
引言
不知道你是否和我有过同样的感受,《计算机组成原理》这门学科学起来如此的艰难:一节课下来,教室黑板上留下了满满的 “足迹”,看上去也挺简单的,不就是 0 和 1 嘛。但这些看起来简简单单的 0 1 码却成为了我当时学习路上的绊脚石。源码、反码、补码等等等等,各种的码制转换令我一头雾水,我曾一度怀疑这就是计算机干的活儿吗?
随着后面慢慢了解《计算机组成原理》后,我愿称计算机为世界上最麻烦的电子产品。也形象的将计算机描述为一套有电源、有身体、有框架,但就是没有思想的空壳儿。这时候,我们的人类社会才萌生了许许多多“ 利用 ”它们的主人—程序“ 猿 ”。
程序员就是要为计算机这个富有 ” 聪明 “潜质的伙伴编写一套一套的 “程序” ,告诉它们应该去做什么亦或是怎么去做。正是由于它们能吃苦、不怕累的精神再加上完美程序的契合,我们的生活质量得以大幅度提升。

即使你不是计算机专业的学生,相信对于CPU你也有所了解。正所谓CPU(Central Processing Unit),也就是中央处理器。负责解释计算机指令以及处理计算机软件中的数据。中央处理器主要包含控制器、运算器两部分,其中还包括cache以及实现它们之间信息互换的数据、总线。
可千万别小看这个不起眼的 “小东西” ,它可是程序执行、机器正常运转必不可少的元器件。作为电子计算机三大核心部件(CPU、内存、I/O设备)之一的CPU,在计算机体系结构中承载着控制调配硬件资源、执行通用运算等重要职责。下面我们来了解较为简单的单周期CPU功能指令。
