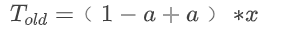memoization适用于递归计算场景,例如 fibonacci 数值 的计算。
; |
如果使用这种递归的写法去计算第 50 个 fibonacci 数值,需要执行 40730022147 次。随着执行次数的增加,执行所需时间成指数上涨:

memoization的技巧在于将计算过的结果『缓存』下来,避免重复计算带来的成本,例如将计算 fibonacci 的代码改写为如下形式:
; |
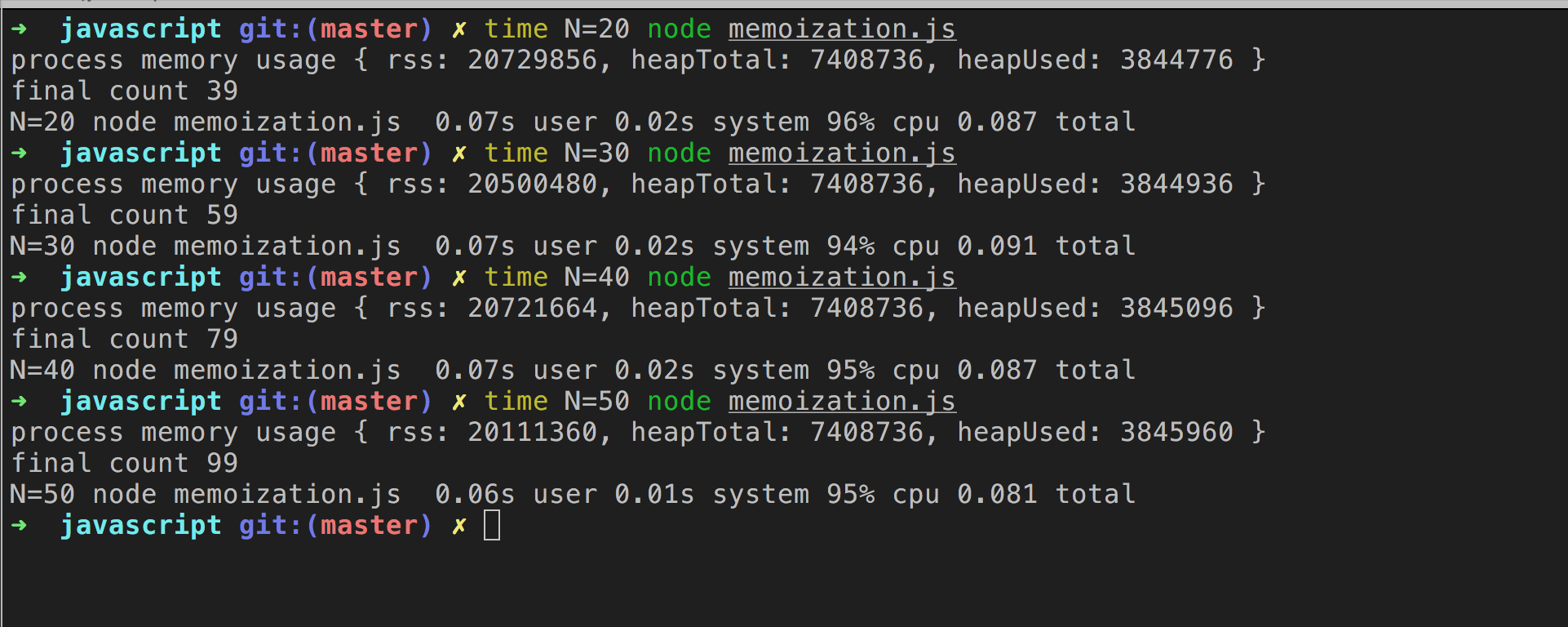
计算第 50 个 fibonacci 值只需要 99 次,执行时间为 0.06 秒,只有递归版本执行时间(546.41 秒)的万分之一,使用的内存(RSS 值 20111360)只有递归版本(RSS 值为 36757504)的 54%。
值得注意的是:这里闭包使用的
memo对象有可能造成内存泄露。
处理多个参数
如果需要处理多个参数,需要把缓存的内容变成多维数据结构,或者把多个参数结合起来作为一个索引。
例如:
; |
上面执行了两次fibonacci函数,假设执行多次:
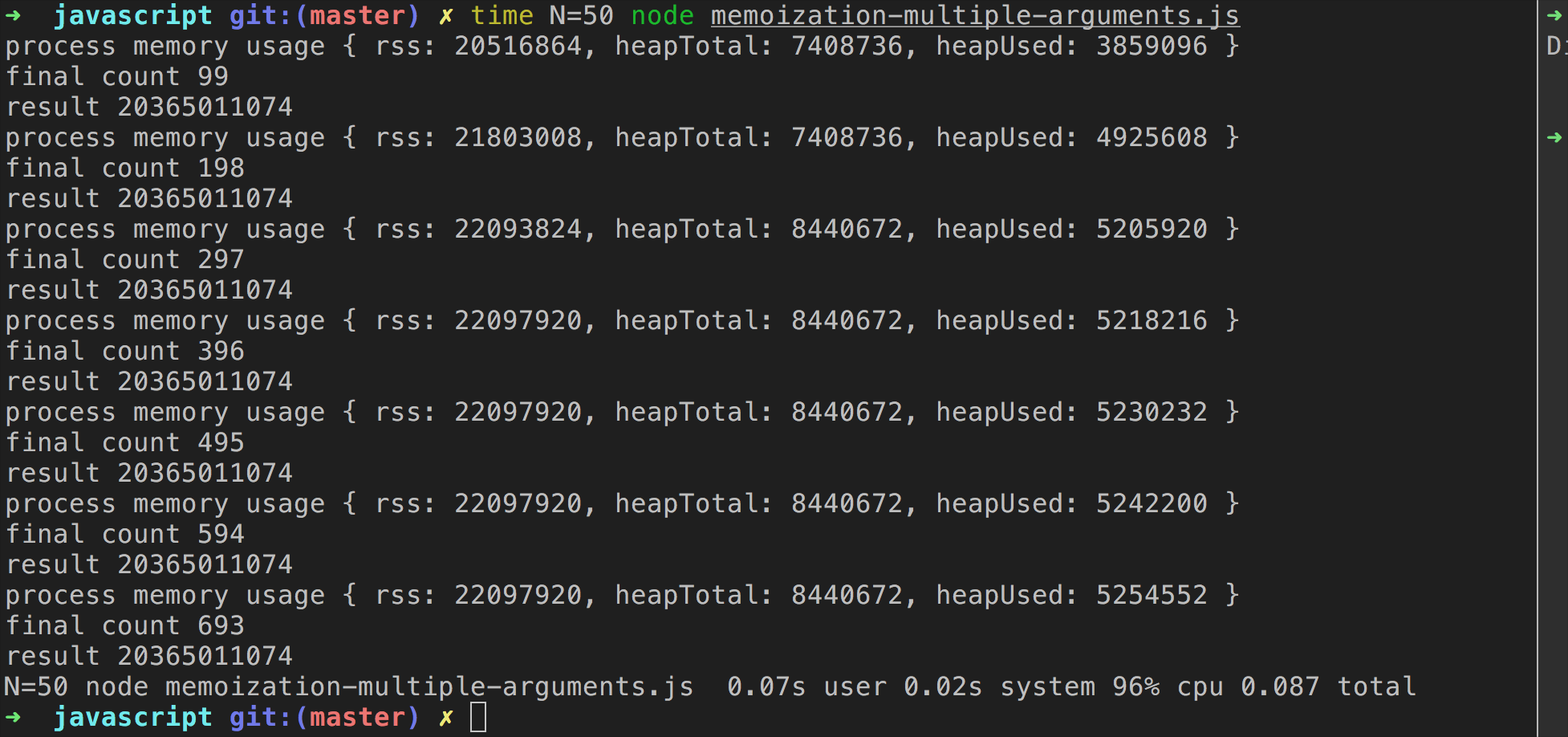
可以看到内存的增长也是有限的,并且最终控制在了22097920这个值。下面是另一种处理多个参数的情况(将多个参数组成一个索引):
; |
与上面版本相比,内存有所增加,速度有所下降:



自动memoization
function memoize(func) { |
但是需要注意的是,并不是所有函数都可以自动memoization,只有referential transparency(引用透明)的函数可以。所谓referential transparency的函数是指:函数的输出完全由其输入决定,且不会有副作用的函数。下面的函数就是一个反例:
var bar = 1; |
对比自动memoization前后的两个版本:

自动memoization处理后的版本有所提高,但相比手动完全memoization的版本效率还是差了很多。
