
在谈到消息队列时,除了 Kafka、RabbitMQ、RocketMQ、ActiveMQ 等等之外,我希望你多了解一下 NSQ,之前已经写过一篇文章 《 NSQ 概述 》,但是内容过于简单,现在再多写一点 NSQ 相关的内容。
01
—
信息流
任何一个消息队列的信息流都可以抽象为:
生产者 >> MQ >> 消费者
NSQ 也不例外,如下图所示:

nsqd 是接受、排队、传递消息的守护进程,消息队列中的核心。
1
producer >> nsqd
生产者包装消息,将消息传递到 nsqd 中指定的 topic 。在 NSQ 中这一个步骤相当简单,通过 HTTP 接口就能完成:

发送消息必须指定 topic ,而 topic 的作用其实就是对消息进行逻辑上的分区。
接口 /pub 用来发送单条消息,其中的 defer 参数用来指定 NSQ 在接收到消息后延时多久再投递给消费者,例如订单规定时间内未支付则进行回收等场景就可以用到延时队列。接口 /mpub 用来一次发送多条消息。
相关配置 -max-msg-size : 单条消息的大小上限,默认 1048576 byte 即 1 M。
2
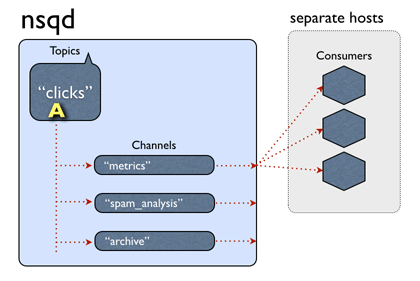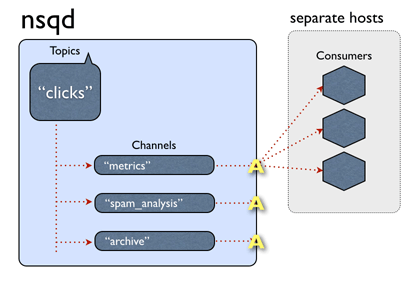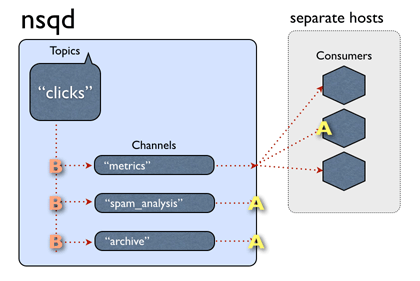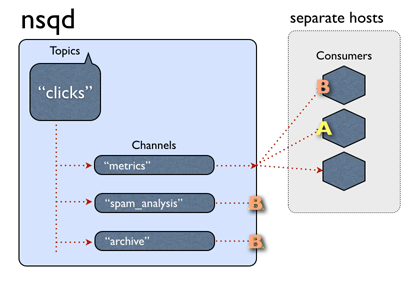
nsqd: topic >> channel
上面已经说过,topic 只是用来将消息进行逻辑划分,channel 才是真正存放消息的地方,而 nsqd 在接受到消息后,会将消息复制给所有与这个 topic 相连的 channel 并存放。
3
nsqd >> consumer
如上图所示,topic 的消息会被广播到所有与之相连的 channel ,但是同一个 channel 只会以负载均衡的方式把消息投递到与之相连的其中一个 consumer 消费者。
相关配置 max-in-flight : 一个 consumer 一次最多处理的消息数量,默认为一条。
02
—
消息处理
在实际情况下,nsqd 与 consumer 之间的消息处理并没有那么简单。
先来看看详细的过程:

