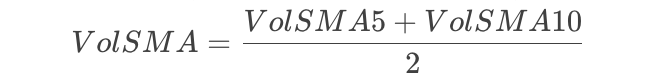+-----------+ | category | |-----------| |id | <---+ |title | | |description| 1:n |status | | |parent_id | o---+ +-----------+
CREATE TABLE `category` (
`id` SMALLINT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`name` VARCHAR(10) NOT NULL,
`description` VARCHAR(255) NULL,
`status` ENUM('enable','desable') NOT NULL DEFAULT 'enable',
`parent_id` SMALLINT(10) UNSIGNED NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
CONSTRAINT `FK1` FOREIGN KEY (`parent_id`) REFERENCES `category` (`id`)
)
COMMENT='goods category'
ENGINE=InnoDB
ROW_FORMAT=DEFAULT
多对多分类,主要用于满足,一个产品/文章属于多个分类的需求。
+------------+
| category |
|------------|
+--> |id | <---+
| |title | | +----------------------+
1:n |description | 1:n | categroy_has_product |
| |status | | +----------------------+
+--o |parent_id | | | id |
+------------+ +---o | category_id |
+---o | product_id |
+------------+ | +----------------------+
| product | 1:n
+------------+ |
|id | <---+
|price |
|quantity |
|... |
|status |
+------------+
上面我刚刚讲过怎样实现“不限子树的分类树”,我们可以实现不限层次的无线分类表。
+-----------+ | category | |-----------| |id | <---+ |title | | |description| 1:n |status | | |parent_id | o---+ +-----------+
问题出来了,当我需要读取一个分类(任意分类)下的所有子分类,怎样实现,很多人会说用“递归”。 当然“递归”可是现实我们的需求,在几百个分类的项目中,使用递归也不是不可以的,但是当数量非常庞大时怎么办?
当然有更好的解决方案,请看下面
+-----------+ | category | |-----------| |id | <---+ |title | | |description| 1:n |status | | |parent_id | o---+ |path | +-----------+
+-------------------------------------------------------------------------+ | category | +----+-----------+-----------------------+--------+-----------+-----------+ | id | name | description | status | parent_id | path | +----+-----------+-----------------------+--------+-----------+-----------+ | 1 | 中国 | 中华人民共和家 | Y | NULL | 1/ | | 4 | 广东省 | 广东省 | Y | 1 | 1/4 | | 5 | 深圳市 | NULL | Y | 4 | 1/4/5 | | 6 | 宝安区 | NULL | Y | 5 | 1/4/5/6 | | 7 | 龙华镇 | NULL | Y | 6 | 1/4/5/6/7 | +----+-----------+-----------------------+--------+-----------+-----------+
CREATE TABLE `category` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '分类ID',
`name` VARCHAR(50) NOT NULL COMMENT '分类名称',
`description` VARCHAR(200) NULL DEFAULT NULL COMMENT '分类描述',
`status` ENUM('Y','N') NOT NULL DEFAULT 'Y' COMMENT '分类状态有继承性',
`parent_id` INT(10) NULL DEFAULT '1' COMMENT '分类父ID',
`path` VARCHAR(255) NOT NULL COMMENT '分类递归路径索引',
INDEX `PK` (`id`),
INDEX `relation` (`id`, `parent_id`),
INDEX `FK_category_category` (`parent_id`),
INDEX `path` (`path`)
)
COMMENT='分类表'
ENGINE=InnoDB
ROW_FORMAT=DEFAULT
AUTO_INCREMENT=0
insert into category(`name`,`description`,`status`,`parent_id`,`path`) values('中国','中华人民共和家','Y',null,'1/')
ALTER TABLE `category` ADD CONSTRAINT `FK_category_category` FOREIGN KEY (`parent_id`) REFERENCES `category` (`id`)
抽取广东子树
select * from category where path like '1/4%';
mysql> select * from category where path like '1/4%'; +----+-----------+-------------+--------+-----------+-----------+ | id | name | description | status | parent_id | path | +----+-----------+-------------+--------+-----------+-----------+ | 4 | 广东省 | 广东省 | Y | 1 | 1/4 | | 5 | 深圳市 | NULL | Y | 4 | 1/4/5 | | 6 | 宝安区 | NULL | Y | 5 | 1/4/5/6 | | 7 | 龙华镇 | NULL | Y | 6 | 1/4/5/6/7 | +----+-----------+-------------+--------+-----------+-----------+ 4 rows in set (0.00 sec)
DROP TABLE IF EXISTS `test`; CREATE TABLE IF NOT EXISTS `test` ( `id` int(11) DEFAULT NULL, `pid` int(11) DEFAULT NULL, `name` char(50) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `test` (`id`, `pid`, `name`) VALUES (1, 0, 'A'), (2, 1, 'B'), (3, 1, 'C'), (4, 0, 'D'), (5, 0, 'E'), (6, 5, 'F'); select (select t2.name from test t2 where t2.id=t1.pid) as name, count(pid) as sum from test t1 where t1.pid <> 0 group by t1.pid;
统计所有节点包括数量为零的
select t1.name, (select count(t2.name) from test t2 where t2.pid=t1.id) as sum from test t1
例 4.1. identity_card 身份证归属地表
CREATE TABLE `identity_card` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '唯一主键',
`pid` INT(10) UNSIGNED NOT NULL DEFAULT '0' COMMENT '父ID',
`path` VARCHAR(50) NOT NULL COMMENT '路径',
`number` VARCHAR(18) NOT NULL COMMENT '身份证号码段',
`zone` VARCHAR(50) NOT NULL COMMENT '行政区域',
`status` ENUM('Y','N') NOT NULL DEFAULT 'N' COMMENT '状态',
`modified` TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建与修改时间',
PRIMARY KEY (`id`),
INDEX `FK_identity_card_identity_card` (`pid`),
INDEX `path` (`path`),
INDEX `number` (`number`),
CONSTRAINT `FK_identity_card_identity_card` FOREIGN KEY (`pid`) REFERENCES `identity_card` (`id`) ON UPDATE CASCADE ON DELETE CASCADE
)
COMMENT='identity card number'
COLLATE='utf8_general_ci'
ENGINE=InnoDB;
"id" "pid" "path" "number" "zone" "status" "modified" "1012" "1" "1.1012" "330000" "浙江省" "Y" "2012-05-16 17:18:14" "1041" "1012" "1.1012.1041" "330300" "温州市" "Y" "2012-05-16 17:44:18" "1052" "1041" "1.1012.1041.1052" "330381" "瑞安市" "Y" "2012-05-16 17:44:25" "1367" "1" "1.1367" "360000" "江西省" "Y" "2012-05-16 16:57:23" "1451" "1367" "1.1367.1451" "360900" "宜春市" "Y" "2012-05-16 17:44:58" "1990" "1" "1.1990" "430000" "湖南省" "Y" "2012-05-16 16:50:50" "1991" "1990" "1.1990.1991" "430100" "长沙市" "Y" "2012-05-16 16:50:54" "2124" "1990" "1.1990.2124" "431300" "娄底市" "Y" "2012-05-16 16:54:45"
原文出处:Netkiller 系列 手札
本文作者:陈景峯
转载请与作者联系,同时请务必标明文章原始出处和作者信息及本声明。