《Windows Azure Platform 系列文章目录》
本章我将给大家介绍如何配置Virtual Machine的数据库。Virtual Machine的SQL 2012默认数据保存路径是在C盘。
我前一章介绍过了,C盘最大也只能支持127G,C盘的空间对我们来说非常宝贵,所以,对于其他非系统数据来说,保存到其他盘符(不能是D盘)是比较合理的解决方法。
1.首先我们登陆Windows Azure管理界面 https://manage.windowsazure.com/
2.在列表中选择"Virtual Machines",并找到之前创建的SQL2012VM1并使用远程桌面连接登录该VM。
3.在VM的远程桌面里,选择Start --> All Prpgrams --> Microsoft SQL Server 2012 --> SQL Server Management Studio
4.直接点击Connect连接,登录SSMS。
5.点击VM的SQL Server实例,邮件选择Properties。
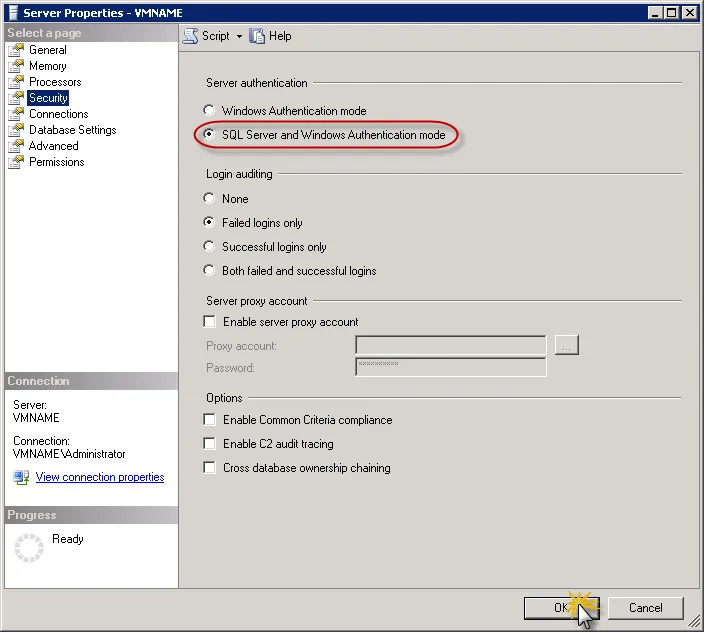
6.在弹出的Server Properties里,点击Sercurity,将Server authentication选择为SQL Server and Windows Authentication mode
7.在弹出的Server Properties里,点击Database Settings。我观察到Data, Log和Backup默认保存在"C:\Program Files\Microsoft SQL Server"里。我们把路径修改到之前创建的磁盘路径,具体如下:
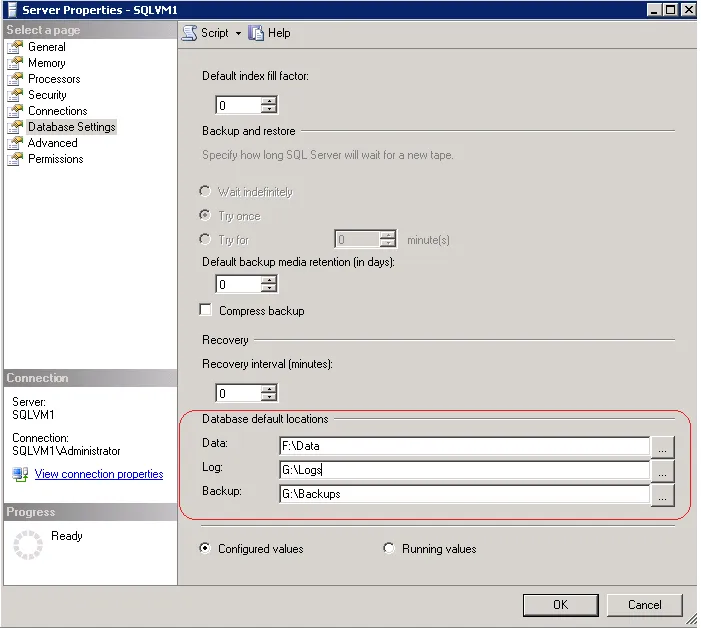
