学习了RocketMQ的基本概念后,我们来看看RocketMQ最简单的使用场景。RocketMQ的服务器最简单的结构,必须包含一个NameServer和一个Broker。Producer把某个主题的消息发送给Broker,Consumer会去Broker中监听指定主题的消息,一旦发现,就会拉取并消费。在这个过程中,Producer和Consumer是通过NameServer才知道Broker部署在哪里,如果是 Broker Cluster 的情况,还要知道Master节点是哪些。换句话说,NameServer中保存着 Broker 的路由信息。
以上这些理解是对 RocketMQ 最浅显直观的理解。然后我们来试想一下,如果 NameServer 和 Broker 都是单节点的,那么一旦出现问题,首先是服务不可用了,其次,Producer和Consumer必然不知道Broker在哪里,消息就会发不出去也监听不到。Broker中尚未被消费的消息必然在故障期间不可订阅,影响消息实时性。为了避免这种情况的发生,我们需要搭建NameServer集群和 Broker 集群。
本文主要讲解【MQ集群】和【Broker Set】的搭建方法,其中也涉及到了名词解释和各组件作用的简单介绍。【MQ集群】和【Broker Set】的搭建,主要是为了最大程度上保证消息不丢失,从而做到 RocketMQ 的高可用。
1. 集群物理部署结构
以多Master多Slave模式为例,看一下RocketMQ集群物理部署结构,然后我们解释一下基本概念:
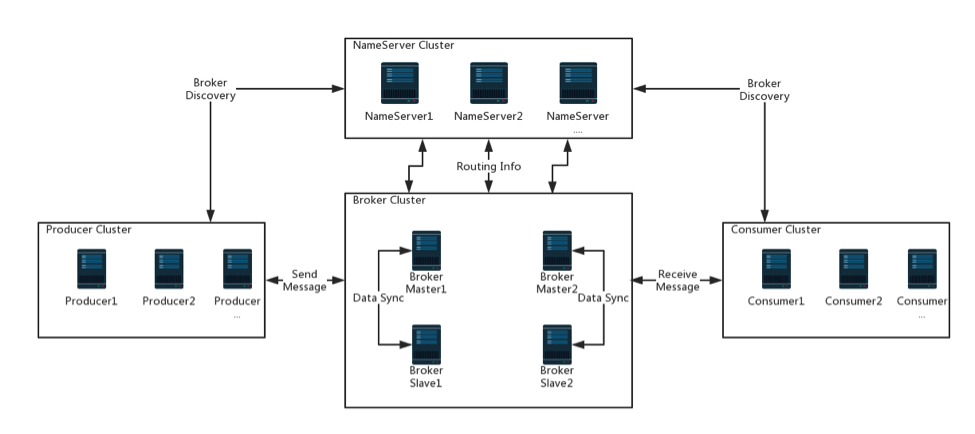
=== NameServer Cluster ===
NameServer是一个几乎无状态节点,可集群部署,节点之间无任何信息同步,只要保证一个实例存活就可以正常提供Broker的路由信息。如上图所示。
=== Broker Cluster ===
Broker分为Master和Slave,一个Master可以对应多个Slave,但是一个Slave只能对应一个Master。Master与Slave的对应关系通过指定相同的BrokerName,不同的BrokerId来定义,BrokerId为0表示Master,非0表示Slave。因为这些 Master 和 Slave 具有相同的 BrokerName,因此它们组成了一个 Broker Set。
Master Broker 也可以部署多个。每个Broker或者 Broker Set 与NameServer集群中的所有节点建立长连接,定时注册 Topic 信息到所有 NameServer。
=== Producer Cluster ===
Producer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并和提供Topic服务的Master建立长连接,且定时向Master发送心跳。Producer完全无状态,可集群部署。
=== Consumer Cluster ===
Consumer与NameServer集群中的其中一个节点(随机选择)建立长连接,定期从NameServer取Topic路由信息,并和提供Topic服务的Master、Slave建立长连接,且定时向Master、Slave发送心跳。Consumer既可以从Master订阅消息,也可以从Slave订阅消息,订阅规则由Broker配置决定。
2. 消息落盘和Broker数据同步
搭建 RocketMQ 集群的目的,是为了在最大程度上保证消息不丢失。下面我们来看看集群中有哪些特性,可以保障消息不丢失。
2.1 消息落盘
RocketMQ可以将内存中的数据存储在磁盘中,这种操作叫做磁盘刷新(Disk Flush)。
RocketMQ提供了以下两种模式:
- SYNC_FLUSH(同步刷盘):生产者发送的每一条消息,都在保存到磁盘成功后才回调告诉生产者成功。这种方式不会存在消息丢失的问题,但是有很大的磁盘IO开销,性能有一定影响
- ASYNC_FLUSH(异步刷盘):生产者发送的每一条消息并不是立即保存到磁盘,而是暂时缓存起来,然后就回调告诉生产者成功。随后再异步的将缓存数据保存到磁盘