上机实验
分析实现单周期CPU的14条指令计算结果,比较理论与实践结果的正确性。
Addi:
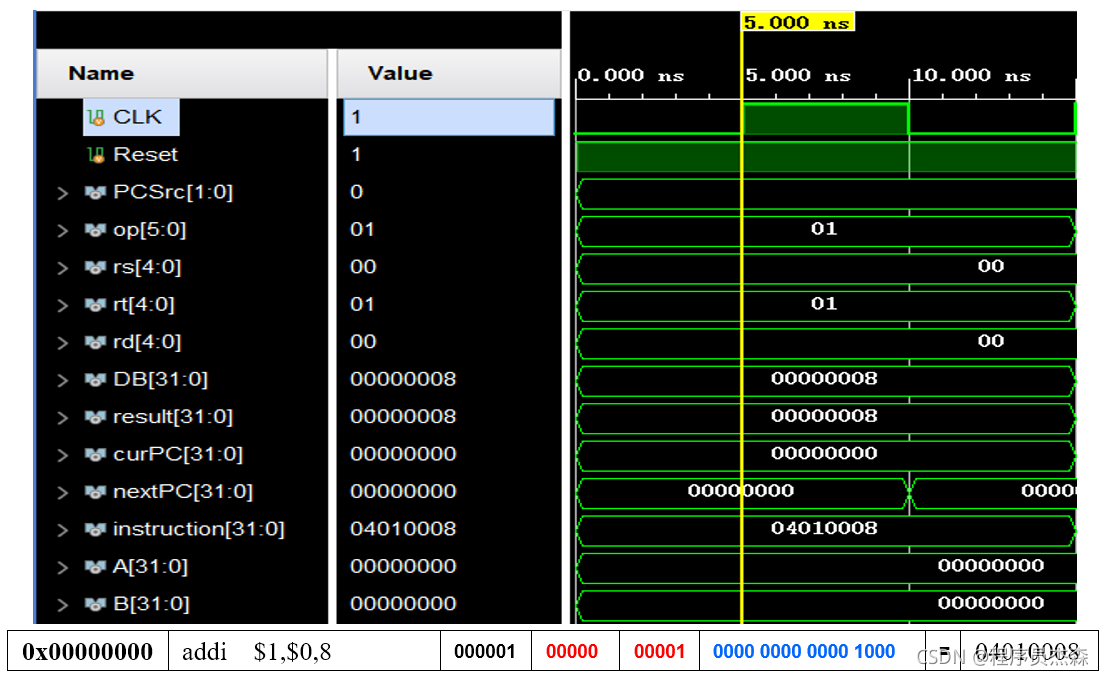 分析第一个周期,指令地址为041008,在程序测试段中,可以看到,本条指令为addi,那么现在开始检验指令addi的实现过程:指令addi的功能是rt←rs + (sign-extend)immediate; immediate符号扩展再参加“加”运算。
分析第一个周期,指令地址为041008,在程序测试段中,可以看到,本条指令为addi,那么现在开始检验指令addi的实现过程:指令addi的功能是rt←rs + (sign-extend)immediate; immediate符号扩展再参加“加”运算。
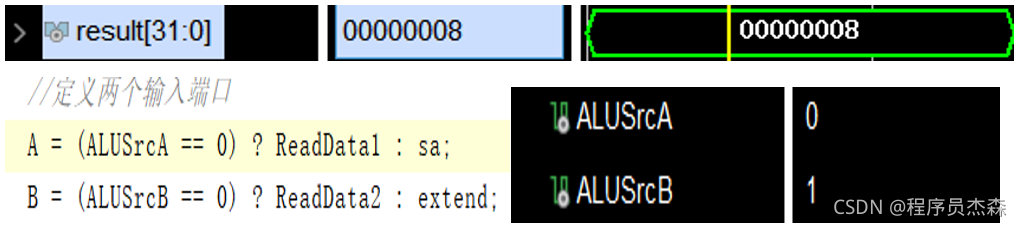
首先找到rs在本周期中存放的源操作数地址,rs=00;然后在Objects中添加immediate组件,找到立即数的值,immediate=8;最后进入ALU分析计算结果,在ALU的代码文件中有两个引脚,ALUSrcA和ALUSrcB,它们在第一个周期中的值分别是0和1,则A端口进行ReadData1,B端口进行extend,计算结果为result=8,指令执行正确,可以实现数据相加功能。
Ori:
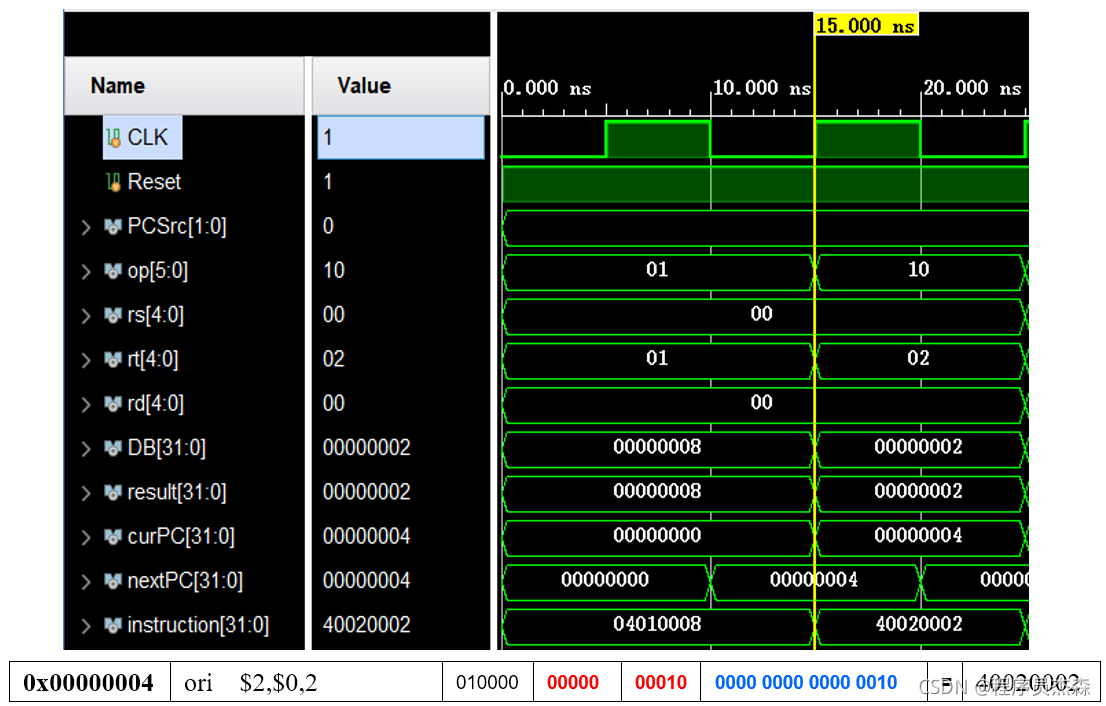
