
作用域和闭包是前端再基础不过的知识了!我们平常所写程序中很多都不一定是平铺的,有很多复杂的逻辑和函数以及模块之间的联系都会涉及到作用域和闭包。因此,对于前端来说,如果连作用域和闭包的关系都捋不清,那无形中总会写出各式各样的 bug ,这对于程序来说简直是一个巨大的灾难。
同时,在面试当中,也很容易被问到这一块的知识,比如:
this的不同应用场景,如何取值?- 手写
apply、call、bind函数。 - 实际开发中闭包的应用场景,举例说明。
- ……
所以,了解作用域和闭包,对于前端来说是一项必备的技能。接下来开始讲解作用域和闭包。
一、作用域
1、作用域、自由变量简介
(1)作用域定义
先抛出定义:
- 作用域,就是当访问一个变量时,即编译器在执行这段代码时,会首先从当前的作用域中查找是否有这个标识符,如果没有找到,就会去父作用域查找,如果父作用域还没有找到则继续向上查找,直到全局作用域为止。可理解为该上下文中声明的变量和声明的作用范围,可分为全局作用域、函数作用域和块级作用域。
- 注:
ES5中只存在两种作用域:全局作用域和函数作用域;ES6新增了块级作用域。 - 在
Javascript中,我们将作用域定义为一套规则,这套规则用来管理引擎如何在当前作用域以及嵌套子作用域中根据标识符名称进行变量(变量名和函数名)查找。
接下来我们用实例来了解作用域是什么?以及跟作用域相关的自由变量又是什么?
(2)作用域实例演示
先来看一段代码。
let a = 0;
function fn1(){
let a1 = 10;;
function fn2(){
let a2 = 100;
function fn3(){
let a3 = 100;
return a + a1 + a2 + a3;
}
fn3();
}
fn2();
}
fn1();
这段代码中的作用域分为以下四个层级。

那所谓作用域是什么呢?作用域代表的是一个变量,或者某个变量的合法使用范围。比如,上图中的 (1) 区域,其中 a 在全局被定义了,所以它可以被 (1) 的整个区域所使用。再来看下 (2) 区域, (2) 区域在函数 fn1 里面定义,所以 a1 只能被 (2) 下的整个区域所使用,以此类推 (3) 和 (4) 也是如此, a2 只能被区域 (3) 所使用, a4 只能被区域 (4) 所使用。
所以,作用域就类似于1234区域的这几个红框,即变量的一个合法使用范围,一旦这个变量跳出这个范围去使用,就会报错。
说完作用域,我们再来了解下自由变量。先来了解下自由变量的定义。
(3)自由变量定义
- 一个变量在当前作用域中没有定义。
- 向上级作用域,一层一层依次查找,直到找到为止。
- 如果到全局作用域都没找到,则报错
xxx is not undefined。
(4)自由变量实例演示
先来看一段代码(区域4有改变)。
let a = 0;
function fn1(){
let a1 = 10;;
function fn2(){
let a2 = 100;
function fn3(){
let a3 = 100;
return x + a + a1 + a2 + a3;
}
fn3();
}
fn2();
}
fn1();

我们定位到上图的区域(4),区域(4) 想要返回 x + a + a1 + a2 + a3 , 但是它当前区域只有 a3 被定义了,其余四个变量都没有被定义。所以除了 a3 之外, x、a、a1和a2 变量符合自由变量定义中的第一条规则,所以 x、a、a1 和 a2 这四个变量均为自由变量。
再继续看, x、a、a1和a2 向上级作用域一层一层的寻找,最终 a 在 区域(1) 找到, a1 在 区域(2) 找到, a3 在 区域(3) 找到,所以, a、a1 和 a2 也满足自由变量定义的第二条规则。
继续看,其它变量都找到了,只有 x 搜索到全局变量都没有找到对应的值,所以 x 满足自由变量的第三条规则。
综上所述,对于自由变量定义的三条规则中,只要变量满足其中一个条件都可算是自由变量。
了解完作用域和自由变量,我们再来了解作用域链。
2、作用域链简介
(1)作用域链定义
作用域链可以看成是将变量对象按顺序连接起来的一条链子。
每个执行环境中的作用域都是不同的。
当我们引用变量时,会顺着当前执行环境的作用域链,从作用域链的开头开始,依次往上寻找对应的变量,直到找到作用域链的尾部,报错
undefined。作用域链保证了变量的有序访问。
注意:作用域链只能向上访问,到 window 对象即被终止。
(2)作用域链实例演示
依然是上面那个例子,我们用一张图来表示作用域链的访问过程。

