引言
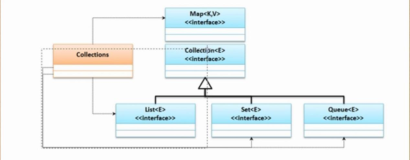
集合对于任何一门语言都是必须的。没有集合我们写不出一些复杂的逻辑。Guava继承扩展了Google Collections的一些功能。 从 com.google.common.collect包下面的类的数量,我们就可以看出Collections的重要性。 虽然已经有了这么多的工具类,但是还是有很多场景我们没有覆盖到,我们希望我们能够覆盖到日常使用的哪些。 下面我们就在每天的编程中经常会使用的类做一下介绍. 这一章节中我们将涉及以下几个方面:
- lists,maps,sets 等这些包含非常有用的静态方法的类
- Range类,主要作用是表示一个连续集合的边界值
- 不可变集合类
- Bimaps,可以像key-to-value方式一样去操作value-key
- Table 类型的集合,可以代替我们之前为了表示一个表格而采用 嵌套Map的方式
- Mutimaps 可以支持一个唯一的key对映多个值
- FluentIterable
- Ordring 类 增强了Comparators的能力
FluentIterable 类
FluentIterable 类是一个Iterable的更加有力的版本,FluentIterable 采用了链式编程的方式,使得代码的可读性更好。
使用FluentIterable.filter方法
FluentIterable 接受一个Predicate 参数,每个参数都会执行Predicate指定的方法,如果为true就加入到Iterable中,如果没有一个对象满足条件,那么就返回一个空的Iterable对象。 下面的这个例子中,我们将展示怎样结合from和fliter方法来返回合理的Iterable对象:
@Before
public void setUp() {
person1 = new Person("Wilma", "Flintstone", 30, "F");
person2 = new Person("Fred", "Flintstone", 32, "M");
person3 = new Person("Betty", "Rubble", 31, "F");
person4 = new Person("Barney", "Rubble", 33, "M");
personList = Lists.newArrayList(person1, person2, person3,
person4);
}
@Test
public void testFilter() throws Exception {
Iterable<Person> personsFilteredByAge=
FluentIterable.from(personList).filter(new Predicate<Person>() {
@Override
public boolean apply(Person input) {
return input.getAge() > 31;
}
});
assertThat(Iterables.contains(filtered, person2),
is(true));
assertThat(Iterables.contains(filtered, person4),
is(true));
assertThat(Iterables.contains(filtered, person1),
is(false));
assertThat(Iterables.contains(filtered, person3),
is(false));
}上面的代码中我们使用setUp方法,我们创建了一个personList对象,使用Lists.newArrayList()方法,在Test 方法中,我们创建了一个personFilterByAge 的Precidate实例,通过FluentIterable.from()将 personList作为参数传递给filter中。 Assert中我们验证了是否满足条件的对象都包含在了Iterable中。
使用FluentIterable.transForm 方法
FluentIterable.transform 方法是一个mapping的映射,将新的Function应用到每一个元素中, 结果中会产生一个新的Iterable对象,包含了转换后的每一个对象。和filter方法不同的事,filter方法会改变原来的集合。而transfrom方法则是返回一个新的集合。 下面是具体的代码:
@Test
public void testTransform() throws Exception {
List<String> transformedPersonList =
FluentIterable.from(personList).transform(new Function<Person,
String>() {
@Override
public String apply(Person input) {
return Joiner.on('#').join(input.getLastName(),
input.getFirstName(), input.getAge());
}
}).toList();
assertThat(transformed.get(1), is("Flintstone#Fred#32"));
}在这个例子中,我们将personList中的每一个person对象用'#'将lastName,firstName,age连接在一起,这里我们使用FluentIterable的链式编程,FluentIterable.from().transForm().toList()方法,最后我们采用了toList()方法返回了一个List对象,除了toList()方法我们还有toSet,toMap,toSortedList,toSortedSet方法,其中toMap方法中,我们将fluentIterbale中的每一个对象当作key,对每一个key使用toMap中指定的Function方法得到value。 toSortedList和toSortedSet方法使用一个Comparator方法作为参数来指定顺序。 这里还有很对方法我们没有介绍到,并且我们还有很多实现Iterable接口的类,‘FluentIterable’ 是一个比较好用的类。
Lists
Lists 是List的一个工具类的实现,一个最大的便利是可以非常方便的创建一个新的List实例:
List<Person> personList = Lists.newArrayList();使用Lists.partition方法
Lists.partition() 是一个非常有意思的方法,根据你传入的参数将list分隔成多个子list,但是有个意外就是有可能最后一个list并没有指定的那么多元素。 下面我们来看一个例子:
