
爬虫经常需要伪装浏览器进行爬取数据,爬虫与反爬虫的较量无时无刻不在上演,本期介绍爬虫神器
selenium库的安装及使用!
0.效果展示
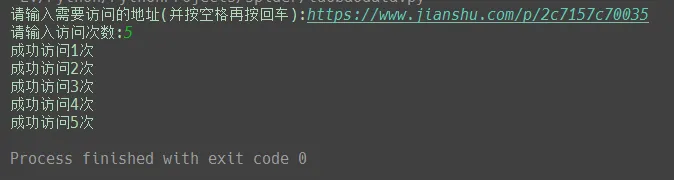

之前试过requests库来模拟访问,但加了请求头还是没用,访问量并没用增加,这次试用了selenium,selenium虽然好用,但是速度非常慢,除非迫不得已,建议还是别用这个库
关于这个demo,只是脑子一热就想到了,访问量也不能决定什么,没有必要去刷这个东西,靠歪门邪道获取虚荣的满足是不可取的,对于简书,我是把它当成一个记录学习过程的工具,顺便分享我的学习历程,demo仅供参考(大数量访问还没试过,不知道会不会被限制)
1.运行环境
- Python3.6.5
- Pycharm-2018.1.2
- win10
2.selenium的介绍
Selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的,类型像我们玩游戏用的按键精灵,可以按指定的命令自动操作,不同是Selenium 可以直接运行在浏览器上,它支持所有主流的浏览器(包括PhantomJS这些无界面的浏览器)。
Selenium 可以根据我们的指令,让浏览器自动加载页面,获取需要的数据,甚至页面截屏,或者判断网站上某些动作是否发生。
Selenium 自己不带浏览器,不支持浏览器的功能,它需要与第三方浏览器结合在一起才能使用。但是我们有时候需要让它内嵌在代码中运行,所以我们可以用一个叫 PhantomJS 的工具代替真实的浏览器。
3.安装selenium
1,pip install selenium
2,下载Firefox浏览器
3,下载geckodriver(是Firefox的官方webdriver)下载地址
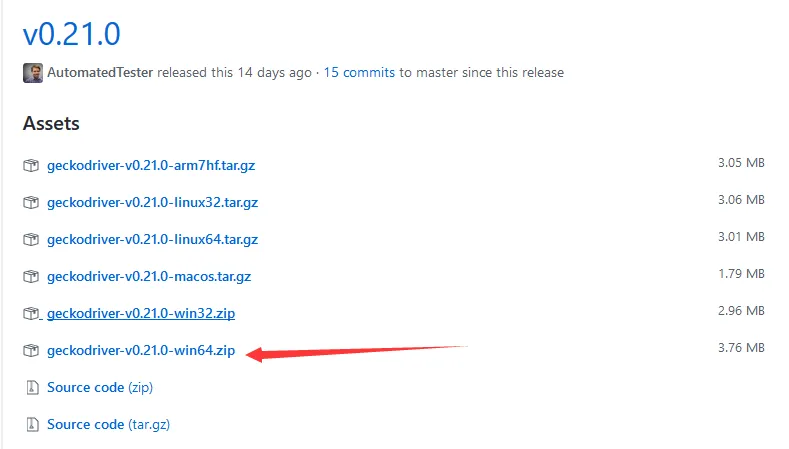
这里可以看到最新版为v0.21.0,我的电脑是windows10 64位,所以选择下载geckodriver-v0.21.0-win64.zip
放置位置:放到Python目录的Scripts下
4.代码示例
from selenium import webdriver
def IncreaseViews():
url = input('请输入需要访问的地址(并按空格再按回车):')
n = int(input('请输入访问次数:'))
browser = webdriver.Firefox()
for i in range(n):
browser.get(url)
browser.refresh()
print('成功访问{}次'.format(i+1))
i += 1
browser.close()
IncreaseViews(
测试发现:简书在登陆账号的情况下,在访问过一篇文章后(访问量+1),无法通过再次访问来增加访问量(访问自己的文章不增加访问量),但是,在不登陆账号的情况下,可以无限增加访问量!不知是简书的BUG还是有意为之。