像上图这样,从第一步访问到第二、三、四步,最终访问不到则报错 undefined 。这样按顺序一步一步的访问,就像是一条链子,把变量对象按顺序连接起来,这就是作用域链。
3、全局作用域、函数作用域和块级作用域
(1)全局作用域
在程序中,定义一个变量,这个变量没有受到任何约束,在任何区域都可以使用,比如window对象,document对象……
(2)函数作用域
在函数中,定义一个变量,这个变量只能在函数内使用,超过函数的范围就会报错。
(3)块级作用域(ES6新增)
ES6 新增了块级作用域。那什么叫做块呢?可以理解为在任何有加大括号{}的区域都可以算是一个块。比如:
举例1:
if(true){
let x = 100;
}
console.log(x); //会报错
在上面这段代码中, if 语句后面花括号{}部分就算是一个块,块级作用域只能在当前的模块当中生效,所以,当if语句里面定义了 x 之后, x 只能在当前块内访问,不能跑出这个块,一旦跑出这个块以后,就不再生效。所以当打印 console.log(x) 的时候, x 并不在 if 语句的块内,所以会报错。
举例2:
function f1(){
let n = 5;
if(true){
let n = 10;
}
console.log(n); //10
}
在上面这段代码中, console.log(n) 中的 n 作用于 f1 函数当中,所以它会往 f1 函数这个块找,而此时有小伙伴可能会疑惑说, if 语句的块也有 n ,也属于 f1 函数里面。事实上,对于块级作用域来说,外层代码块不受内层代码块的影响,即外层干外层的事情,内层干内层的事情,所以 n 在外层,它会往外层找,与内层相互独立,互不干扰。
(4)var和let、const的区别
了解完全局、函数和块级作用域。我们来梳理下var和let、const的区别:
var是ES5语法,let、const是ES6语法,var有变量提升。var和let是变量,可以修改;const是常量,不可修改。let和const有块级作用域,而var没有。
二、闭包
1、闭包是什么?
(1)定义
闭包,是指函数内部再嵌套函数,且在嵌套的函数内有权访问另外一个函数作用域中的变量。
JavaScript 代码的整个执行过程,分为两个阶段,代码编译阶段与代码执行阶段。编译阶段由编译器完成,将代码翻译成可执行代码,这个阶段作用域规则会确定。执行阶段由JS引擎完成,主要任务是执行可执行的代码,执行上下文在这个阶段创建。

(2)本质
- 当前环境中存在指向父级作用域的引用
(3)特性
- 函数内再嵌套函数
- 内部函数可以引用外层的参数和变量
- 参数和变量不会被垃圾回收机制回收
(4)优缺点
- 优点:能够实现封装和缓存等。
- 缺点:①消耗内存;②使用不当会造成内存溢出。
(5)闭包的解决方法
- 在退出函数之前,将不使用的局部变量全部删除。
2、一般如何产生闭包?
闭包是作用域应用的特殊情况,有两种表现:
- 函数作为返回值被传递
- 函数作为参数被返回
(1)函数作为返回值被传递
function create(){
let a = 100;
return function(){
console.log(a);
}
}
let fn1 = create();
let a = 200;
fn1(); //100
从以上代码中可以看到,当执行 fn1 时,即执行 create() 函数,之后程序会执行 create() 函数,在 create() 函数当中, a 的值为 100 ,且结果是要返回一个函数的值。此时 console.log(a) 中的 a 为自由变量,在当前函数中找不到 a 的值,则会继续往上寻找,最终找到 a 的值为 100 ,返回结果 100 。
(2)函数作为参数被返回
function print(fn2){
let a = 200;
fn2();
}
let a = 100;
function fn2(){
console.log(a);
}
print(fn2); //100
从以上代码中可以看到,当执行 print(fn2) 函数时, fn2 是作为函数传递,此时执行 print(fn2) 函数,先找到 a 变量的值为 200 ,之后执行 fn2 函数,
而 fn2 函数在 print 函数外部,所以此时 fn2 函数中得到a变量应该往当前定义的地方向上级作用域查找,而不是在执行的地方查找。所以 a 变量向上级查找找到了 a 的值为 100 ,最终输出为 100 。
综上,得出以下结论:
在闭包中,所有自由变量的查找,是在函数定义的地方向上级作用域查找,而不是在执行的地方进行查找!!