List<Person> personList =
Lists.newArrayList(person1,person2,person3,person4);
List<List<Person>> subList = Lists.partition(personList,2);在之前的例子中,我们创建了一个List对象,里面包含了4个person对象,调用了partition方法后我们会得到一个List>对象,其中 第一个是[person1,person2] 第二个是[person3,person4],但是如果是调用的Lists.partition(personList,3)的话,那么第一个[person1,person2,person3]第二个就变成了[person4]
使用Sets
Sets 是 Set接口的一个工具类实现,包含了创建 HashSets,LinkedHashSets,TreeSets。
使用Sets.difference 方法
Sets.fifference 方法接受两个set对象参数,返回一个SetView 包含了在第一个set存在,但是在第二个set中不存在的元素。 SetView是一个Sets类的静态内部类,是一个不可变对象。 下面我们来看一个例子:
Set<String> s1 = Sets.newHashSet("1","2","3");
Set<String> s2 = Sets.newHashSet("2","3","4");
Sets.difference(s1,s2);这时候 我们得到得SetView对象中有"1"这个元素,但是我们要是颠倒s1,s2那么得到得就会是"4"
使用Sets.symmetricDifference方法
这个方法返回的是 在第一个set中存在,或则在第二个set中存在,但是不在set1和set2都存在的。就是返回除了set1和set2交集之外的元素. 返回的结果也是也是一个不变对象.例子如下:
Set<String> s1 = Sets.newHashSet("1","2","3");
Set<String> s2 = Sets.newHashSet("2","3","4");
Sets.SetView setView = Sets.symmetricDifference(s1,s2);
//Would return [1,4]使用Sets.intersection 方法
这个方法返回两个set的交集:
@Test
public void testIntersection(){
Set<String> s1 = Sets.newHashSet("1","2","3");
Set<String> s2 = Sets.newHashSet("3","2","4");
Sets.SetView<String> sv = Sets.intersection(s1,s2);
assertThat(sv.size()==2 && sv.contains("2") &&
sv.contains("3"),is(true));Sets.union方法
这个方法返回两个set的并集
@Test
public void testUnion(){
Set<String> s1 = Sets.newHashSet("1","2","3");
Set<String> s2 = Sets.newHashSet("3","2","4");
Sets.SetView<String> sv = Sets.union(s1,s2);
assertThat(sv.size()==4 &&
sv.contains("2") &&
sv.contains("3") &&
sv.contains("4") &&
sv.contains("1"),is(true));
}Maps
Maps 是一个非常有必要的数据结构,在我们的日常的编程中经常会用到,快速简单的创建使用map可以提高程序员的工作效率。 Maps 工具类正是提供了一些帮助。 首先我们要尝试一下可以快速从一些Collection 中构建一个Map对象。 现在让我关注一下这样的一个问题: 我们有一个List对象,我们希望将它变成为一个map对象,以书的ISBN对象为key. 在没有使用Maps之前,我们可能写如下的代码:
List<Book> books = someService.getBooks();
Map<String,Book> bookMap = new HashMap<String,Book>()
for(Book book : books){
bookMap.put(book.getIsbn(),book);
}尽管上面的代码简洁明了,但是我们可以做到更简单。
使用Maps.uniqueIndex 方法
Maps.uniqueIndex方法 接受两个参数 一个是 Iterable对象,一个是 Function对象。 Iterable对象的元素作为 Map的value, Function对象接受 Iterable元素作为值 经过 apply返回的值作为Map的key。 例子如下:
List<Book> books = someService.getBooks();
Map<String,Book>bookMap = Maps.uniqueIndex(books.iterator(),new
Function<Book, String>(){
@Override
public String apply( Book input) {
return input.getIsbn();
}
};)这个例子中我们提供了books 集合并且定义了一个Function抽取了book中的ISBN作为map的key。我们这里对于Function使用了匿名内部类,我们其实还可以使用依赖注入的方式,这样我们就可以很简单的将抽取算法改变。
使用Maps.asMap方法
Maps.uniqueIndex 方法使用Function去产生keys,Maps.asMap 刚好采用相反的方式。 Maps.asMap 用 set of objects 作为keys, 使用Function 对每一个key执行apply方法等到一个value值。 还有另外一个方法 Maps.toMap 接受相同的参数,但是返回值不一样,Map.toMap返回一个不可变的Map. 这两个方法的区别就是 对于 Maps.toMap 返回值的改动不会影响到原来的Map,但是 Maps.asMap的返回值改动会影响到原来的Map。
Transforming Maps
Maps 类中有很多非常有用方法用于改变map的值。 Maps.transfromEntries 方法使用一个实现了Maps.EntryTransformer接口的实例,原来的每个key对应的值转换成一个新的值。 Maps.transformValues 使用一个实现了Function接口的实例,将原来的值转换成一个新值。