分析第二个周期,指令地址为40020002,在程序测试段中,可以看到,本条指令为ori,那么现在开始检验指令ori的实现过程:指令ori的功能是rt←rs | (zero-extend)immediate; immediate符号扩展再参加“或”运算。寄存器源操作数地址:rs=0,immediate=2;
进行zero-extend后,值为2

进行“或”运算,ALU两个引脚输入端口值为

计算结果为
 指令计算结果无误,指令运行正常。
指令计算结果无误,指令运行正常。
Add:
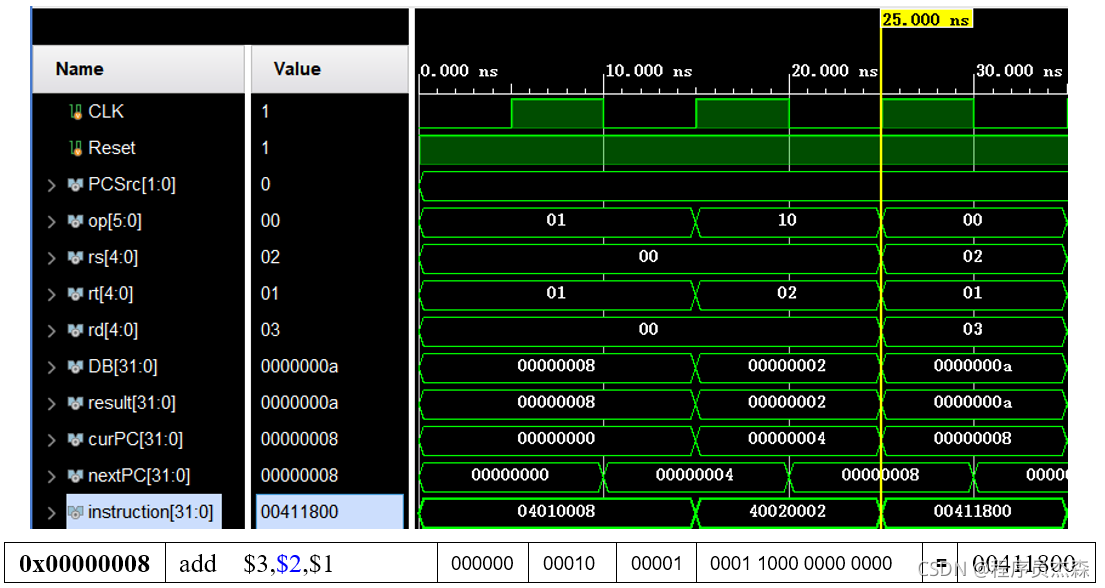
分析第三个周期,指令地址为0411800,在程序测试段中,可以看到,本条指令为add,那么现在开始检验指令add的实现过程:指令add的功能是rd←rs + rt。源操作数地址:rs=2,rt=1;ALU两个引脚值都是0,读寄存器中的值,此时存入结果为03,程序运行正常,功能实现。

Sub:
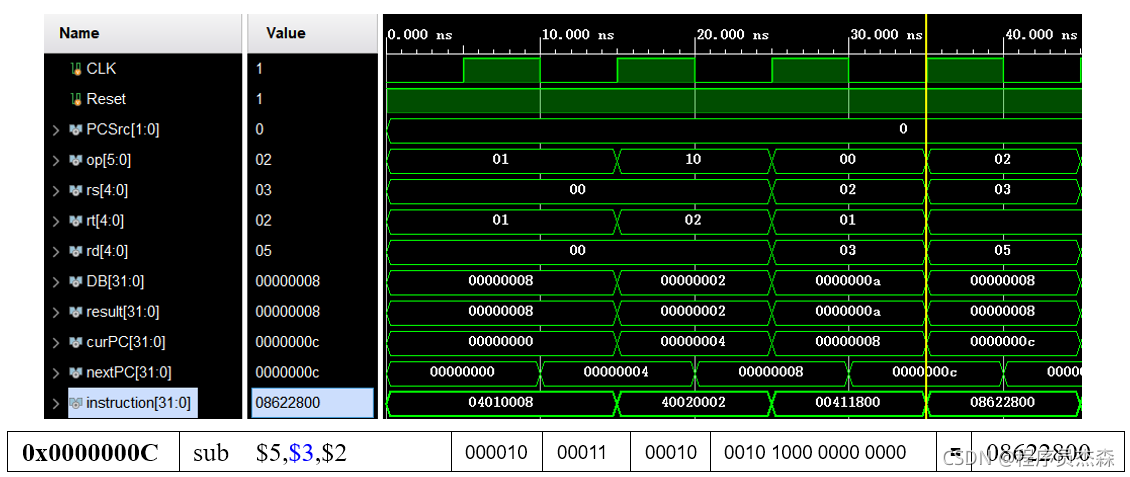 分析第四个周期,指令地址为08622800,在程序测试段中,可以看到,本条指令为sub,那么现在开始检验指令sub的实现过程:指令sub的功能是rd←rs - rt。源操作数地址:rs=3,rt=2;ALU两个引脚值皆为0,程序读取寄存器中的值,此时存入结果为5,程序运行正常,功能完好。
