生分数高低的影响,使用的是每个人的分数差,即使一个人经常打高分,我们使用的是分数与均值的差,这样就不会与其它低分用户造成影响。
上式中的
在获得用户u对不同物品的得分后,最终的推荐列表会根据用户u对不同物品的评分得到,然后去前n个分数高的物品进行推荐。
4.UserCF编程实现
为了更好理解UserCF思想,这里做了一个微型版的UserCF推荐系统。
UserCF主要为以下几个步骤:
- 加载数据
- 计算不同用户之间的相似度
- .计算前n个相似的用户
- .计算对待推荐物品的得分
- .对待推荐物品评分进行排序
- .按照分数高低进行推荐
"""
1.加载数据
2.计算不同用户之间的相似度
3.计算前n个相似的用户
4.计算对待推荐物品的得分
5.对待推荐物品评分进行排序
6.按照分数高低进行推荐
"""
1. 加载数据
这里采用字典进行保存数据,原因是在真实情况,不是所有的物品都会被不同的用户打分,如果采用向量进行表示的化,一般就是稀疏数组,或者会有大量的空值,所以这里采用字典进行映射用于与物品之间的关系。
数据类型为字典,对于item来说,键为不同的物品,值同样为一个字典,里面保存不同用户对该物品的评分,对于用户表同理。
"""1.加载数据"""
items = {
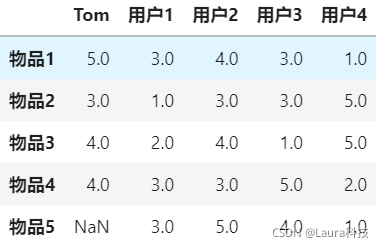
"物品1":{"Tom":5,"用户1":3,"用户2":4,"用户3":3,"用户4":1},
"物品2":{"Tom":3,"用户1":1,"用户2":3,"用户3":3,"用户4":5},
"物品3":{"Tom":4,"用户1":2,"用户2":4,"用户3":1,"用户4":5},
"物品4":{"Tom":4,"用户1":3,"用户2":3,"用户3":5,"用户4":2},
"物品5":{ "用户1":3,"用户2":5,"用户3":4,"用户4":1},
}
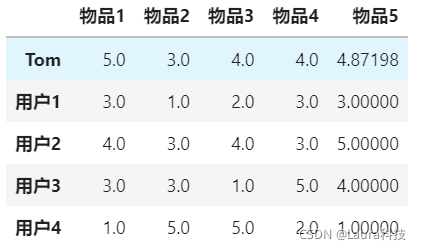
users = {
"Tom":{"物品1":5,"物品2":3,"物品3":4,"物品4":4},
"用户1":{"物品1":3,"物品2":1,"物品3":2,"物品4":3,"物品5":3},
"用户2":{"物品1":4,"物品2":3,"物品3":4,"物品4":3,"物品5":5},
"用户3":{"物品1":3,"物品2":3,"物品3":1,"物品4":5,"物品5":4},
"用户4":{"物品1":1,"物品2":5,"物品3":5,"物品4":2,"物品5":1},
}
item_df = pd.DataFrame(items).T
user_df = pd.DataFrame(users).T
2. 计算不同用户之间的相似度
这里计算用户相似度的方式为皮尔逊相关系数,这里需要三次遍历,第一次是遍历用户,第二次遍历是遍历与第一次不同的用户,因为我们要计算不同用户之间的相似度,第三次遍历是要遍历物品,这里需要注意,我们计算相似度要计算该物品同时被两个用户打分,否则无法计算,所以遍历物品是需要判断两个用户是否在物品字典中。
"""2.计算不同用户之间的相似度"""
# 用来保存不同用户之间的相似度
similarity_matrix = pd.DataFrame(np.zeros((len(users),len(users))),
index=["Tom","用户1","用户2","用户3","用户4"],
columns=["Tom","用户1","用户2","用户3","用户4"])
for userID in users:
for anotherID in users:
list_user = []
list_another = []
if userID != anotherID:
for itemID in items:
itemRatings = items[itemID]
if userID in itemRatings and anotherID in itemRatings:
list_user.append(itemRatings[userID])
list_another.append(itemRatings[anotherID])
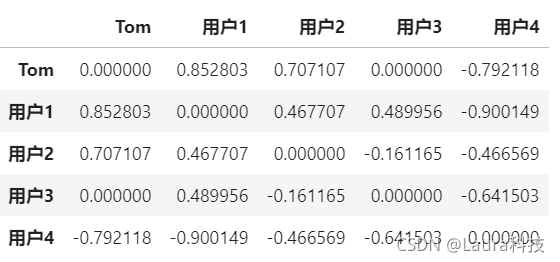
similarity_matrix[userID][anotherID] = np.corrcoef(np.array(list_user),np.array(list_another))[0][1]
similarity_matrix
3. 计算前n个相似的用户
然后我们根据上一步计算好的用户之间的相似度找到与目标用户最接近的n个用户群体。
"""3.计算前n个相似的用户"""
n = 2
# 这里的["Tom"]是取列
similarity_users = similarity_matrix["Tom"].sort_values(ascending=False)[:n].index.tolist()
similarity_users
>>>
['用户1', '用户2']
4. 计算对待推荐物品的得分
这里采用的公式为:
"""4.计算对待推荐物品的得分"""
base_score = user_df.iloc[0, :4].mean() # 除了物品5的平均分
weight_scores = 0. # 权重得分,即不同用户之间的相似度 * (各用户物品5的评分-其余物品得分的均值)
corr_values_sum = 0. # 权重系数之和,即分母,用于归一化
for user in similarity_users:
corr_value = similarity_matrix["Tom"][user]
mean_user_score = user_df.loc[user].values.mean()
weight_scores += corr_value * (users[user]["物品5"] - mean_user_score)
corr_values_sum += corr_value
final_scores = base_score + weight_scores / corr_values_sum
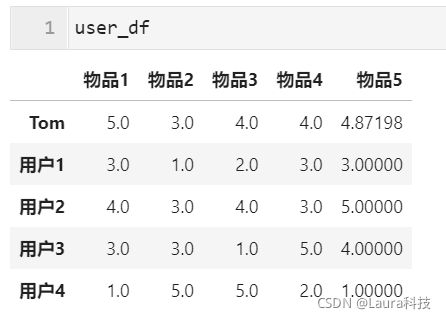
print("用户Tom对物品5的打分:", final_scores)
user_df["物品5"]["Tom"] = final_scores
>>>
用户Tom对物品5的打分: 4.871979899370592
5.对待推荐物品评分进行排序
计算好待推荐物品的最终得分后,需要对这些物品的得分进行排序,用于最终推荐
"""5.对待推荐物品评分进行排序"""
ratings = dict(user_df.iloc[0,:].sort_values(ascending=False))
ratings
>>>
{'物品1': 5.0, '物品5': 4.871979899370592, '物品4': 4.0, '物品3': 4.0, '物品2': 3.0}
6. 按照分数高低进行推荐
这一步不用多说,挑选出分数最高的前n个物品进行推荐
"""6.按照分数高低进行推荐"""
n = 3
recommendation_list = list(ratings)[: n]
recommendation_list
>>>
['物品1', '物品5', '物品4']