Multimaps
尽管Map是一个非常好用的数据结构,但是我们经常会想要把key对应为多个Value。 我们可以自己实现这样的功能,比如将一个key 对应的value 设计成是一个List. 但是GUAVA可以让这个变得更加简单,Multimaps 里面的一些静态方法返回一个Map实例,这样我们就可以像之前使用Map一样,简单的使用put(key,value)方法. 下面让我们一起探究一下这个神奇的map。
ArrayListMultimap
ArrayListMultimap使用ArrayList 存储给定的key对应的value. 我们可以按照如下方式创建ArrayListMultimap实例. 代码样例如下:
• ArrayListMultimap<String,String> multiMap =
ArrayListMultimap.create();
• ArrayListMutilmap<String,String> multiMap =
ArrayListMultimap.create(numExcpectedKeys,numExpectedValuesPer
Key);
• ArrayListMulitmap<String,String> mulitMap =
ArrayListMultimap.create(listMultiMap);下面我们来看一下具体的使用方式:
@Test
public void testArrayListMultiMap(){
ArrayListMultimap<String,String> multiMap =
ArrayListMultimap.create();
multiMap.put("Foo","1");
multiMap.put("Foo","2");
multiMap.put("Foo","3");
List<String> expected = Lists.newArrayList("1","2","3");
assertEquals(multiMap.get("Foo"),expected);
}这里我们只是简单的向创建好的multiMap里put相同的key对应的value,然后我们再取出key对应的List对象进行比较.
下面让我考虑一下林外一种使用方式。 如果我们针对一个key,不断的put相同的value会是怎样的一种情况呢,让我们来看一下下面的例子:
@Test
public void testArrayListMultimapSameKeyValue(){
ArrayListMultimap<String,String> multiMap =
ArrayListMultimap.create();
multiMap.put("Bar","1");
multiMap.put("Bar","2");
multiMap.put("Bar","3");
multiMap.put("Bar","3");
multiMap.put("Bar","3");
List<String> expected = Lists.
newArrayList("1","2","3","3","3");
assertEquals(multiMap.get("Bar"),expected);
}
显然 List是不要求里面的元素是唯一的。 上面的那个test显然是能通过的。 下面让我们来考虑一下另外一个例子:
multiMap.put("Foo","1");
multiMap.put("Foo","2");
multiMap.put("Foo","3");
multiMap.put("Bar","1");
multiMap.put("Bar","2");
multiMap.put("Bar","3");那么调用multimap.size()方法返回的值是什么呢? 是6还是2. 方法size()返回的是每个list里面的元素之和,而不是返回list的个数. 另外调用values() 方法返回的是一个包含的6个值,而不是返回2个集合每个集合包含3个元素. 这个一开始看上去有点让人想不通,但是我们要想到Multimap它其实不是一个真正的map,如果我们想像处理真正的Map去操作 我们可以调用下面的方法:
Map<String,Collection<String>> map = multiMap.asMap();由返回的对象我们就可以很简单的看出返回的是 一个key及对应的 Collection对象. 这里要注意的是 转换成普通的map后,我们就不能简单的调用map.put(key,value), 还有就是 对map的改动都会反映到原来的multimap中。
HashMultimap
HashMultiMap是基于Hash Tables,和ArrayListMultimap 不一样的是,针对同一个key不断put相同的value是不支持的,只会保留最后一个vaule值。 下面我们来看一下下面的例子:
HashMultimap<String,String> multiMap =
HashMultimap.create();
multiMap.put("Bar","1");
multiMap.put("Bar","2");
multiMap.put("Bar","3");
multiMap.put("Bar","3");
multiMap.put("Bar","3");上面的例子中我们针对bar插入了3次值, 但是当我们调用Multimap的size时,仅仅返回3. 除了不支持相同key-value的插入,其他的使用方式基本都一样,我们这边就不再啰嗦了。
Multimap总结
在我们讲其他之前,我们先来了解一下Multimap的其他的一些实现类, 首先我们有3个不变类实现:
ImmutableListMultimap, ImmutableMultimap, and ImmutableSetMultimap, LinkedHashMultiMap 是一个有顺序的集合,按照的是插入的顺序。 最后我们还有一个 TreeMultimap,他的排序顺序是按照自然顺序或则也可以指定一个comparator。
BiMap
和一个key可以用多个value一样,map还有一种方式可以使一个value对应一个key,这就是Bimap. BiMap中value的值是唯一的。下面让我们看一个具体的例子:
BiMap<String,String> biMap = HashBiMap.create();
biMap.put("1","Tom");
//This call causes an IllegalArgumentException to be
thrown!
biMap.put("2","Tom");在这个例子中我们尝试将两个相同的value加入到BiMap中,但是这回导致抛出"IlleagalArgumentException" 异常.