分析第四个周期,指令地址为08622800,在程序测试段中,可以看到,本条指令为sub,那么现在开始检验指令sub的实现过程:指令sub的功能是rd←rs - rt。源操作数地址:rs=3,rt=2;ALU两个引脚值皆为0,程序读取寄存器中的值,此时存入结果为5,程序运行正常,功能完好。

and:
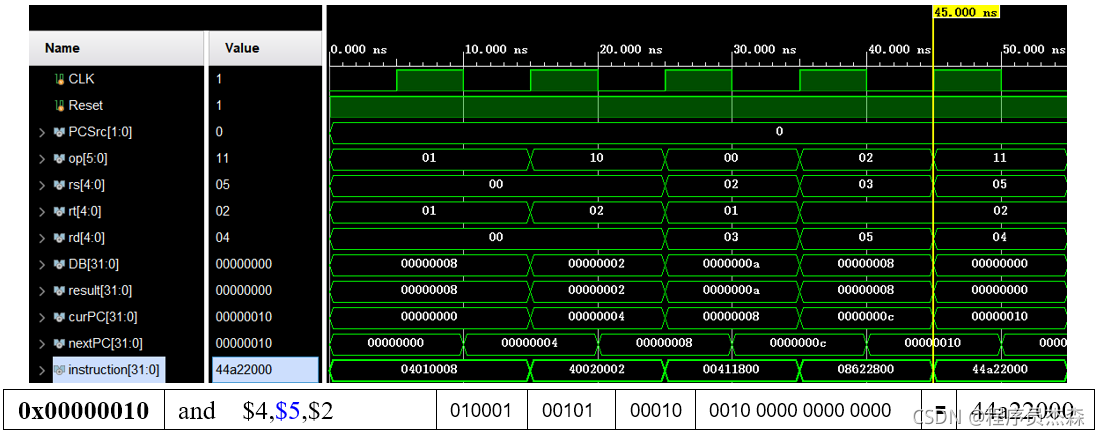
分析第五个周期,指令地址为44a22000,在程序测试段中,可以看到,本条指令为and,那么现在开始检验指令and的实现过程:指令and的功能是rd←rs & rt;(逻辑与运算)。源操作数寄存器地址:rs=5,rt=2;ALU引脚值为0,读取ALU计算结果为00000000,分别对源操作数5和2转为2进制为:0101、0010按位与后值为0,结果吻合,该单元工作正常,功能实现。
or:
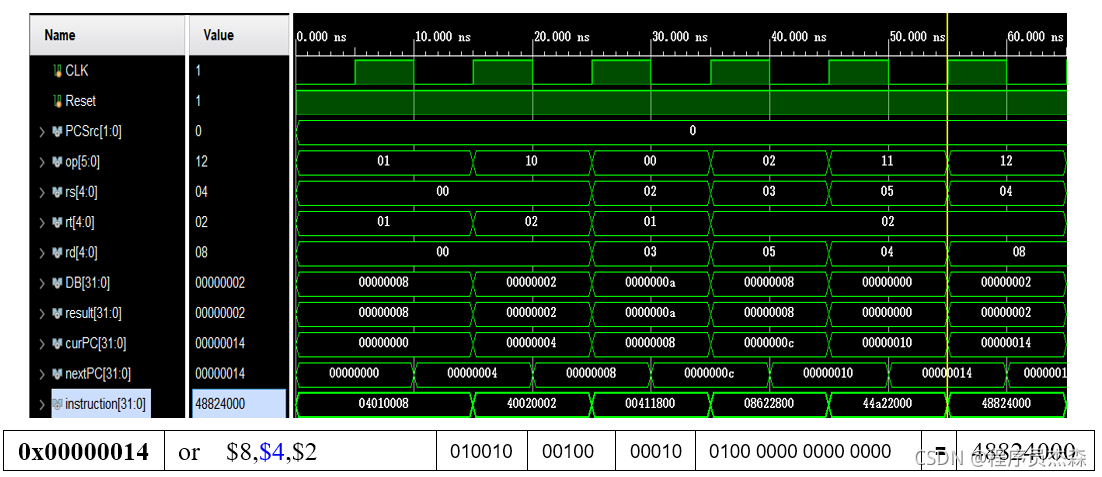
分析第六个周期,指令地址为48824000,在程序测试段中,可以看到,本条指令为or,那么现在开始检验指令or的实现过程:指令or的功能是rd←rs | rt;(逻辑或运算)。源操作数寄存器地址:rs=04,rt=02;ALU双引脚值为0,读取寄存器堆中的值,可以看到存放真值为0和2(取最后结果)。读取值为2。
分别对源操作数4和2转为2进制并按位或后值为2,与程序运行结果吻合,该单元工作正常,功能实现。

sll:
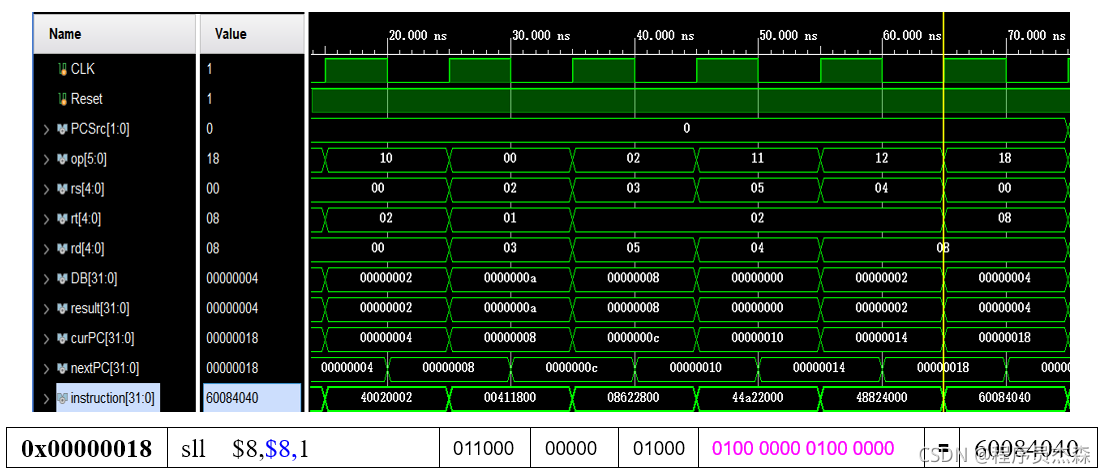