3、闭包的应用场景
在日常的使用中,闭包通常有以下几种场景:
- 通过循环给页面上多个
dom节点绑定事件 - 做一个简单的cache工具,实现闭包隐藏数据,只提供
API - 函数柯里化
(1)通过循环给页面上多个dom节点绑定事件
我们先来看一段代码。
let i, a;
for(i = 0; i < 10; i++){
a = document.createElement('a');
a.innerHTML = i + '<br>';
a.addEventListener('click', function(e) {
e.preventDefault();
alert(i);
});
document.body.appendChild(a);
}
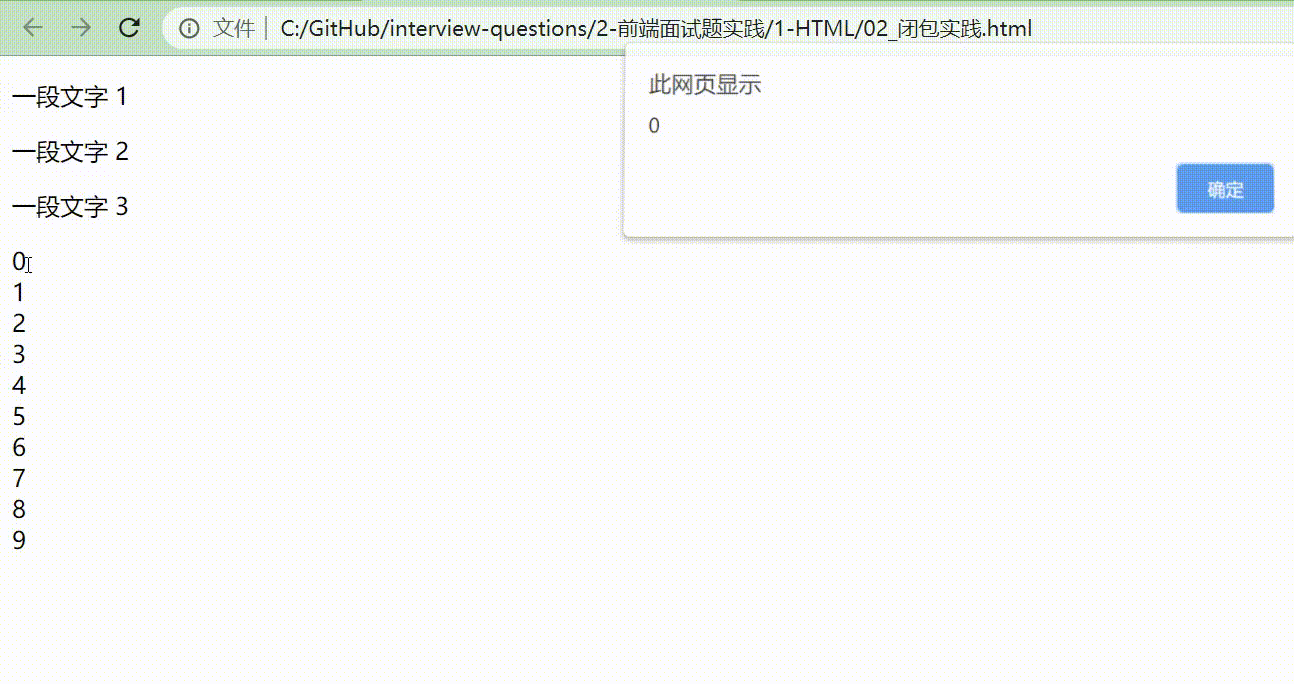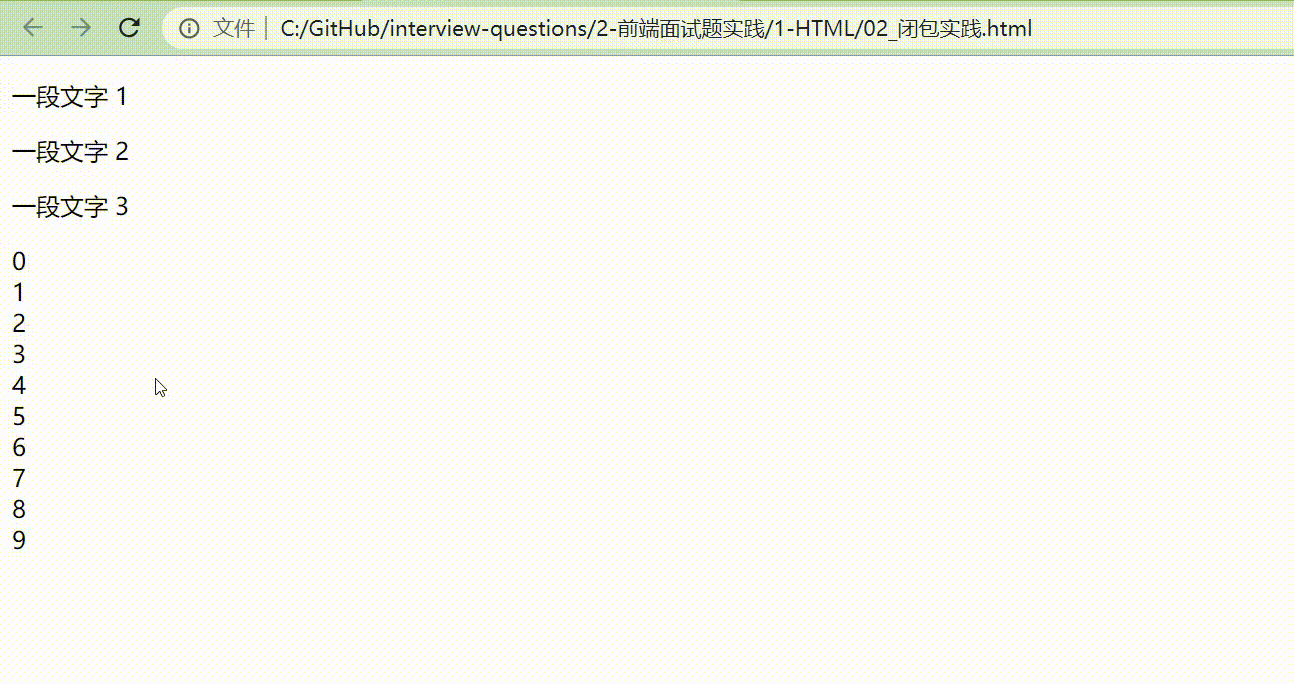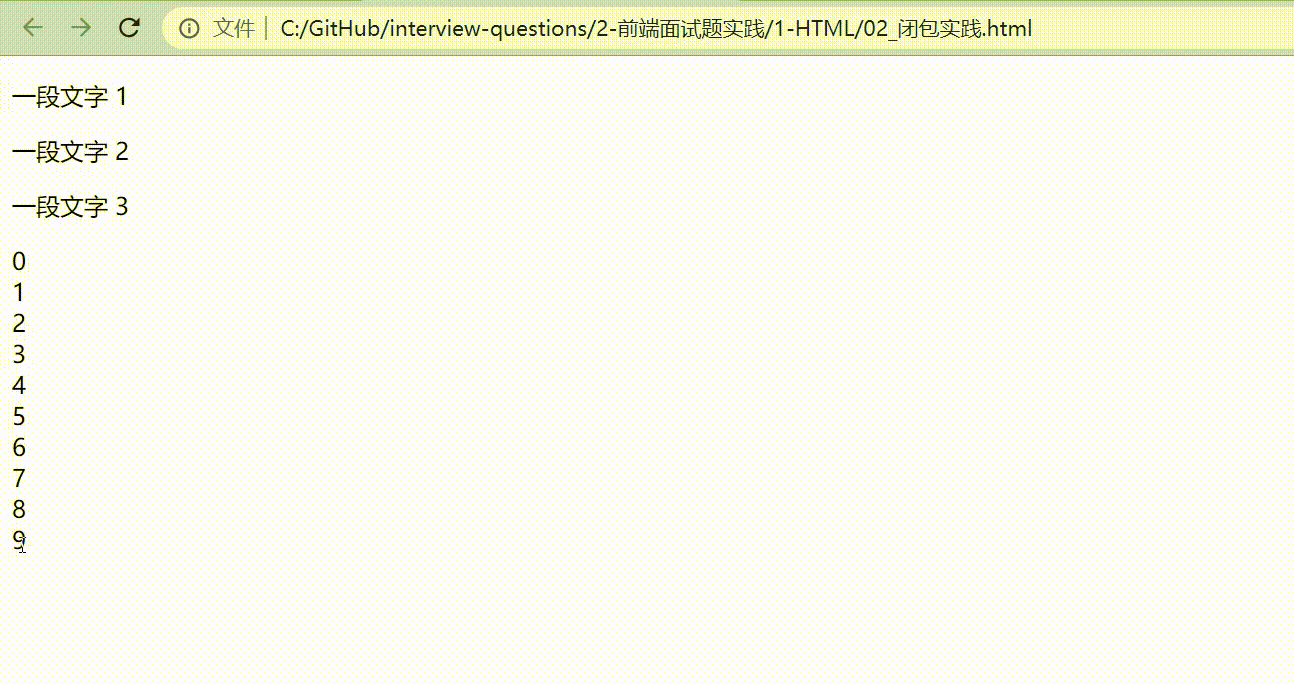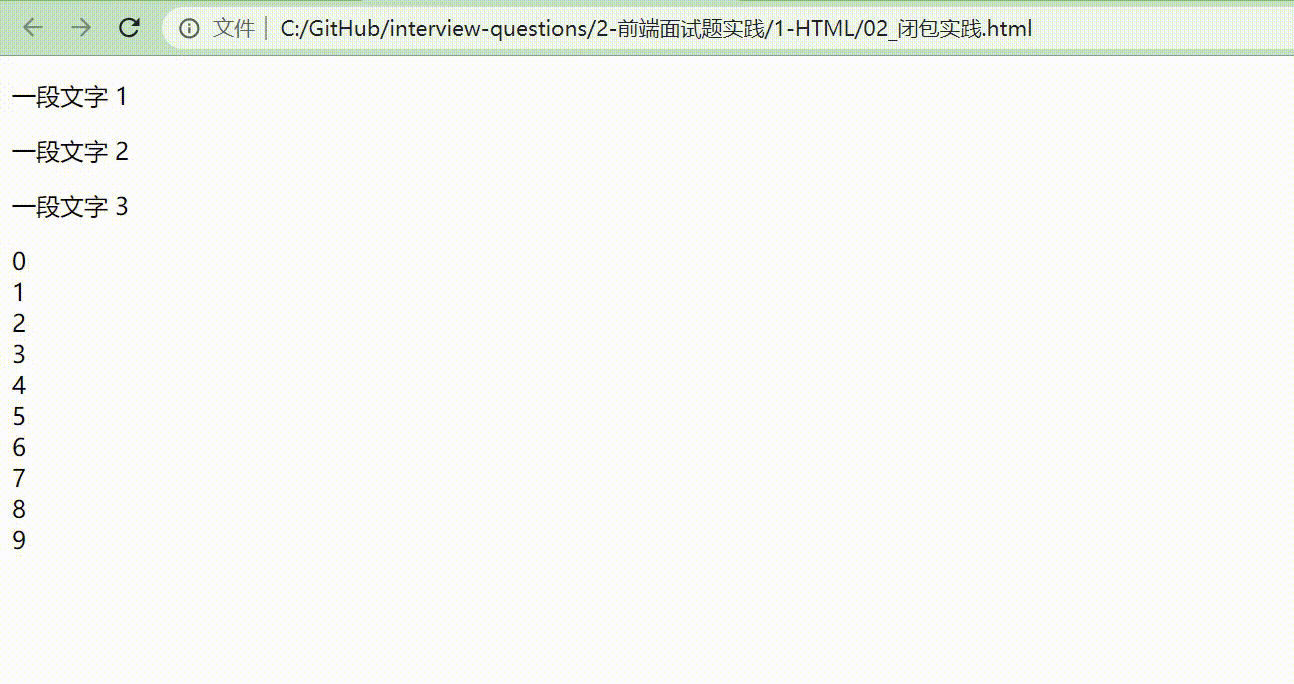
看完这段代码不妨先思考一下,在网页上呈现的形式是什么样的?当点击0~9的数字时,弹出来的数字是多少呢?我们来展示下结果。