其实memoization这个词来自人工智能研究领域,其词源为拉丁语memorandum,这个词的创造者为Donald Michie,这种函数的设计初衷是为了提升机器学习的性能。随着函数式编程语言(Functional Programming,简称 FP)的兴起,例如 JavaScript、Haskell 以及 Erlang,这种用法才变得越来越流行。在前端编程中,可以使用memoization去处理各种需要递归计算的场景,例如缓存 canvas 动画的计算结果。
上面自动memoization的结果并不理想,可以参考underscore和lodash的memoize来做优化。
使用lodash的memoize方法:
/** |
对比结果:

可以看到lodash的memoize方法减少了一半执行时间。进一步优化:
module.exports = function memoize(func, context) { |

科普下:
function arity指的是一个函数接受的参数个数,这是一个被废弃的属性,现在应使用Function.prototype.length。
https://stackoverflow.com/questions/4848149/get-a-functions-arity
zakas 的版本更加快,甚至比我们将fibonacci手动memoization的版本还快:
; |
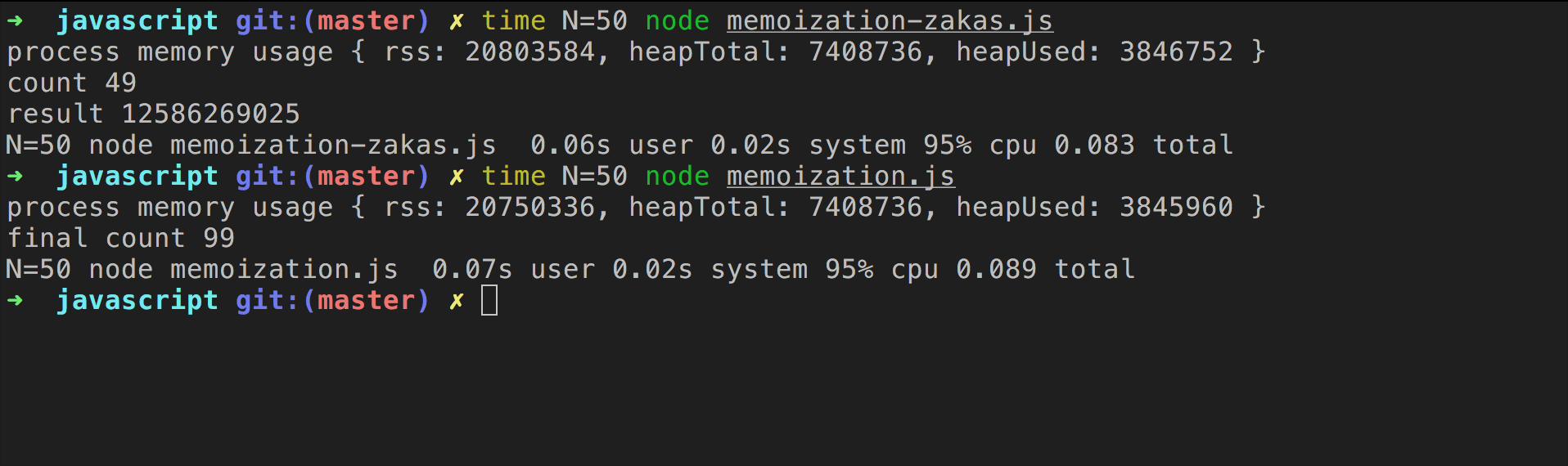
但是上面这些函数都存在问题,如果输入数目过大,会引发调用栈超过限制异常:RangeError: Maximum call stack size exceeded。
一种解决的方法就是将递归(recursion)修改为迭代(iteration)。例如下面这样的归并排序算法:
; |

而上面的排序函数在经过memoization后虽然不会抛出RangeError: Maximum call stack size exceeded的异常,但是在极端情况下也会因为内存不够分配导致失败:
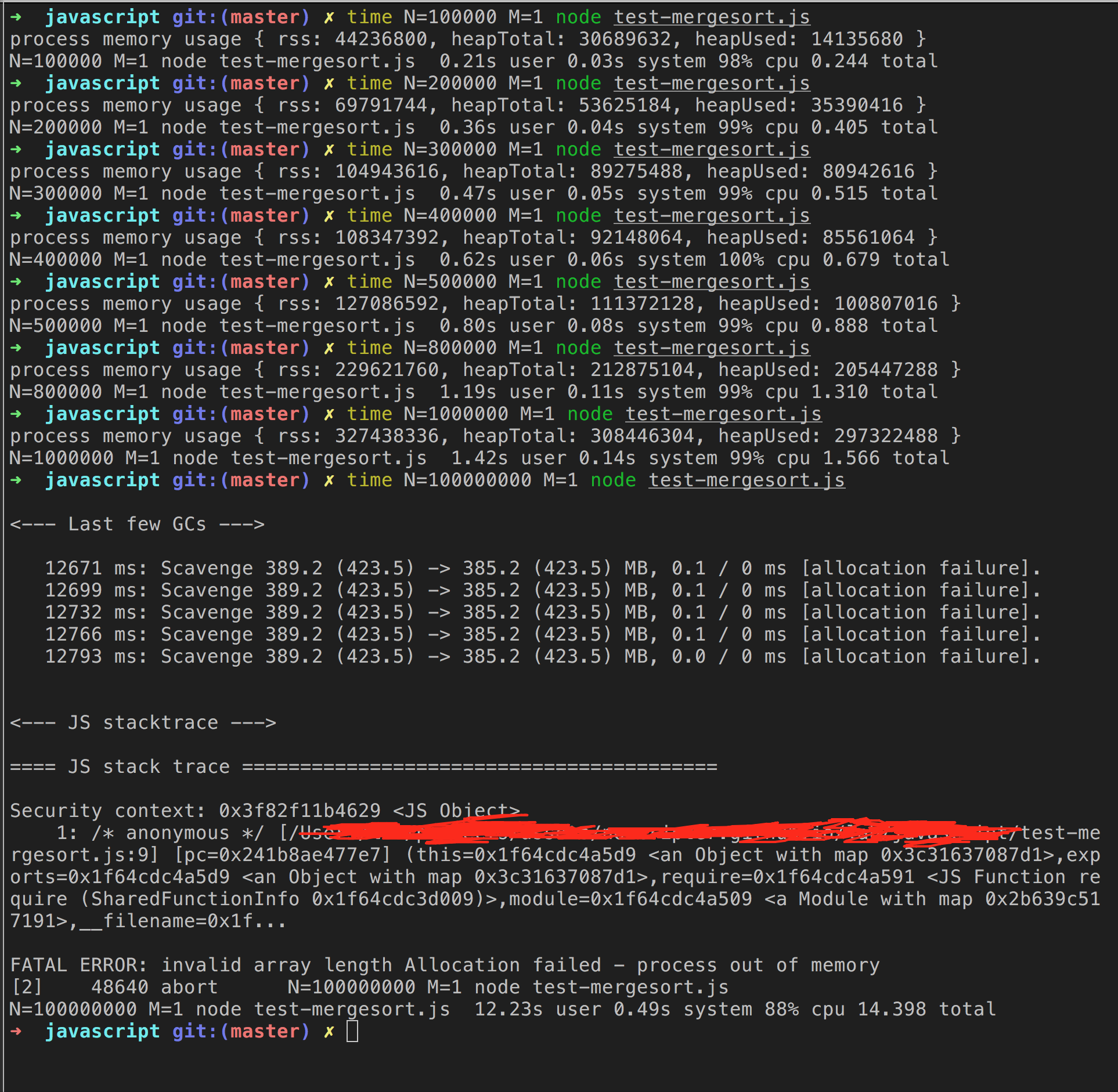
解决RangeError: Maximum call stack size exceeded异常的一种方法是将递归的代码改写为迭代的代码,例如fibonacci的递归式写法为:
