3.3 如何实施TiP
第一步是让测试经理也支持这些指导原则,然后再与团队的资深成员紧密合作,并根据所有主要功能区对原则进行评审。这一过程保证了我们之间没有隔阂,并且能够很好地在不同领域利用测试人员的专业技术知识。这个虚拟团队定义了40多个场景,这些场景代表了视为最重要的功能的宽度。
【真知灼见】
避免白费力气做重复的工作;尽可能地复用现有的自动化测试件。
第二步是决定如何将上面的40多个场景在整个产品系统中具体实施。如前所述,我们要尽可能地重用已有的资产,所以我们集中精力尽快定义和开发出所需的测试。最初实施时,我们决定使用现有的测试执行框架来运行测试,那样的话,就可以重用现有的测试报告工具、机器管理等,这也使得我们可以利用现有的自动化测试库。
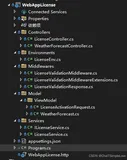
我们的第一次实施的具体结构见图3-1。每小时执行引擎都会自动部署一台新机器,并安装相应的客户库、工具和测试,也安装一个“云定义”文件,该文件以一种通用方法描述了目标环境。测试本身并不知道目标环境的任何信息,通过这种抽象的方法我们可以指向某个数据中心、某个逻辑单元或者某台特定的机器(实际上现在是在预检入工作流中完成的)。
【小窍门】
另一种级别的抽象:将测试从机器和它们所运行的环境中分离出来。
图3-1是TiP系统拓扑结构的第一个版本,具有如下特点:
1)部署一台自动化测试主机,在特定的数据中心运行测试。
2)将测试结果发送到Focus测试执行(Focus Test Execution, FTE)服务器上,它将对测试结果进行处理(Focus是工具的名称)。
3)结果将保存到一个公用数据库上。
4)在运行过程中,TiP诊断服务周期性地对结果进行收集。
5)收集的结果会返回给数据库。
6)遇到问题时,产品bug会自动显示出来。
7)诊断服务给管理区发送一个请求信息,包含分页调度和报警信号的逻辑信息。
8)请求信息被发送到SCOM根管理系统(Root Management System,RMS)进行处理。SCOM的警报解除了,同时启动相应的响应处理机制。

图3-1 Exchange TiP第一个版本的系统拓扑结构
最初,在将服务提供(为用户注册和新建邮箱)给新用户之前,我们通过测试来验证服务的新部署。后来我们发现,尽管如此,与传统的以软件为中心的世界中我们只需保证软件质量不同的是,我们现在所经营的服务是一直变化的。不仅配置(域名系统(Domain Name System, DNS)、补丁、新的租户等)经常发生变化,更新的变化也很多,这意味着随着时间的增长,可能会遇到没有测试过或预料到的更新或者小的配置变动。根据我们的经验,即便是对产品来说安全的改变也可能会使服务中断。这也是为什么我们决定采用连续运行测试的方式,而不仅仅只是在进行部署的时候运行一次。
TiP具有一点类似产品服务监控器的作用;然而,相比于传统的轻量级服务监控,我们所运行的测试集更深入,端到端(end-to-end)场景鲁棒性更强。同样,TiP测试就变成了煤矿中的金丝雀,能对潜在用户面临问题提供更早的警报。过去是使用其他构建在Microsoft System Center顶端的基于代理的监控解决方案,然而,这些代理只是停留在单机器层面。TiP测试作为最终用户来运行,并且当它们使用性能降低的时候,会发出警告。
【真知灼见】
不要仅仅通过一种途径来实施自动化,尽可能使用多种有用的方法。不同方法之间可以互补并且往往比单独使用一个方法更有效。
作为我们整个决策的一部分,我们决定停止使用第三方服务,像Gomez和Keynote。虽然在整个决策中非常重要,这种类型的监控关注的主要是一些比较片面的场景(比如登录)的服务可用性。与此同时,TiP场景的宽度比其他测试要小(高级测试只有40个测试用例,而实验室运行的端到端的场景中有70 000多个测试),所以比一般服务的深度肯定是要大些。
通过使用自己的基础设施,例如,我们可以很容易地给手机的ActiveSync协议添加新的验证信息,这在传统的黑盒监控环境中是很难做到的,因为协议具有复杂性。另一方面是敏捷度,根据产品环境和测试本身,在数据中心我们可以进行更改并对更改作出快速回应。因此,正如只关注单机器的SCOM监控基础设施一样,这些TiP测试对外部黑盒测试是一种补充,而不是取代它。