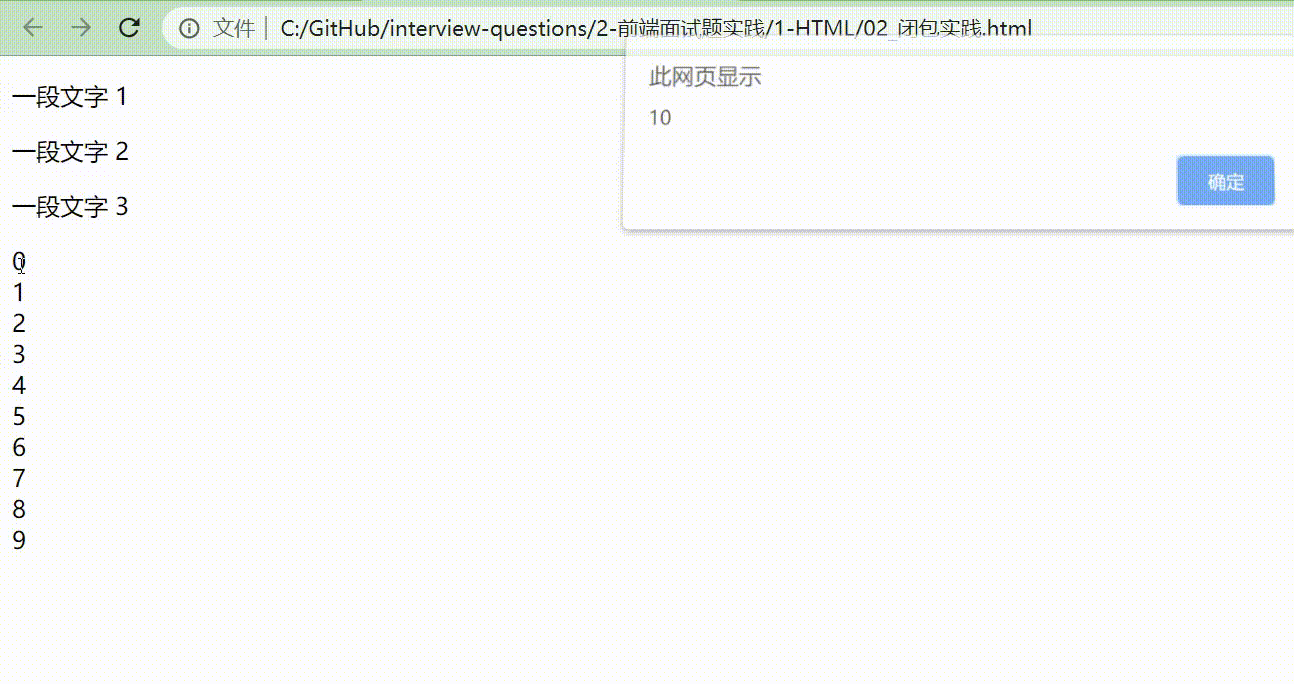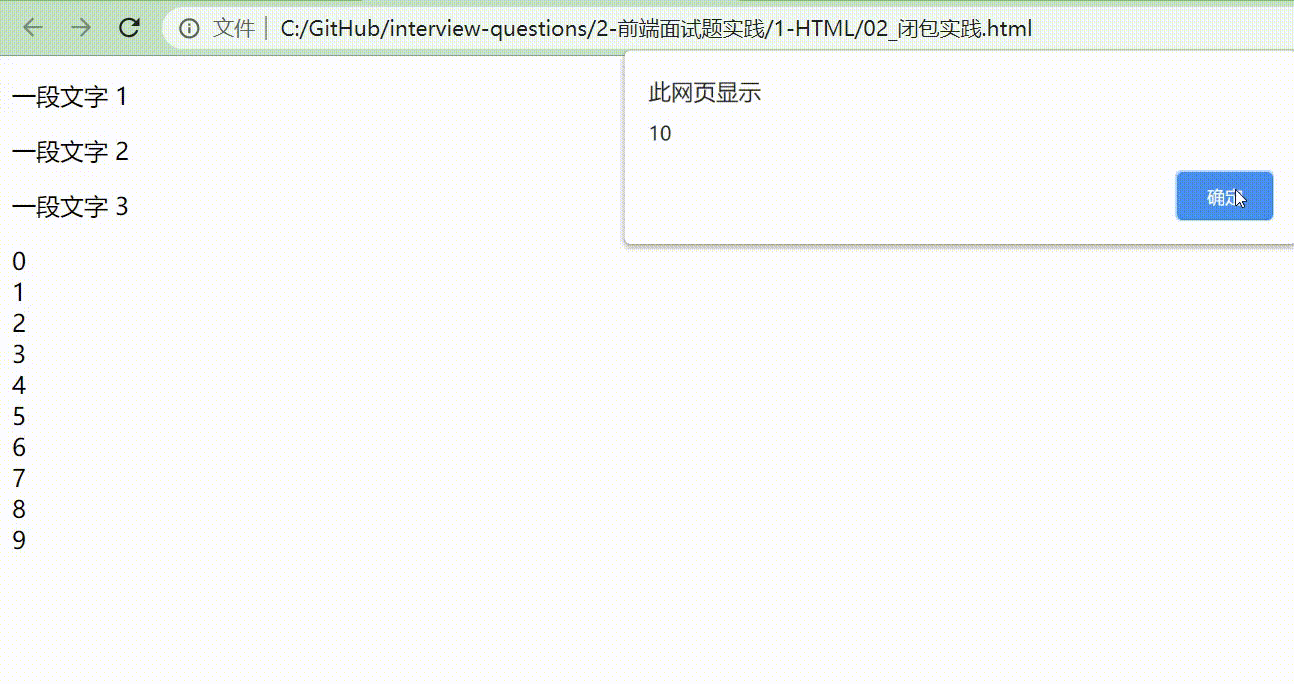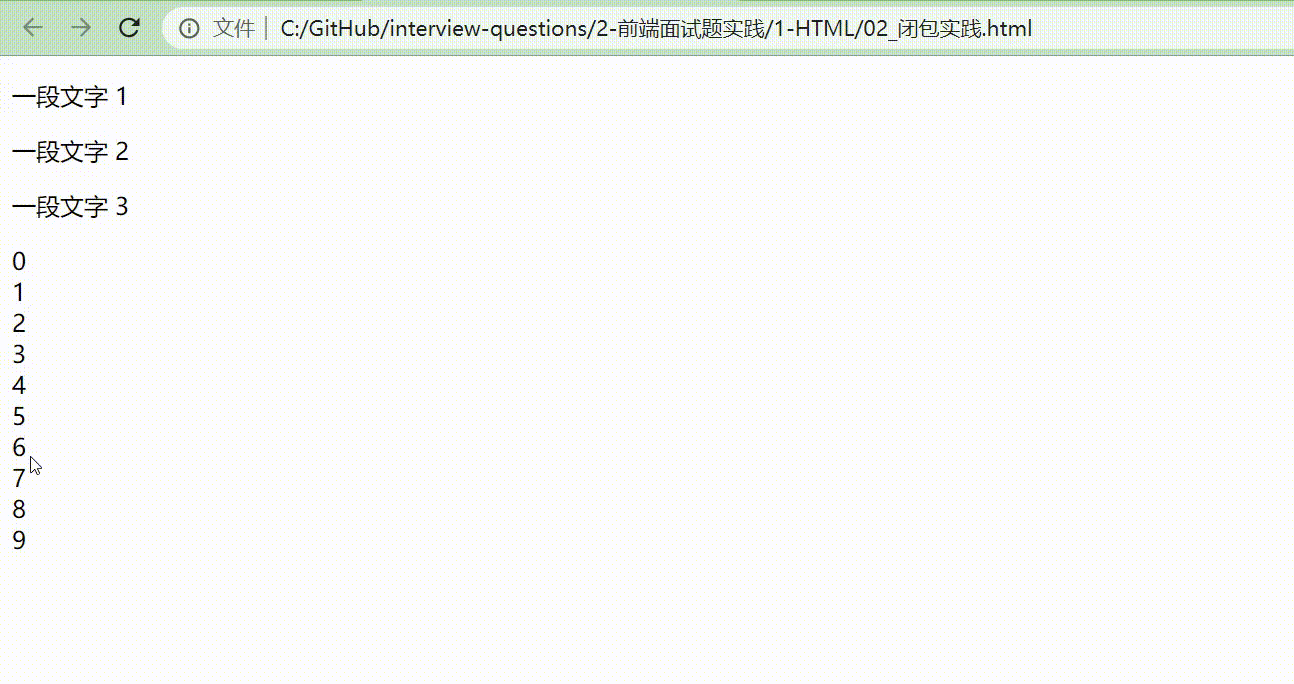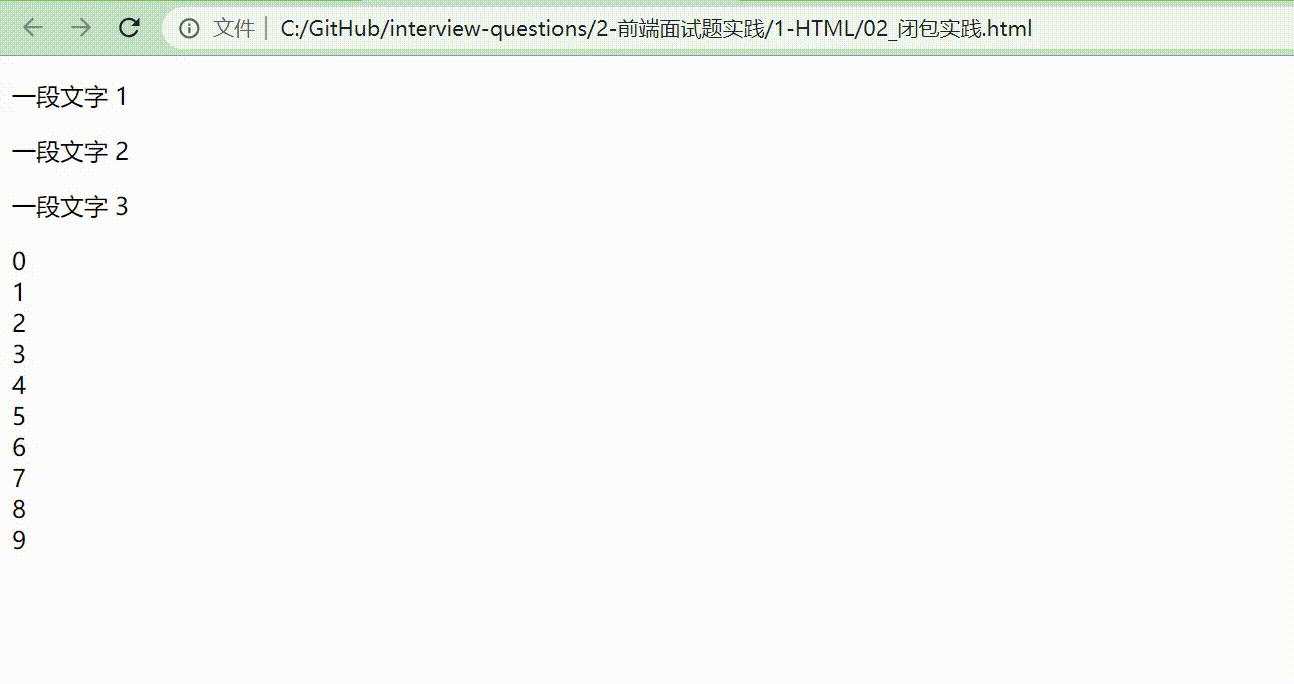
我们可以发现,我们想要的结果其实是点击0的时候弹出0,点击1的时候弹出1,但是好像跟我们想象的似乎还有点落差。那问题出在哪里呢?
其实,当把这段代码放在程序中时,很快就会被执行完,所以在for循环结束后,可能 a.addEventListener 还没有被执行(即下面这段代码),那 a.addEventListener 什么时候执行呢?那就是什么时候 click 什么时候执行。在我们还没有 click 之前,整个 for 循环可能已经循环结束,所以等到我们点击的时候,最终会打印出最后一个 for 执行时的结果:10 。
//不会立马执行的函数
a.addEventListener('click', function(e) {
e.preventDefault();
alert(i);
});
所以,问题出现了,我们应该怎样修改才能把它按照我们所想的进行显示呢。具体代码改动如下:
let a;
for(let i = 0; i < 10; i++){
a = createElement('a');
a.innerHTML = i + '<br>';
a.addEventListener('click', function(e) {
e.preventDefault();
alert(i);
});
document.body.appendChild(a);
}
改动后的效果展示如下图。
通过修改,可以看到,最终成功输出我们想要的结果。为什么呢?