; |
他山之石
在 JavaScript 中我们是通过函数的形式来是实现函数的memoization,在 Python 中还可以用另一种被称为decorator的形式:
#!/usr/bin/env python |
参考资料
- https://www.sitepoint.com/implementing-memoization-in-javascript/
- Referential transparency)
- https://addyosmani.com/blog/faster-javascript-memoization/
- http://unscriptable.com/index.php/2009/05/01/a-better-javascript-memoizer/
- http://www.nczonline.net/blog/2009/01/27/speed-up-your-javascript-part-3/
- http://books.google.co.uk/books?id=PXa2bby0oQ0C&pg=PA44&lpg=PA44&dq=crockford+memoization&source=bl&ots=HImnm6r1iH&sig=lrdT9Sk4F4yQ-xQ-TLTx4SpLkuk&hl=en&ei=C-hyTvaIEofB8QO21Nn_DQ&sa=X&oi=book_result&ct=result&resnum=4&ved=0CDMQ6AEwAw#v=onepage&q&f=false
- http://my.safaribooksonline.com/book/programming/javascript/9781449399115/functions/function_propertiesma_memoization_patter#X2ludGVybmFsX0ZsYXNoUmVhZGVyP3htbGlkPTk3ODE0NDkzOTkxMTUvNzY=
- memoize function javascript | npm memoize | lodash memoize | underscore memoize
- http://unscriptable.com/2009/05/01/a-better-javascript-memoizer/
- programming optimization techniques
- http://blog.stevenlevithan.com/archives/timed-memoization
- https://github.com/addyosmani/memoize.js
- function arity
- https://philogb.github.io/blog/2008/09/05/memoization-in-javascript/
- https://stackoverflow.com/questions/6184869/what-is-difference-between-memoization-and-dynamic-programming
- http://www.python-course.eu/python3_memoization.php
- https://en.wikipedia.org/wiki/Iteration
- https://en.wikipedia.org/wiki/Iterated_function
- https://www.ics.uci.edu/~eppstein/161/960109.html
- https://classes.soe.ucsc.edu/cmpe012/Summer09/labs/lab8-Recursion-vs-Iteration/
- google: iterative merge sort
- google: maximum call stack size exceeded | avoid maximum recursive
- http://www.python-course.eu/python3_decorators.php
- https://www.cs.cornell.edu/courses/cs3110/2011sp/lectures/lec22-memoization/memo.htm
- dynamic programming