8.然后在VM的磁盘上创建以下文件夹:F:\Data, G:\Logs和G:\Backups
9.重新启动SQL Server服务。
10.在SSMS里,展开Security-->Logins-->找到sa帐号,右键,Properties
11.在Login Properties里,修改sa的密码。并将Enforce password policy的勾选去掉。
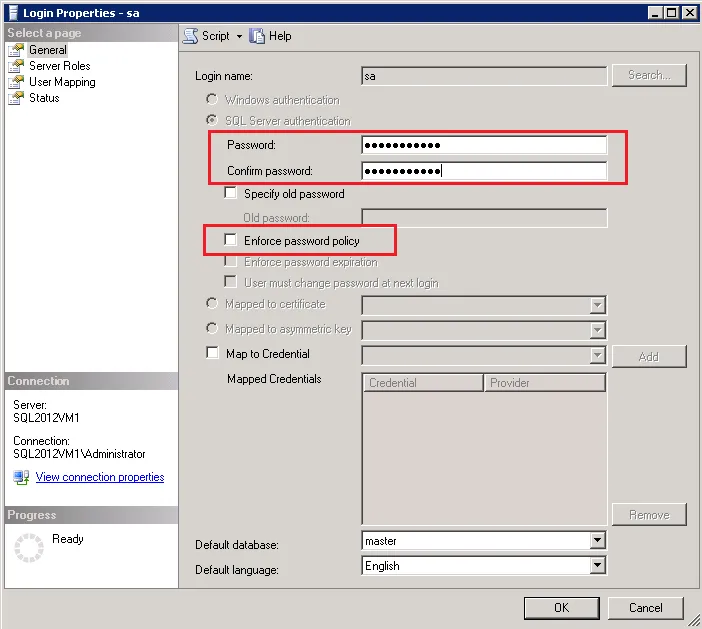
12.然后在左侧列表里选择Status,将Login选择为Enabled
 13.以上就是配置SQL Server的步骤。
13.以上就是配置SQL Server的步骤。
14.接下来就是配置防火墙规则。因为在之前的Windows Azure Platform (三十一) 使用Windows Azure Connect,实现云端应用连接本地SQL Server 2008 R2数据库里面介绍了如何设置SQL Server的TCP/IP规则。关键步骤我用截图表示:
15.将在SQL Server Configuration Manager里将TCP/IP的Status设置为Enabled
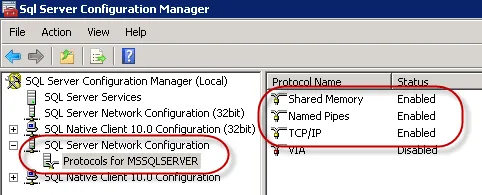
16.控制面板里添加防火墙规则。
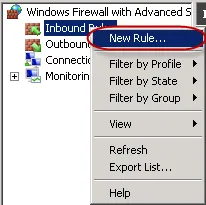
17.添加入站规则
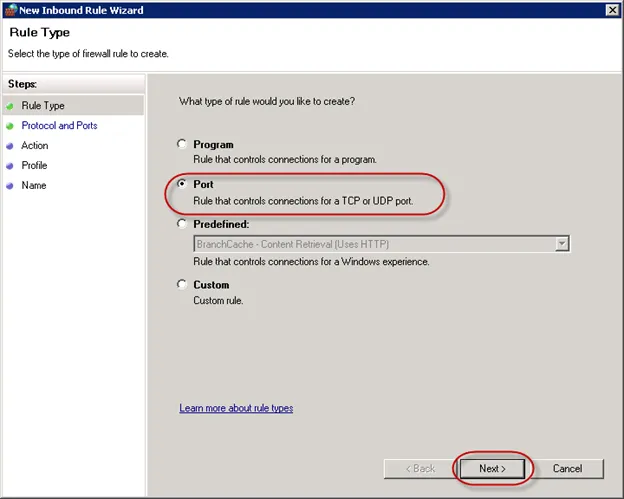
18.新建入站规则
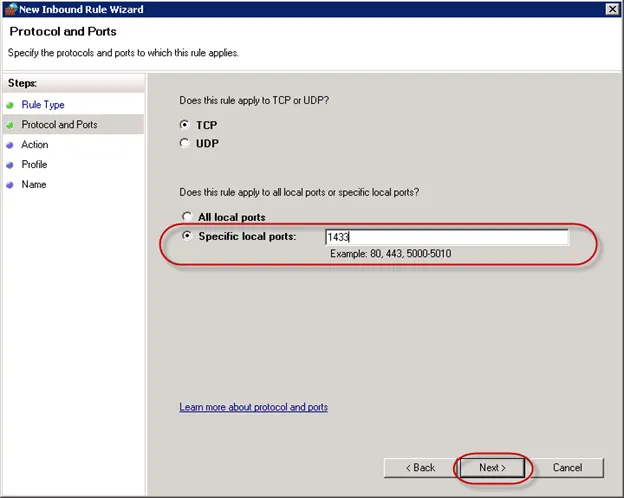
19.允许连接
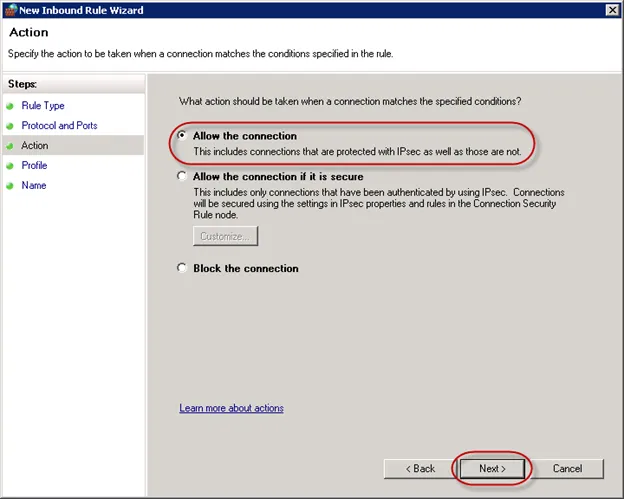
20.将规则名称设置为SQLServerRule并保存