在分布式计算和海量数据中摸爬滚打了很久之后,你一定会感谢优雅的 Google Map-Reduce 框架。它的 map ,emit 和 reduce模块既通用又简洁,这使它成为了一个强有力的工具。虽然 Google 公开了理论,但是底层的软件实现仍然是闭源的,而这可以说是他们最大的竞争优势之一(GFS,BigTable,等等)。当然,现在有很多开源的分支(Apache Hadoop,Disco,Skynet,以及其他),但是人们总会发现,优美简洁的理论和惨痛的实现之间存在的断层:诸如自定义协议,自定义服务器,文件系统,冗余,等等等等。问题来了,我们怎样能把这个差距缩短一点?
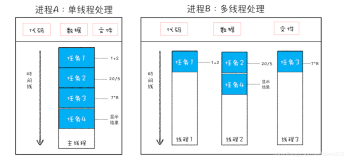
大规模并行计算
在我和 Michael Nielsen 进行了多次迭代、试错、深入的对话之后,一个念头突然闪现出来: HTTP + Javascript!如果简单的通过浏览器打开一个 URL 就能为计算任务( Map-Reduce )做贡献会怎样?你的社交网络肯定不会介意多开一个后台 tab 帮你压缩一两个数据集!
 与其关注高吞吐率的专有协议和高效的数据通道来分发和传递数据,我们可以用实战检验过的方法: HTTP 和你喜欢的浏览器。而且全世界还有无数的 Javascript 处理器 ——每个浏览器都可以执行。比起其他语言,它是一个完美的数据处理平台。
与其关注高吞吐率的专有协议和高效的数据通道来分发和传递数据,我们可以用实战检验过的方法: HTTP 和你喜欢的浏览器。而且全世界还有无数的 Javascript 处理器 ——每个浏览器都可以执行。比起其他语言,它是一个完美的数据处理平台。
Google 据说有数以百万计的服务器(而且还在猛增),这是一个惊人的数量。那想要组织一百万人,把他们的零碎计算时间贡献到其中该有多难?我认为这并不是难以实现的,毕竟开始的门槛很低。如果能做到,虽然计算的效率会很低,不过我们会得到一个超大的集群,可以让我们解决一些以前完全做不到的问题。
浏览器中的客户端计算
除了数据的存储和分发,计算任务中最重要的一块就是 CPU 时间。但是,通过把数据分割成可管理的小块,我们可以很容易构造一个基于 HTTP 的工作流,让用户的浏览器为我们处理这些事:
整个过程包括简单的 4 步。首先,客户端向追踪计算进度的 job 服务器申请加入集群。然后服务器分配一个工作单元,把客户端重定向(例如 301 HTTP Redirect)到一个包含数据和 Javascript map/reduce 方法的 URL。下面是一个简单的分布式 word-count 示例:
<html>
<head>
<script type="text/javascript">
function map() {
/* count the number of words in the body of document */
var words = document.body.innerHTML.split(/\n|\s/).length;
emit('reduce', {'count': words});
}
function reduce() {
/* sum up all the word counts */
var sum = 0;
var docs = document.body.innerHTML.split(/\n/);
for each (num in docs) { sum+= parseInt(num) > 0 ? parseInt(num) : 0 }
emit('finalize', {'sum': sum});
}
function emit(phase, data) { ... }
</script>
</head>
<body onload="map();">
... DATA ...
</body>
</html>
一旦页面加载和 Javascript 被执行之后(因为有了 Javascript VM wars,这个过程越来越快了),结果被发回( POST )job 服务器,上述过程不断重复,直到所有任务( map 和 reduce )完成。所以加入集群只需要简单的打开一个 URL,而分发由 HTTP 协议完成。
用 Ruby 写一个简单的 job 服务器
最后的一块拼图是 job 服务器,用来协调分发的工作流。借助 Sinatra web framework ,只需要如下 30 行 Ruby 代码:
require "rubygems"
require "sinatra"
configure do
set :map_jobs, Dir.glob("data/*.txt")
set :reduce_jobs, []
set :result, nil
end
get "/" do
redirect "/map/#{options.map_jobs.pop}" unless options.map_jobs.empty?
redirect "/reduce" unless options.reduce_jobs.empty?
redirect "/done"
end
get "/map/*" do erb :map, :file => params[:splat].first; end
get "/reduce" do erb :reduce, :data => options.reduce_jobs; end
get "/done" do erb :done, :answer => options.result; end
post "/emit/:phase" do
case params[:phase]
when "reduce" then
options.reduce_jobs.push params['count']
redirect "/"
when "finalize" then
options.result = params['sum']
redirect "/done"
end
end
# To run the job server:
# > ruby job-server.rb -p 80
bmr-wordcount - 浏览器 Map-Reduce: word-count 示例
就这些。启动服务器然后在浏览器里打开 URL 。剩下的完全自动化,并且很容易并行 —— 打开更多的浏览器就好了。加上一些负载均衡,数据库,它就真的可以干活了,很酷吧。