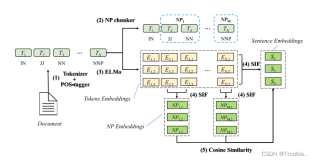
主要用于有向图
dot 默认布局方式 neato 基于spring-model(又称force-based)算法 基于斥力+张力的布局 twopi 径向布局 circo 圆环布局 osage
无向图布局
fdp 用于无向图 sfdp 用于无向图
演示
dot test.gv -Kdot -Tpng -o test.png dot test.gv -Kcirco -Tpng -o test.png dot test.gv -Kneato -Tpng -o test.png dot test.gv -Ktwopi -Tpng -o test.png dot test.gv -Ksfdp -Tpng -o test.png dot test.gv -Kosage -Tpng -o test.png
原文出处:Netkiller 系列 手札
本文作者:陈景峯
转载请与作者联系,同时请务必标明文章原始出处和作者信息及本声明。