使用 BiMap.forcePut 方法
我们也可以是使用forcePut(key,value),这样的话如果出现 value相同,那么就会将以前的key-value 移出,将新的put进去. 下面我们来看一下例子:
@Test
public void testBiMapForcePut() throws Exception {
BiMap<String,String> biMap = HashBiMap.create();
biMap.put("1","Tom");
biMap.forcePut("2","Tom");
assertThat(biMap.containsKey("1"),is(false));
assertThat(biMap.containsKey("2"),is(true));
}使用Bimap.inverse方法
下面我们来看一下inverse方法的使用:
@Test
public void testBiMapInverse() throws Exception {
BiMap<String,String> biMap = HashBiMap.create();
biMap.put("1","Tom");
biMap.put("2","Harry");
assertThat(biMap.get("1"),is("Tom"));
assertThat(biMap.get("2"),is("Harry"));
BiMap<String,String> inverseMap = biMap.inverse();
assertThat(inverseMap.get("Tom"),is("1"));
assertThat(inverseMap.get("Harry"),is("2"));
}这个就没有什么要解释的了,大家看了就懂。
Table
Maps 是一个非常强大的工具,但是有的时候我们仅仅使用一个Map是不够的,我们希望能在map中使用map。 Guava的 Table 提供了类似的数据结构, 一个Table 集合包含两个key,一个是行号,一个是列号,这两个组合起来指向一个value。
在guava 中有很对对Table的实现,比如说 HashBaseTable, 采用Map>的方式存储数据,使用Guava我们可以按照如下方式创建:
HashBasedTable<Integer,Integer,String> table =
HashBasedTable.create();
//Creating table with 5 rows and columns initially
HashBasedTable<Integer,Integer,String> table =
HashBasedTable.create(5,5);
//Creating a table from an existing table
HashBasedTable<Integer,Integer,String> table =
HashBasedTable.create(anotherTable);Table operations
下面是针对Table的一些常见的操作:
HashBasedTable<Integer,Integer,String> table =
HashBasedTable.create();
table.put(1,1,"Rook");
table.put(1,2,"Knight");
table.put(1,3,"Bishop");
boolean contains11 = table.contains(1,1);
boolean containColumn2 = table.containsColumn(2);
boolean containsRow1 = table.containsRow(1);
boolan containsRook = table.containsValue("Rook");
table.remove(1,3);
table.get(3,4);Table views
Table提供非常好用的方法获取行列数据:
Map<Integer,String> columnMap = table.column(1);
Map<Integer,String> rowMap = table.row(2);column() 方法返回一列数据,row方法返回两行数据,要注意的是返回的Map结果是一个引用,对返回结果的改变会直接改变原有的数据集。
Table还有一些其他实现:
- ArrayTable 就是一个简单的二维 数组。int[][]...
- ImmutableTable 这种Table创建后就不能够被改变,可以调用ImmutableTable.Builder方法创建
- TreeBaseedTable 这个table的 行,列 是排序的,既可以按照自然顺序排序,也可以指定排序方法。
Range
Range 可以帮助我们创建一个开闭渠道的集合,通过下面的例子我们就可以了解Range的作用:
Range<Integer> numberRange = Range.closed(1,10);
//both return true meaning inclusive
numberRange.contains(10);
numberRange.contains(1);
Range<Integer> numberRange = Range.open(1,10);
//both return false meaning exclusive
numberRange.contains(10);
numberRange.contains(1);Ranges with arbitrary comparable objects
Range 可以和任何实现了Comparable接口的对象合作,这样就可以非常简单创建一个filter去过滤符合Range条件的对象。 下面这个是一个Person的例子:
public class Person implements Comparable<Person> {
private String firstName;
private String lastName;
private int age;
private String sex;
@Override
public int compareTo(Person o) {
return ComparisonChain.start().
compare(this.firstName,o.getFirstName()).
compare(this.lastName,o.getLastName()).
compare(this.age,o.getAge()).