分析第七个周期,指令地址为60084040,在程序测试段中,可以看到,本条指令为sll,那么现在开始检验指令sll的实现过程:指令sll的功能是rd<-rt<<(zero-extend)sa,左移sa位 ,(zero-extend)sa。源操作数寄存器地址:rt=08 ,寻求真值,移位数sa=1,程序运行后 。在二进制数据计算中,左移一位就相当于乘以2,故程序结果正确,该单元工作正常。
bne:
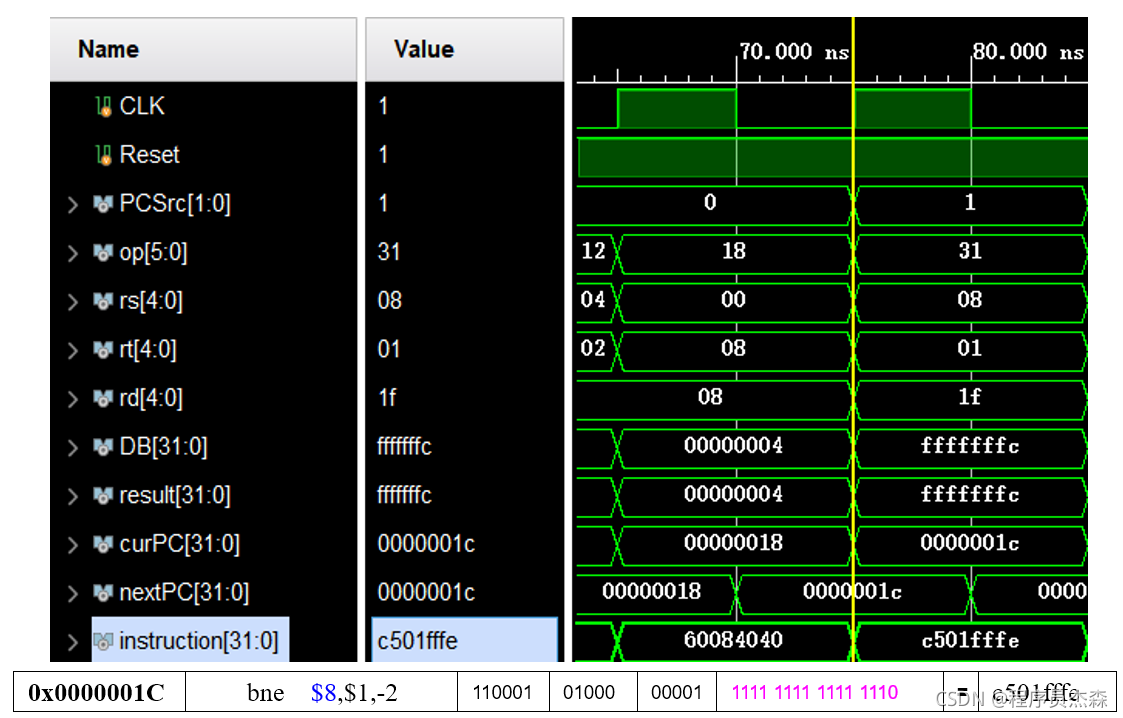
分析第八个周期,指令地址为c501fffe,在程序测试段中,可以看到,本条指令为bne,那么现在开始检验指令bne的实现过程:指令bne的功能是:if(rs!=rt) pc←pc + 4 + (sign-extend)immediate <<2 else pc ←pc + 4【与beq不同:不等时转移,相等时顺序执行。】在寄存器堆中找到源操作数地址,寻得真值,找寻计算结果,结果吻合,单元工作正常。

slti:
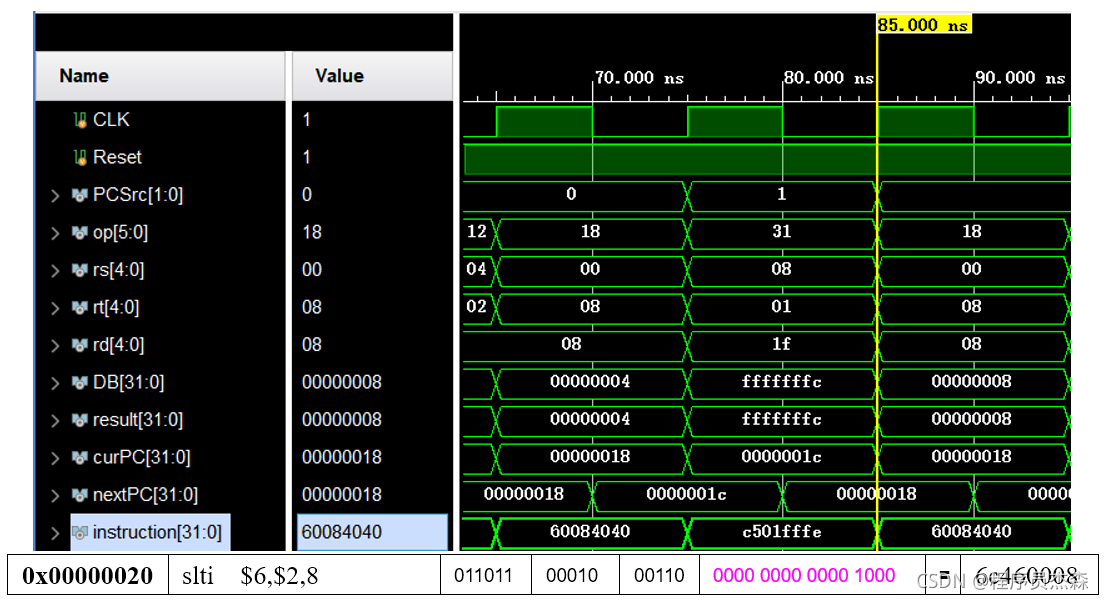
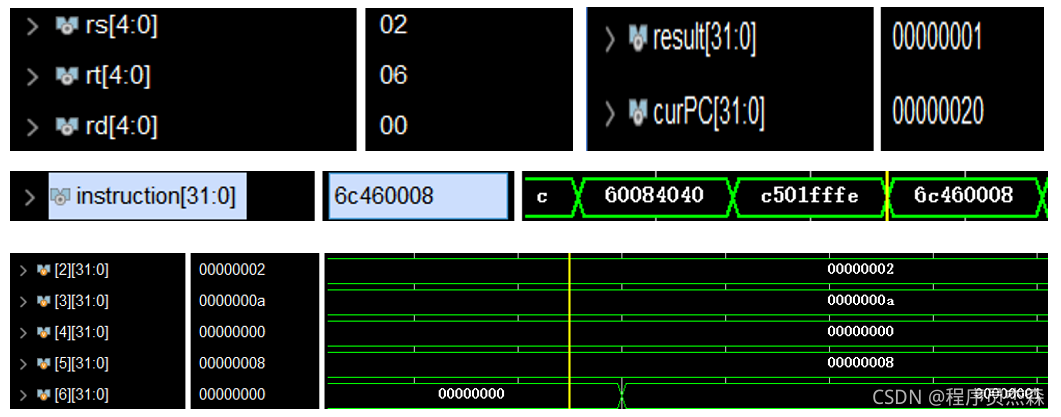
分析第九个周期,指令地址为6c460008,在程序测试段中,可以看到,本条指令为slti,那么现在开始检验指令slti的实现过程:指令slti的功能是:if (rs <(sign-extend)immediate) rt =1 else rt=0,源操作数地址找到后,对立即数进行sign-extend,然后判断是否满足if()中的给定条件,程序结果完整无误,本单元工作正常。
