
这两年,AI 编程、Agent、自动化智能体被反复讨论。 但在工程一线,一个问题越来越清晰:
模型能力提升得很快,但系统并不会因此自动变稳定。
代码能写出来,不代表系统能上线; 结果看起来对,不代表过程是可控的。
对测试开发来说,这不是“被取代”的信号,而是一个非常明确的角色变化。
一、为什么 AI 编程在不同团队里,效果差距巨大
很多争论停留在“AI 编程有没有用”, 但真正有经验的团队,关心的是另一件事:
它在什么阶段是效率工具,在什么阶段是风险放大器。
AI 编程效果的分水岭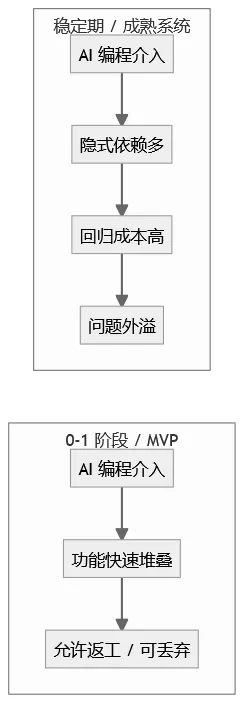
这张图想表达的只有一句话:
AI 的“好用”,高度依赖系统是否允许失败。
二、真正能落地的 AI 编程,靠的不是模型,而是工程约束
成熟团队在用 AI 时,有一个共同前提:
从不假设 AI 是可靠的。
- PR 行数限制,本质是给测试留生存空间
“单个 PR 控制在 500 行以内”,不是为了限制开发效率,而是为了:
让测试知道该测什么
让回归能覆盖到真实风险
让问题出现后能快速定位
为什么 PR 变大,测试就失效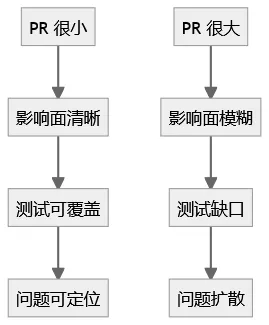
这不是 AI 的问题,是工程规模失控的问题。
三、AI 系统真正的核心不是 Prompt,而是 Evaluation
很多团队把时间花在“怎么写 Prompt”, 但一线团队更关心的是:
改了之后,会不会悄悄把别的地方搞坏。
AI 系统里的 Evaluation 闭环
这套流程,对测试开发来说非常熟悉:它本质就是一条自动化回归流水线。
区别只在于:
断言从 if/else
变成了评分标准(Rubric)
四、Context Engineering,其实是一个“状态治理”问题
在 Agent 系统里,Context 不是普通参数,而是一种持续累积的状态。
而测试最怕的,正是这种状态。
Context Rot = 状态污染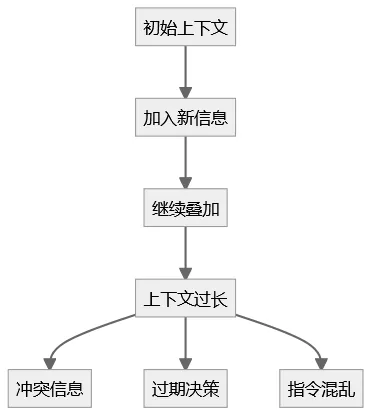
这和一个无法 reset 的状态机几乎是同一类问题。
工程上的三种解法,本质都是“管状态”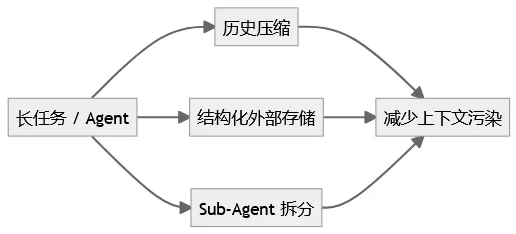
五、为什么文件系统成了 Agent 的“工程友好型底座”
相比一次性 Tool Call,文件系统非常“测试友好”。
Tool Call vs 文件系统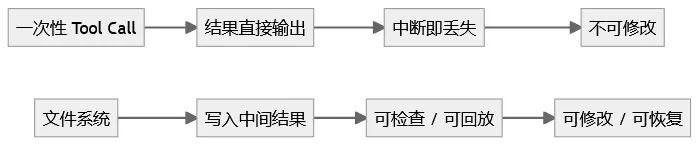
对测试开发来说,文件系统解决的是一个关键问题:
我能不能验证 Agent 的每一步,而不是只看最终答案。
六、站在测试开发视角,角色正在发生什么变化
AI 并没有削弱测试的重要性,反而把问题提前暴露了。
测试开发角色的迁移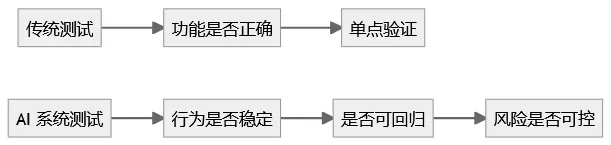
测试关注点,正在从“结果”走向“过程和系统行为”。
模型在变强,但工程规律没变
不管模型多聪明,有几件事始终成立:
系统一定会出错
状态一定会污染
不可测的东西,一定不可控
模型决定上限,测试和工程决定系统能不能长期跑下去。
在 Agent 时代, 测试开发不是边缘角色, 而是让系统敢于持续演进的那一层结构。
如果你不想只停留在“会点 AI”, 如果你希望真正进入 人工智能测试开发赛道, 如果你想让未来 3~5 年的技术方向更确定——