compare(this.sex,o.getSex()).result();
}我们希望能过获取年龄在30-50之间的那些人. 所以我们可以创建一个Range对象
Range<Integer> ageRange = Range.closed(35,50);接着我们创建一个返回年龄值的Function:
Function<Person,Integer> ageFunction = new Function<Person,
Integer>() {
@Override
public Integer apply(Person person) {
return person.getAge();
}
};最后我们利用Predicate的compose方法整合这两个功能:
Predicate<Person> predicate =
Predicates.compose(ageRange,ageFunction);这样我们就可以获取年龄在[30,50]之间的Person对象了。
Immutable collections
纵观整个章节,我们知道了很对创建collections的方法,但是绝大多数都是返回的可变集合对象,如果我们不是特别需要可变集合,一般来说我们最好返回一个不可变集合,原因有下面两个:
- 不可变集合是线程安全的
- 他可以阻止一些不知道的改变影响到原来的数据
Guava 提供了非常多的可选的不变集合,这些个集合对有对应的可变版本.
Creating immutable collection instances
只是返回的结果不一样,因此其他的功能我们就不多介绍,我们只是简单的看一下如何创建一个不可变集合,每一个不可变集合都有一个Builder方法,可以采用链式编程的方式,下面我们来看一下具体的例子:
MultiMap<Integer,String> map = new
ImmutableListMultimap.Builder<Integer,String>()
.put(1,"Foo")
.putAll(2,"Foo","Bar","Baz")
.putAll(4,"Huey","Duey","Luey")
.put(3,"Single").build();上面我们采用了链式编程的方式将key-value加入到Map中,最后调用了build()方法。
Ordering
对集合进行排序在编程中是一个关键点,在写代码中,一个非常好用的Sort工具是非常必要的,Ordering类提供了一个非常强大和好用的抽象类。 Ordering 类实现了 Comparator接口并且定义了抽象方法compare.
Creating an Ordering instance
有两种方式可以创建Ordering实例:
- 创建一个新的实例并且实现compare方法
- 使用Ordering.from 静态方法创建实例,参数为一个为实现了Compare接口的Comparator。
总的来说 具体额排序的实现还是由我们自己实现的。Ordering只是在此基础上加上了一些好用的封装。
Reverse sorting
设想一下我们实现一个按照城市人口排序的Comparator.
public class CityByPopluation implements Comparator<City> {
@Override
public int compare(City city1, City city2) {
return Ints.compare(city1.getPopulation(),city2.
getPopulation());
}
}
如果是我们使用上面的Comparator那么我们将得到的是城市人口从小到大的排序,那么如果我们想得到一个从大到小的排序呢? 我们就可以使用Ordering提供的方法
Ordering.from(cityByPopluation).reverse();在这个例子中,我们调用了Ordering.from()方法创建了一个Ordering对象,然后调用reverse()方法。
Accounting for null
在排序的过程中,我们一般会考虑值为null的对象,我们是把他们放在最前面还是最后面? Ordering给我们提供一个比较简单的方法:
Ordering.from(comparator).nullsFirst();
Ordering.from(comparator).nullsLast();Secondary sorting
在我们排序的过程中,我们会经常会碰到equals的情况,那么这时候我们就可以定义一个secondary的排序,下面我们来考虑一下上面的例子中城市人口相等情况,这时候我们就可以再定义一个第二次排序.按照降雨量排序.
public class CityByRainfall implements Comparator<City> {
@Override
public int compare(City city1, City city2) {
return Doubles.compare(city1.getAverageRainfall(),city2.
getAverageRainfal
l());
}
}
我们可以按照如下的方式指定第二排序:
Ordering.from(cityByPopulation).compound(cityByRainfall);下面看一个包含二次排序的例子:
@Test
public void testSecondarySort(){
City city1 = cityBuilder.population(100000).
averageRainfall(55.0).build();
City city2 = cityBuilder.population(100000).
averageRainfall(45.0).build();
City city3 = cityBuilder.population(100000).
averageRainfall(33.8).build();
List<City> cities = Lists.newArrayList(city1,city2,city3);
Ordering<City> secondaryOrdering = Ordering.
from(cityByPopulation).compound(cityByRainfall);
Collections.sort(cities,secondaryOrdering);
assertThat(cities.get(0),is(city3));
}Retrieving minimum and maximum values
最后我们来看一下,Ordering类可以让我们很方便的在一个集合里面找到最大值和最小值. 下面看一下代码实例:
Ordering<City> ordering = Ordering.from(cityByPopluation);
List<City> topFive = ordering.greatestOf(cityList,5);
List<City> bottomThree = ordering.leastOf(cityList,3);上面的代码中我们可以简单的获取 城市人口排名前5 和 倒数3名的城市
Summary
这一章我们学习了:
- FluentIterable
- Multimap
- Table
- Range
- Immutable
- Ordering