如果我们选择异步刷盘,可选的有两种刷盘机制:
- 定期将缓存中更新的数据进行落盘
- 当缓存中更新的数据条数达到某一设定值后进行落盘。这种方式会存在消息丢失(在还未来得及同步到磁盘的时候宕机),但是性能很好。默认是这种模式。
2.2 Broker数据同步机制
Broker Replication(Broker 间数据同步/复制):
Broker Replication 指的就是在一个Broker Set 中,Slave Broker 获取/复制 Master Broker 数据的过程。这里再提一下 Broker Set 的概念。
Broker Set 中的Broker,有两种角色:
- 一种是master,即可以写也可以读,其brokerId=0,只能有一个
- 一种是slave,只允许读,其brokerId为非0
一个master与多个slave通过指定相同的BrokerName被归为一个 broker set(broker集)。通常生产环境中,我们至少需要2个broker set。
生产者发送的消息,总是先发到 Master Broker。对于消息发送成功的回调,Broker Set 有两种数据同步机制:
- Sync Broker(同步双写):生产者发送的每一条消息都至少同步复制到一个slave后,才返回告诉生产者成功,即“同步双写”
- Async Broker(异步复制):生产者发送的每一条消息只要写入master,就返回告诉生产者成功。然后再“异步复制”到slave
几种Broker集群搭建的最佳实践:
2M + NoSlave:两主(只有两个master,没有slave)
2M + 2S + Async:两主两从异步复制(两个master,两个slave,master数据通过异步复制到slave)
2M + 2S + Sync:两主两从同步双写(两个master,两个slave,数据同步双写到master和slave)
说明:
- 上述“2”只是说作为一个集群的最低配置数量,可以根据实际情况扩展
- 所有的刷盘操作全部默认为:ASYNC_FLUSH(异步刷盘)
3. 三种Broker集群方式优缺点
多Master模式(2M + NoSlave)
一个集群无Slave,全是Master,例如2个Master或者3个Master。
Master之间有负载均衡,Producer发出的消息会平均地落在Master机器上。但是对于一条消息,只会落在一台Master上。
优点:配置简单,单个Master宕机或重启维护时,对应用无影响。当磁盘配置为RAID10时,即使机器宕机不可恢复情况下,由于RAID10磁盘非常可靠,消息也不会丢(异步刷盘情况丢失少量消息,同步刷盘情况一条不丢)。性能最高。
缺点:单台机器宕机期间,这台机器上未被消费的消息在机器恢复之前不可订阅,消息实时性会受到影响。
多Master多Slave模式,异步复制(2M + 2S + Async)
每个Master配置一个Slave,有多对Master-Slave,HA采用异步复制方式,主备有短暂消息延迟,毫秒级。
优点:即使磁盘损坏,消息丢失的非常少,且消息实时性不会受影响,因为Master宕机后,消费者仍然可以从Slave消费,此过程对应用透明。另外,不需要人工干预。性能同多Master模式几乎一样。
缺点:Master宕机,磁盘损坏情况,会丢失少量消息。
多Master多Slave模式,同步双写(2M + 2S + Sync)
每个Master配置一个Slave,有多对Master-Slave,HA采用同步双写方式,主备都写成功,向应用返回成功。
优点:数据与服务都无单点,Master宕机情况下,消息无延迟,服务可用性与数据可用性都非常高。
缺点:性能比异步复制模式略低,大约低10%左右,发送单个消息的响应时间会略久。
4. 双主集群搭建
这里就以双主集群为例,进行搭建。
本小节是实际操作的Shell脚本和配置方法,这篇笔记省略。可以阅读参考资料来查看。
5. 双主双从集群搭建
前文已经搭建过双主结构的MQ集群,这种集群能满足我们日常的需要,但是有时候我们会遇到这样的场景,我们会要求消息实时返回,那么双主结构的能否满足我们的需求呢?
