
下载地址:http://pan38.cn/ia146c031
项目编译入口:
package.json
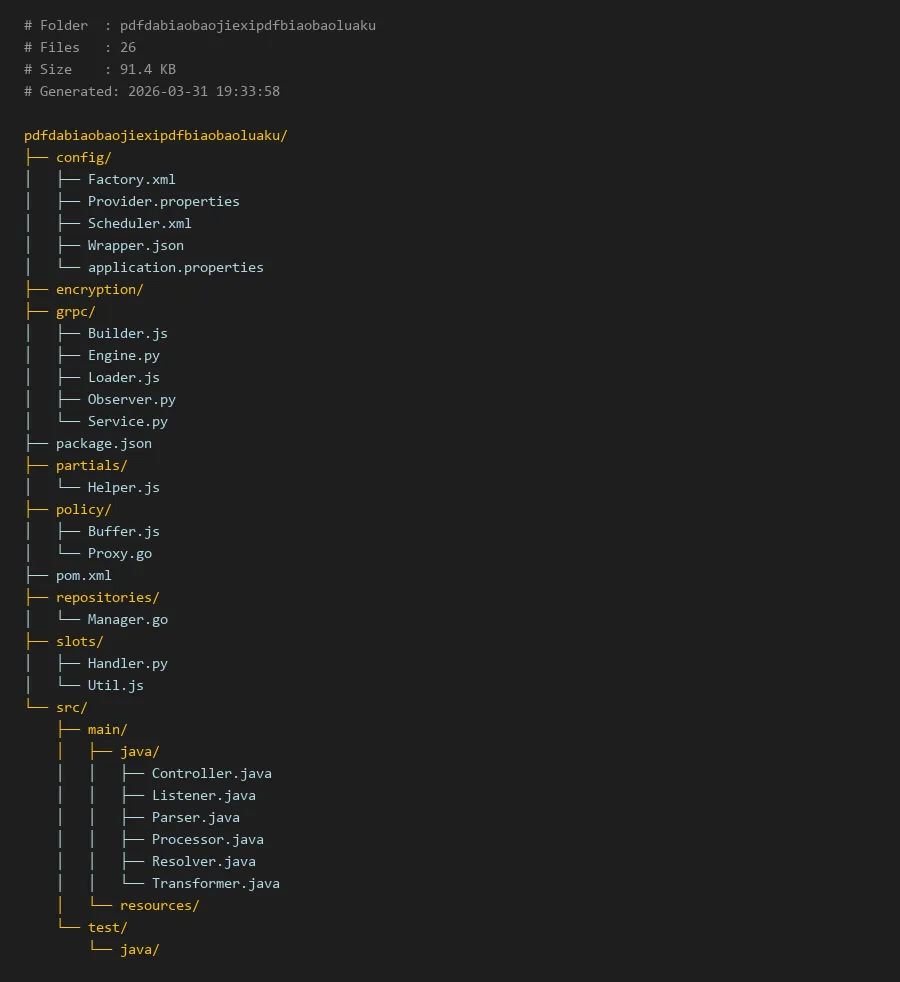
# Folder : pdfdabiaobaojiexipdfbiaobaoluaku
# Files : 26
# Size : 91.4 KB
# Generated: 2026-03-31 19:33:58
pdfdabiaobaojiexipdfbiaobaoluaku/
├── config/
│ ├── Factory.xml
│ ├── Provider.properties
│ ├── Scheduler.xml
│ ├── Wrapper.json
│ └── application.properties
├── encryption/
├── grpc/
│ ├── Builder.js
│ ├── Engine.py
│ ├── Loader.js
│ ├── Observer.py
│ └── Service.py
├── package.json
├── partials/
│ └── Helper.js
├── policy/
│ ├── Buffer.js
│ └── Proxy.go
├── pom.xml
├── repositories/
│ └── Manager.go
├── slots/
│ ├── Handler.py
│ └── Util.js
└── src/
├── main/
│ ├── java/
│ │ ├── Controller.java
│ │ ├── Listener.java
│ │ ├── Parser.java
│ │ ├── Processor.java
│ │ ├── Resolver.java
│ │ └── Transformer.java
│ └── resources/
└── test/
└── java/
pdfdabiaobaojiexipdfbiaobaoluaku:PDF破大防表情包解析与提取技术详解
简介
在当今数字化内容传播中,PDF文件已成为信息交换的重要载体。然而,当我们需要从PDF中提取特定内容——尤其是那些令人会心一笑的"pdf破大防表情包"时,传统方法往往力不从心。本项目pdfdabiaobaojiexipdfbiaobaoluaku正是为解决这一痛点而生,它是一个专门用于解析PDF文件并提取其中表情包资源的工具库。
本项目采用模块化设计,支持多种编程语言,能够高效处理PDF中的图像资源。无论是单个表情包还是批量提取,都能轻松应对。下面我们将深入探讨其核心模块,并通过具体代码示例展示如何实现"pdf破大防表情包"的自动化提取。
核心模块说明
1. 配置管理模块 (config/)
该模块负责管理应用程序的所有配置,包括解析参数、输出格式、图像处理选项等。通过统一的配置管理,确保整个解析流程的一致性。
2. 图像处理模块 (slots/)
这是项目的核心处理单元,包含PDF解析、图像识别和提取功能。Handler.py负责主要的PDF解析逻辑,而Util.js提供辅助的图像处理功能。
3. 服务层模块 (grpc/)
提供分布式处理能力,支持多节点协同工作。当需要处理大量PDF文件时,可以通过gRPC服务进行任务分发和结果汇总。
4. 策略模块 (policy/)
定义解析策略和缓存机制,优化处理性能。Buffer.js管理内存缓存,Proxy.go实现代理模式,提高重复内容的处理速度。
5. 存储模块 (repositories/)
负责提取结果的存储管理,支持多种存储后端,确保提取的"pdf破大防表情包"能够安全保存。
代码示例
项目初始化与配置
首先,让我们看看如何初始化项目并加载配置:
// 使用partials/Helper.js中的工具函数初始化项目
const {
initProject } = require('./partials/Helper.js');
// 初始化项目配置
const projectConfig = initProject({
pdfPath: './input/sample.pdf',
outputDir: './output/expressions',
imageFormat: 'png',
quality: 90,
extractStrategy: 'aggressive' // 积极提取模式,适合表情包提取
});
// 加载应用程序配置