如上图所示,consumer 需要先连接到 nsqd,并且订阅指定的 topic 和 channel ,在一切准备就绪之后发送 RDY 状态表示可以接受消息,并指明一次可以处理的最大消息数量 max-in-flight 为 2 ,随后 nsqd 向 consumer 投递消息,consumer 消费者在接受到消息后进行业务处理,并且需要向 nsqd 响应 FIN(消息处理成功)或者 REQ( re-queue 重新排队),投递完成但未响应的这段时间内的消息状态为 in-flight 。
配置项 -max-rdy-count :每个 nsqd 最多可以接受的 RDY 即消费者的数量,超出范围则连接将被强制关闭,默认 2500 。
1
REQ
对于 REQ 响应,nsq 会将其重新加入到队列中等待下一次再投递( re-queue ),客户端可以指定 requeue 的 delay 延时,即重新排队并延时一段时间之后再重新投递消息,延时的时间不得超过配置项 -max-req-timeout 。
2
Timeout
每一条消息都必须在一定时间内向 nsq 做出响应,否则 nsq 会认为这条消息超时,然后 requeue 处理。
配置项 -msg-timeout :单条消息的超时时间,默认一分钟,即消息投递后一分钟内未收到响应,则 nsq 会将这条消息 requeue 处理。
配置值 -max-msg-timeout :nsqd 全局设置的最大超时时间,默认 15 分钟。
超时的判定时长将取决于以上两个配置的最小值。
3
Touch
有时候 consumer 需要更长的时间来对消息进行处理,而不想被 nsq 判定超时然后 requeue ,这时候就可以主动向 nsq 响应 Touch ,表示消息是正常处理的,但是需要更长时间,nsq 接受到 Touch 响应后就会刷新这条消息的超时时间。需要注意的是,我们并不能一直 Touch 到永远,其仍受制于配置项 -max-msg-timeout ,超出最大时长了 Touch 也没用,nsq 仍然会判定为超时并 requeue 。
4
Backoff
有时候 consumer 处理消息面临很大的压力,随时有崩溃的风险,这种情况下可以主动向 nsq 发送 RDY 0 实现 backoff ,换句话说就是消费端暂停接受等多消息,以减轻自身压力避免崩溃,等到有更多处理能力时再取消暂停状态慢慢接收更多消息。当然进入 backoff 然后慢慢恢复是一个需要动态调节的过程。

事实上加快消息的处理才是我们需要关注的重中之重。
03
—
其它
1
nsqlookupd
nsqlookupd 提供服务发现的功能,用来寻址特定主题的 nsqd。如果客户端直接 nsqd ,那么就会出现某些 topic 的 nsqd 在某个地址,另一些 topic 的 nsqd 在另外的地址,试想当我们的 nsqd 集群数量变得越来庞大,topic 的种类也越来越多时,这种直连的方法是有多么的混乱,而 nsqlookupd 就是为了解决这个问题。
所有的 nsqd 都注册到 nsqlookupd 上,然后客户端只需要连接 nsqlookupd 就可以轻松寻址到所有主题。但是,要注意的是 nsqlookupd 只负责寻址,不对消息做任何处理,我们可以认为客户端向 nsqlookupd 寻址完成后,仍然是与 nsqd 直连再进行消息处理。
为了避免 nsqlookupd 的单点故障,部署多个即可。通常一个数据中心部署三个 nsqlookupd 就可以应对成百上千的 nsqd 集群。
2
-mem-queue-size
配置项 -mem-queue-size:队列在内存中保留的消息数量,默认 10000 。一旦消息数量超过了这个阈值,那么超出的消息将被写入到磁盘中,当然你也可以设置为 0 ,这样所有的消息都将被写入到磁盘中,但是需要注意的是即使你这样做了也无法保证消息百分百不丢失,因为 in-flight 状态和 defer 延时状态下的消息仍然是在内存中,所以极端情况下仍旧会丢失。另外对于 clean shutdown 干净退出的情况 nsq 是保证了消息不丢失的,即使在内存中。
简而言之,我们应该放心大胆的使用更可能多的内存。
3
SPOF
NSQ 是一个分布式的设计,可以有效的避免 SPOF 单点故障。

如图所示,我们可以轻松的部署足够多的 nsqd 到多台机器上,并让消费者与之连接(这个图简化处理了,我们仍应该使用 nsqlookupd )。每一个 nsqd 之间是相互独立的,没有任何关联。这就是说如果三个 nsqd 具有相同的 topic 和 channel ,我们向它们发送同一条消息,本质上就是分别发送了三条消息,结果就是连接这三个 nsqd 的 consumer 将会收到三条消息。这样做显然有效的提高了可靠性,但是在消费端一定要做好重复消息的处理问题。
4
其它
- 消息是无序的
- 消息可能会被传递多次
- 没有复杂的路由
- 没有自动化的 replication 副本
04
—
结语
消息队列并不是大包大揽干掉所有事情,在实际应用中,我们完全可以与 mysql 和 redis 等等一起使用。 NSQ 不得不说是太精致了,水平扩展相当方便,消息传递也非常高效,强烈推荐。