答案是,极端情况下消息做不到实时。试想有一台Master突然宕机或者网络不好而断开,而恰巧,宕机的Master节点中还有消息没有被消费,那么这个消息将不会被消费者获得,只有等宕机的Master节点重新启动,存在于该节点的消息才会被消费。在这段时间内,那些消息是不可订阅的,影响了实时性。
要想解决上面的问题,我们可以搭建双主双从的集群。让我们回顾一下,双主双从的数据同步机制,一般有两种:
- Sync Broker(同步双写):当生产端生产消息后,主节点和从节点都收到消息,并把消息都同时写入到本地后,才会回复消息
- Async Broker(异步复制):当主节点将数据保存到本地后,直接返回成功的消息,不关系从节点是否写入成功
我们可以看出,异步复制效率比较高,而同步双写更具有高可用性,数据也变得更加可靠。
下面我们搭建双主双从集群,并采用异步复制的方式。具体的搭建方式,请自行网上查找资料。再来看一下搭建完成后的结构图:
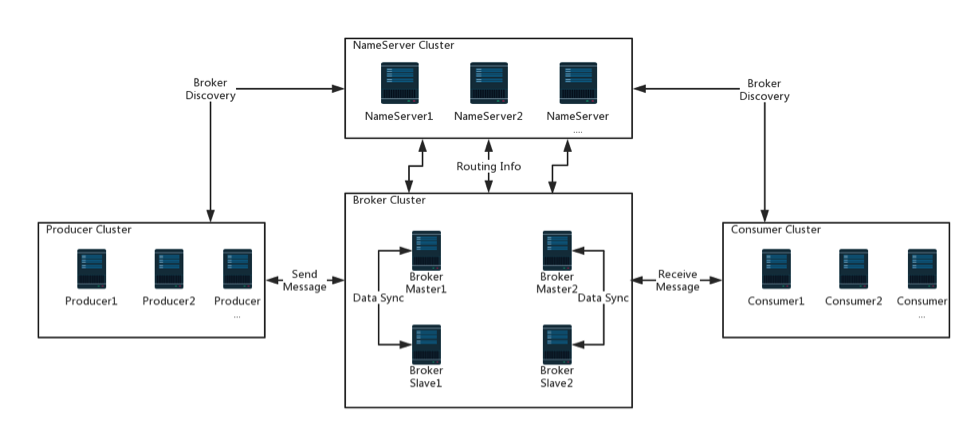
搭建完成后,对集群进行测试,还是以上图为例,可以看到下面的情况:
- 消息发送时已经进行了负载均衡,消息比较平均地落在了两个 Broker Set 上
- 在Broker运行时关掉 Broker Master1,Broker Master1 上还没有被消费的数据,会走 Broker Slave1被消费。消费完了再把 Broker Master1 启动,Master1 上没有被消费的数据不会被消费
- 在Broker运行时关掉 Broker Master1,之后的消息会被发到 Broker Master2 上
- 当Master1被加回来,Master1会重新成为主节点,并且与 Master2 还是有负载均衡效果
- Slave1 在 Master1 宕机期间,不会升级成为主节点