beq:
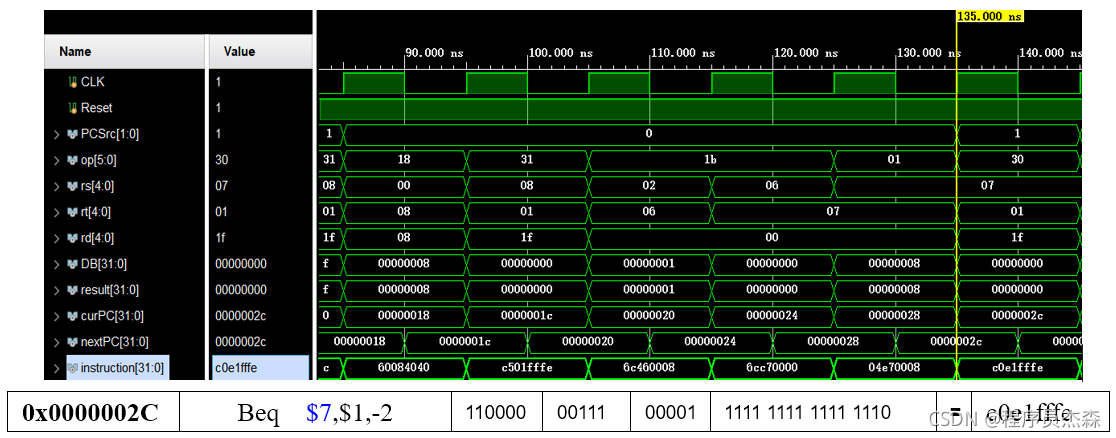
第14个周期中,指令地址为c0e1fffe,在程序测试段中,可以看到,本条指令为beq,那么现在开始检验指令beq的实现过程:指令beq的功能是:if(rs=rt) pc←pc + 4 + (sign-extend)immediate <<2 else pc ←pc + 4,immediate是从PC+4地址开始和转移到的指令之间指令条数。
immediate符号扩展之后左移2位再相加。左移2位是由于跳转到的指令地址肯定是4的倍数(每条指令占4个字节),最低两位是“00”,因此将immediate放进指令码中的时候,已经右移两位,这与上文 “指令之间指令条数”相契合。运算结果符合事实,单元工作正常。
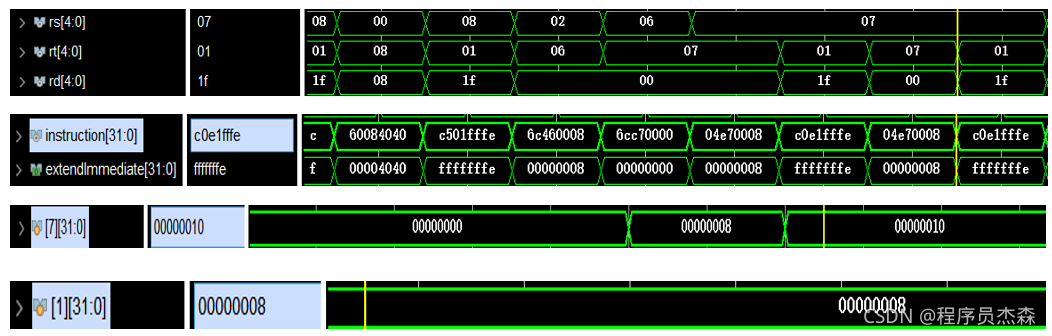
sw:
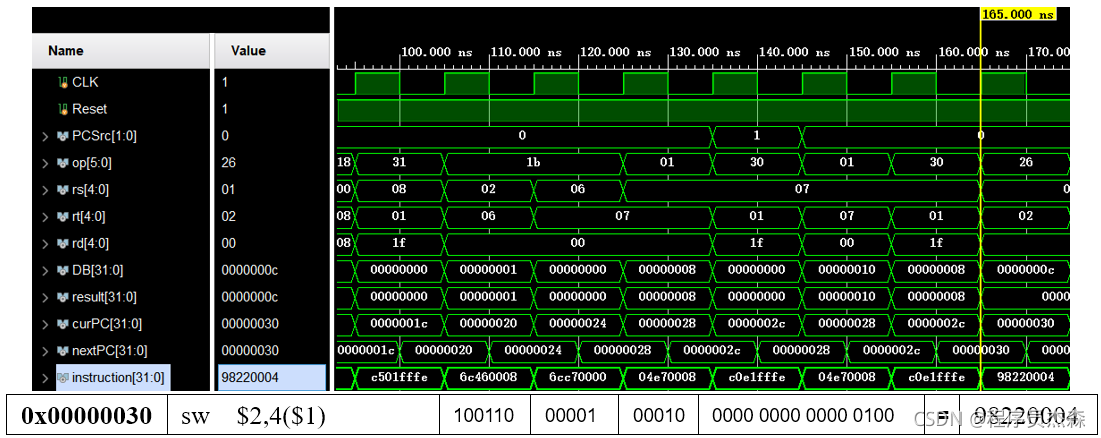
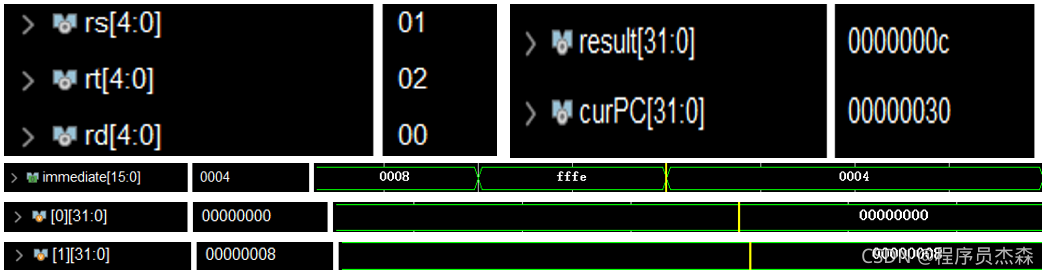
第19个周期中,指令地址为98220004,在程序测试段中,可以看到,本条指令为sw,那么现在开始检验指令sw的实现过程:指令sw的功能是:memory[rs+ (sign-extend)immediate]←rt;immediate符号扩展再相加。