const fs = require('fs');
const appConfig = JSON.parse(fs.readFileSync('./config/Wrapper.json', 'utf8'));
console.log('项目初始化完成,开始解析PDF破大防表情包...');
PDF解析与图像提取
接下来是核心的PDF解析代码,使用Python实现:
```python
slots/Handler.py - 主要PDF处理类
import fitz # PyMuPDF
from PIL import Image
import os
class PDFExpressionExtractor:
def init(self, config_path='./config/application.properties'):
self.config = self._load_config(config_path)
self.extracted_count = 0
def _load_config(self, config_path):
"""加载配置文件"""
config = {}
with open(config_path, 'r') as f:
for line in f:
if '=' in line and not line.startswith('#'):
key, value = line.strip().split('=', 1)
config[key] = value
return config
def extract_expressions(self, pdf_path, output_dir):
"""
从PDF中提取所有图像(特别是表情包)
参数:
pdf_path: PDF文件路径
output_dir: 输出目录
"""
if not os.path.exists(output_dir):
os.makedirs(output_dir)
doc = fitz.open(pdf_path)
expression_list = []
print(f"开始解析PDF: {pdf_path}")
print(f"总页数: {len(doc)}")
for page_num in range(len(doc)):
page = doc[page_num]
image_list = page.get_images()
for img_index, img in enumerate(image_list):
xref = img[0]
base_image = doc.extract_image(xref)
if self._is_expression_image(base_image):
image_bytes = base_image["image"]
image_ext = base_image["ext"]
# 生成唯一文件名
filename = f"expression_{page_num+1}_{img_index+1}.{image_ext}"
output_path = os.path.join(output_dir, filename)
# 保存图像
with open(output_path, "wb") as f:
f.write(image_bytes)
expression_list.append({
'page': page_num + 1,
'index': img_index + 1,
'path': output_path,
'size': len(image_bytes)
})
self.extracted_count += 1
print(f"提取表情包: {filename} (大小: {len(image_bytes)} bytes)")
doc.close()
return expression_list
def _is_expression_image(self, image_data):
"""
判断是否为表情包图像
基于图像特征进行简单判断
"""
# 获取图像尺寸
from io import BytesIO
img = Image.open(BytesIO(image_data["image"]))
width, height = img.size
# 表情包通常具有特定宽高比和尺寸
aspect_ratio = width / height
# 常见的表情包特征:接近正方形,尺寸适中
is_squareish =
