谷歌的研究人员提出了一种名为“百万专家Mixture”(Mixture of A Million Experts)的新型神经网络架构,该研究旨在解决传统Transformer模型在处理大规模数据时面临的计算和内存效率问题。这项研究的成果不仅在学术界引起了广泛关注,也为人工智能领域的进一步发展提供了新的思路。
首先,让我们来了解一下背景知识。Transformer模型是当前自然语言处理(NLP)任务的主流模型,它通过多层神经网络结构来捕捉输入数据的上下文信息。然而,随着模型规模的增大,Transformer模型的计算成本和内存占用也会线性增长,这给实际应用带来了很大的挑战。
为了解决这个问题,研究人员提出了一种名为“稀疏混合专家”(Sparse Mixture-of-Experts,MoE)的架构。这种架构通过将模型拆分为多个较小的专家模块,并根据输入数据的上下文信息动态地选择合适的专家进行计算,从而实现了计算资源的高效利用。然而,由于专家数量的限制和技术上的挑战,现有的MoE模型在实际应用中仍然存在一些问题。
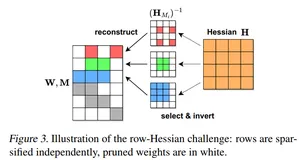
正是在这样的背景下,谷歌的研究人员提出了“百万专家Mixture”架构。与传统的MoE模型不同,这种新的架构利用了一种名为“产品键”(product key)的技术,实现了从大规模专家池中的高效检索。具体来说,他们将专家池中的每个专家表示为一个向量,并通过计算输入数据与这些向量的内积来选择最相关的专家进行计算。这种方式不仅提高了计算效率,还使得模型能够同时利用大规模专家池中的信息,从而提高了模型的性能。
实验结果表明,“百万专家Mixture”架构在语言模型任务上取得了显著的性能提升。与传统的密集前馈网络(Dense Feedforward Networks)和粗粒度MoE模型相比,“百万专家Mixture”架构在性能-计算权衡方面表现出了明显的优势。这意味着,通过使用这种新的架构,我们可以在保持计算效率的同时,进一步提高模型的规模和性能。
然而,尽管“百万专家Mixture”架构在理论上具有很大的潜力,但在实际应用中仍然存在一些挑战。首先,由于专家数量的大幅增加,模型的训练和优化变得更加复杂和困难。其次,如何有效地管理和部署如此大规模的模型也是一个亟待解决的问题。此外,尽管实验结果表明这种架构在语言模型任务上取得了性能提升,但对于其他类型的任务是否同样有效还有待进一步研究。