将rt寄存器的内容保存到rs寄存器内容和立即数符号扩展后的数相加作为地址的内存单元中。同样的依次找到源操作数在寄存器中的值,进入ALU运算后,检验结果,过程图展示如下,结果无误,单元功能实现完好。
lw:
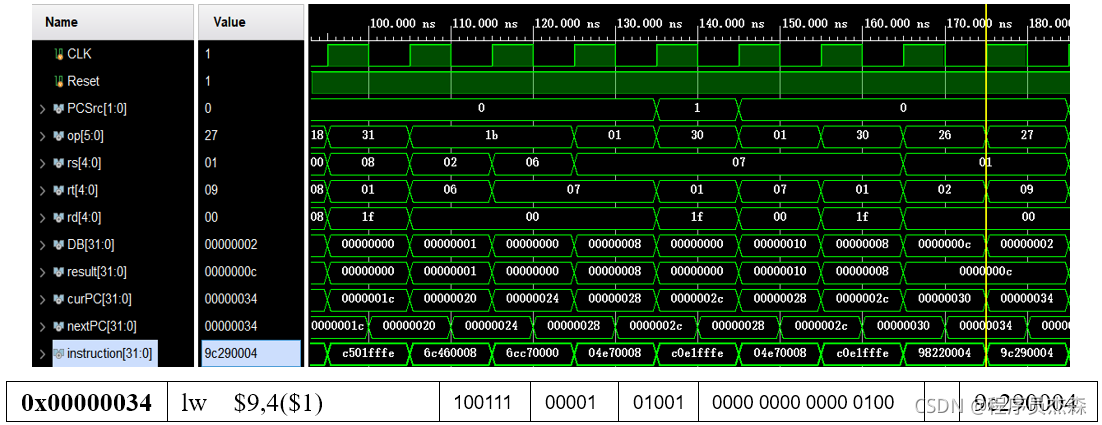
第20个周期中,指令地址为9c290004,在程序测试段中,可以看到,本条指令为lw,那么现在开始检验指令lw的实现过程:指令lw的功能是:rt ← memory[rs + (sign-extend)immediate];immediate符号扩展再相加。
读取rs寄存器内容和立即数符号扩展后的数相加作为地址的内存单元中的数,然后保存到rt寄存器中。同样的依次找到源操作数在寄存器中的值,进入ALU运算后,检验结果,过程图展示如下,结果无误,单元功能实现完好。

j:
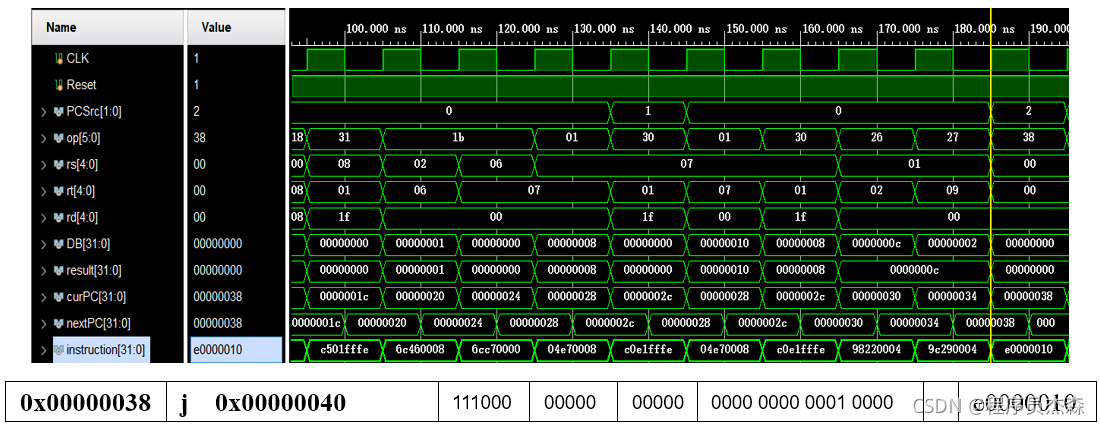
第21个周期中,指令地址为e0000010,在程序测试段中,可以看到,本条指令为j,那么现在开始检验指令j的实现过程:指令j的功能是:pc <-{(pc+4)[31…28],addr[27…2],2{0}},无条件跳转。
由于MIPS32的指令代码长度占4个字节,所以指令地址二进制数最低2位均为0,将指令地址放进指令代码中时,可省掉!这样,除了最高6位操作码外,还有26位可用于存放地址,事实上,可存放28位地址了,剩下最高4位由pc+4最高4位拼接上。指令验证过程如下,最后结论为:单元工作正常,功能实现完好。