因为把 i 放到 for 循环里面,并且用 let 定义,相当于把 let i = 0 放在 for 里面,定义了一个块级作用域。每次 for 循环执行的时候,都会形成一个新的块,每一个块都相互独立,执行到哪就显示到哪。一旦执行到 alert(i) 时,它就会往它的块级作用域里面寻找。
而如果把 i 放在全局作用域中, 全局作用域是针对所有的块,不会去考虑到每一个块的呈现形式是怎么样的。所以,把 i 放在块级作用域当中,读取块级作用域的内容,最终达到我们想要的效果。
(2)做一个简单的cache工具,实现闭包隐藏数据,只提供API
我们先来写一段代码。
//闭包隐藏数据,只提供 API
function createCache(){
const data = {
}; //闭包中的数据,被隐藏,不被外界访问
return{
set: function(key, val){
data[key] = val;
},
get: function(key, val){
return data[key];
}
}
}
const c = createCache();
c.set('a', 100);
console.log(c.get('a')); //100
console.log(c.delete('a')); //会报错
在这段代码中,我们在函数 createCache() 中定义了 get 和 set 方法,也就是说,在 createCache() 这个函数里,只提供了 set 和 get 方法,不再提供其他方法。所以在下面的 c 调用中,它只能调用 set 和 get ,而调用不了 delete ,因为 delete 在函数 createCache() 里面并没有提供出来,所以当 c 想要尝试去调用的时候,会报错。这样达到了闭包的目的,只提供想要提供的 API ,不提供的一律获取不了。
(3)函数柯里化
1)函数柯里化是什么?
函数柯里化是将一个接收多个参数的函数变为接收任意参数且最终返回一个函数的一种技术方式,其最终支持的是方法的连续调用,每次返回新的函数,在最终符合条件或者使用完所有的传参时终止函数调用。
2)主要作用和特点
函数柯里化的主要作用和特点就是参数复用、提前返回和延迟执行。
2)举例说明
比如:有一个add函数,用于返回所有参数的和,add(1, 2, 3, 4, 5)返回的是15,那么现在要将其变为类似 add(1)(2)(3)(4)(5) 或者 add(1)(2, 3, 4)(5) 的形式,并且功能相同,这就是柯里化想要达到的效果。
3)介绍柯里化的三种方式
在介绍柯里化的三种方式之前,先来了解下普通的add函数。
function add(){
let sum = 0;
let args = [...arguments];
for(let i in args){
sum += args[i];
}
return sum;
}
let res = add(1,2,3,4,5);
console.log(res); //15
普通的add()函数看着也没有什么问题,但是一旦数据的类型各式各样,就不是那么好处理了。于是引出柯里化来解决此类问题。
第一种add()函数柯里化方式
缺点:最后返回的结果是函数类型,但会被隐式转化为字符串,调用 toString() 方法
function add1(){
// 创建数组,用于存放之后接收的所有参数
let args = [...arguments];
function getArgs(){
args.push(...arguments);
return getArgs;
}
getArgs.toString = function(){
return args.reduce((a,b) => {
return a + b;
})
}
return getArgs;
}
let res = add1(1)(2)(3)(4)(5);
console.log(res); //f 15
第二种add()函数柯里化方式
缺点:需要在最后再自调用一次,即不传参调用表示已没有参数了
function add2(){
// 创建数组,用于存放之后接收的所有参数
let args = [...arguments];
return function(){
if(arguments.length === 0){
return args.reduce((a,b) => {
return a + b;
})
}else{
let _args = [...arguments];
for(let i = 0; i < _args.length; i++){
args.push(_args[i]);
}
return arguments.callee;
}
}
}
let res = add2(1)(2,3,4)(5)();
console.log(res); //15
第三种add()函数柯里化方式
缺点:在刚开始传参之前,设定总共需要传入参数的个数
function add3(length){
// slice(1)表示从第二个元素开始取值
let args = [...arguments].slice(1);
return function(){
args = args.concat([...arguments]);
if(arguments.length < length){
return add3.apply(this, [length - arguments.length].concat(args));
}else{
return args.reduce((a,b) => a + b);
}
}
}
let res3 = add3(5);
console.log(res3(1)(2, 3)(4)(5)); //15
三、写在最后
对于函数柯里化的内容我也还不是特别熟悉,写的内容仅供参考,待后面有深入了解之后还会再继续进行补充。
关于作用域、闭包以及闭包的一些应用场景就讲到这里啦!如果有不理解或者有误的地方也欢迎私聊我或加我微信指正~
- 公众号:星期一研究室
- 微信:MondayLaboratory
创作不易,如果这篇文章对你有用,记得点个 Star 哦~

