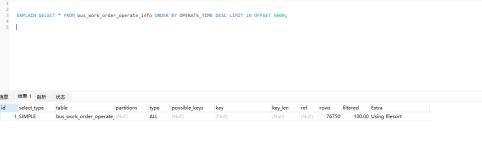
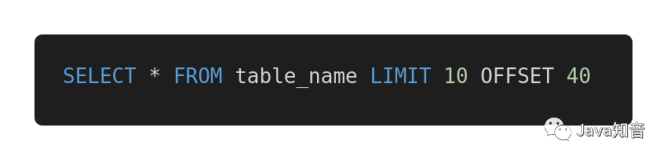
mysql> select SQL_NO_CACHE * from test1 order by id limit 99999,10;
+--------+--------+------+
| id | tid | name |
+--------+--------+------+
| 100000 | 100000 | abc |
| 100001 | 100001 | abc |
| 100002 | 100002 | abc |
| 100003 | 100003 | abc |
| 100004 | 100004 | abc |
| 100005 | 100005 | abc |
| 100006 | 100006 | abc |
| 100007 | 100007 | abc |
| 100008 | 100008 | abc |
| 100009 | 100009 | abc |
+--------+--------+------+
10 rows in set (0.07 sec)
虽然用上了id索引,但要从第一行开始起定位至99999行,然后再扫描出后10行。相当于一个全表扫描。
mysql> select SQL_NO_CACHE * from test1 where id >=100000 order by id limit 10;
+--------+--------+------+
| id | tid | name |
+--------+--------+------+
| 100000 | 100000 | abc |
| 100001 | 100001 | abc |
| 100002 | 100002 | abc |
| 100003 | 100003 | abc |
| 100004 | 100004 | abc |
| 100005 | 100005 | abc |
| 100006 | 100006 | abc |
| 100007 | 100007 | abc |
| 100008 | 100008 | abc |
| 100009 | 100009 | abc |
+--------+--------+------+
10 rows in set (0.00 sec)
第二种写法比第一种快了7倍。
利用id索引直接定位100000行,然后再扫描出后10行。相当于一个range范围扫描。
本文转自 liang3391 51CTO博客,原文链接:http://blog.51cto.com/liang3391/824878