

对于了解深度学习、自然语言处理NLP的读者来说,Word2Vec可以说是家喻户晓的工具,尽管不是每一个人都用到了它,但应该大家都会听说过它——Google出品的高效率的获取词向量的工具。
I. Word2Vec不可思议?
大多数人都是将Word2Vec作为词向量的等价名词,也就是说,纯粹作为一个用来获取词向量的工具,关心模型本身的读者并不多。可能是因为模型过于简化了,所以大家觉得这样简化的模型肯定很不准确,所以没法用,但它的副产品词向量的质量反而还不错。没错,如果是作为语言模型来说,Word2Vec实在是太粗糙了。
但是,为什么要将它作为语言模型来看呢?抛开语言模型的思维约束,只看模型本身,我们就会发现,Word2Vec的两个模型 —— CBOW和Skip-Gram —— 实际上大有用途,它们从不同角度来描述了周围词与当前词的关系,而很多基本的NLP任务,都是建立在这个关系之上,如关键词抽取、逻辑推理等。这几篇文章就是希望能够抛砖引玉,通过介绍Word2Vec模型本身,以及几个看上去“不可思议”的用法,来提供一些研究此类问题的新思路。
说到Word2Vec的“不可思议”,在Word2Vec发布之初,可能最让人惊讶的是它的Word Analogy特性,即诸如 king-man ≈ queen-woman 的线性特性,而发布者Mikolov认为这个特性意味着Word2Vec所生成的词向量具有了语义推理能力,而正是因为这个特性,加上Google的光环,让Word2Vec迅速火了起来。但很遗憾,我们自己去训练词向量的时候,其实很难复现这个结果出来,甚至也没有任何合理的依据表明一份好的词向量应该满足这个Word Analogy特性。不同的是,这里笔者介绍的若干个用途,可复现性是非常高的,读者甚至在小语料中训练一个Word2Vec模型,然后也能取到类似的结果。
II. 数学原理:网络资源
有心想了解这个系列的读者,有必要了解一下Word2Vec的数学原理。当然,Word2Vec出来已经有好几年了,介绍它的文章数不胜数,这里我推荐peghoty大神的系列博客:
http://blog.csdn.net/itplus/article/details/37969519
另外,本博客的《词向量与Embedding究竟是怎么回事?》也有助于我们理解Word2Vec的原理。
为了方便读者阅读,我还收集了两个对应的PDF文件:
word2vector中的数学原理详解.pdf
Deep Learning 实战之 word2vec.pdf
其中第一个就是推荐的peghoty大神的系列博客的PDF版本。当然,英文好的话,可以直接看Word2Vec的原始论文:
但个人感觉,原始论文并没有中文解释得清晰。
III. 数学原理:简单解释
简单来说,Word2Vec就是“两个训练方案+两个提速手段”,所以严格来讲,它有四个备选的模型。
两个训练方案分别是CBOW和Skip-Gram,如图所示
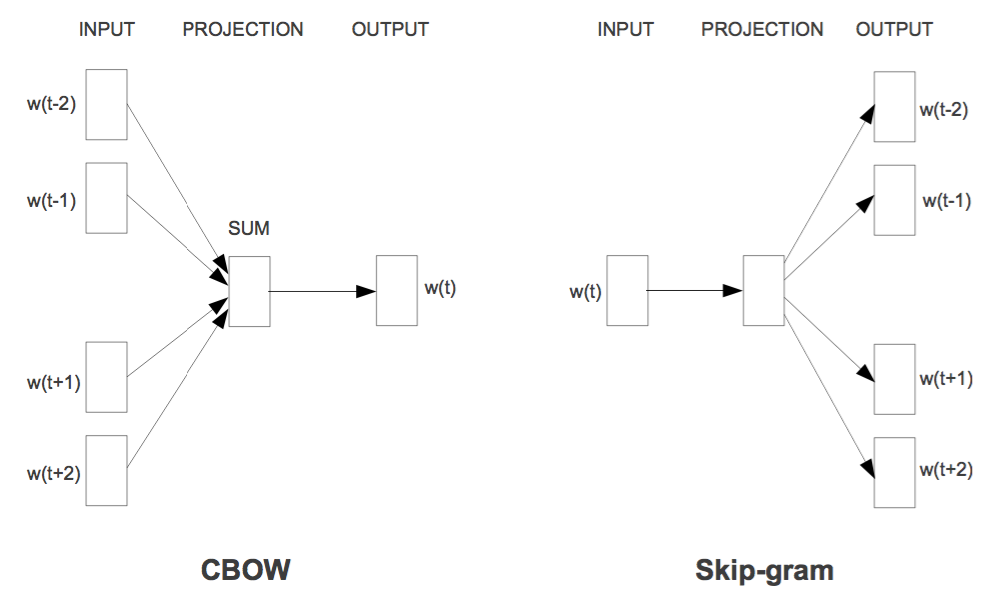
用通俗的语言来说,就是“周围词叠加起来预测当前词”(
)和“当前词分别来预测周围词”(
),也就是条件概率建模问题了;两个提速手段,分别是层次Softmax和负样本采样。层次Softmax是对Softmax的简化,直接将预测概率的效率从
降为
,但相对来说,精度会比原生的Softmax略差;负样本采样则采用了相反的思路,它把原来的输入和输出联合起来当作输入,然后做一个二分类来打分,这样子我们可以看成是联合概率
和
的建模了,正样本就用语料出现过的,负样本就随机抽若干。更多的内容还是去细看peghoty大神的系列博客比较好,我也是从中学习Word2Vec的实现细节的。
最后,要指出的是,本系列所使用的模型是“Skip-Gram + 层次Softmax”的组合,也就是要用到 这个模型的本身,而不仅仅是词向量。所以,要接着看本系列的读者,需要对Skip-Gram模型有些了解,并且对层次Softmax的构造和实现方式有些印象。