halt:
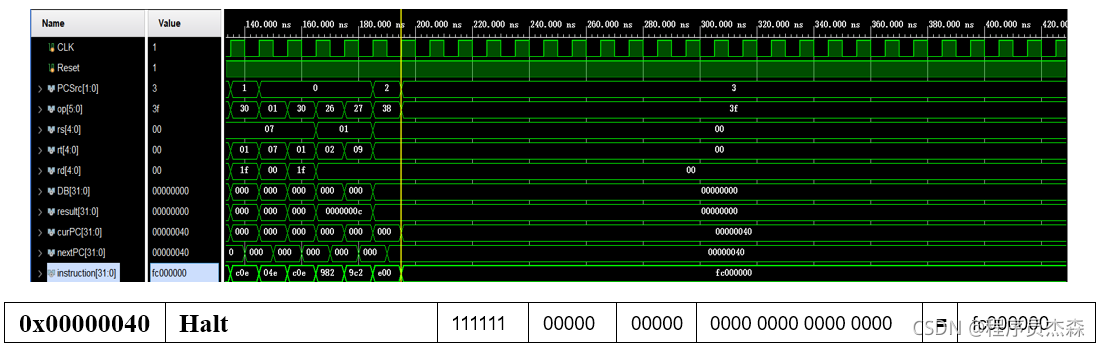
第22个周期中,指令地址为fc000000,在程序测试段中,可以看到,本条指令为Halt,那么现在开始检验指令Halt的实现过程:指令Halt的功能是:停机;不改变PC的值,PC保持不变。从仿真后的波形图中,可以清晰看到,波形图在本指令后,电平恒定,不再发生变化,所以本指令功能实现,模块单元工作正常。
总结
深刻了解了一个简单单周期CPU的设计方法,无论是复杂亦或是简单的系统,最好的办法就是采用分层和模块化的设计方法。在众多信号状态中,首先从最高层开始梳理逻辑,划分模块,进而到每个模块的内部核心处继续划分,这样就避免了在信号条件变动很多的情况下不能够清晰的理清的问题。
硬件设施的不足让人感觉整个课程在“云端”,讲授的内容不能很好的和现有知识的应用契合,虽然第一次接触VerilogHDL硬件描述语言,但是这门语言的思想和我所学的C++语言使用了同样的逻辑架构,采用了自顶向下、分而治之的思想逐步剖析,正所谓“大厦的建立绝非一朝一夕”,采用“分步”的设计思想完成最终单周期CPU的设计与实现。
有些许遗憾的是未能在硬件上实现,如果能在开发板上烧写程序,接触到实物,应该能有更为深刻的理解,在模块调用使用端口绑定时,有一个小技巧:勿完全按照顺序赋值;因为这样的方法可以尽量减少程序出错的概率,而对于我们后期检查源文件时也无需完全分辨每一个参数的值,减少工作量。
维基百科、谷歌学术是非常不错的平台。

