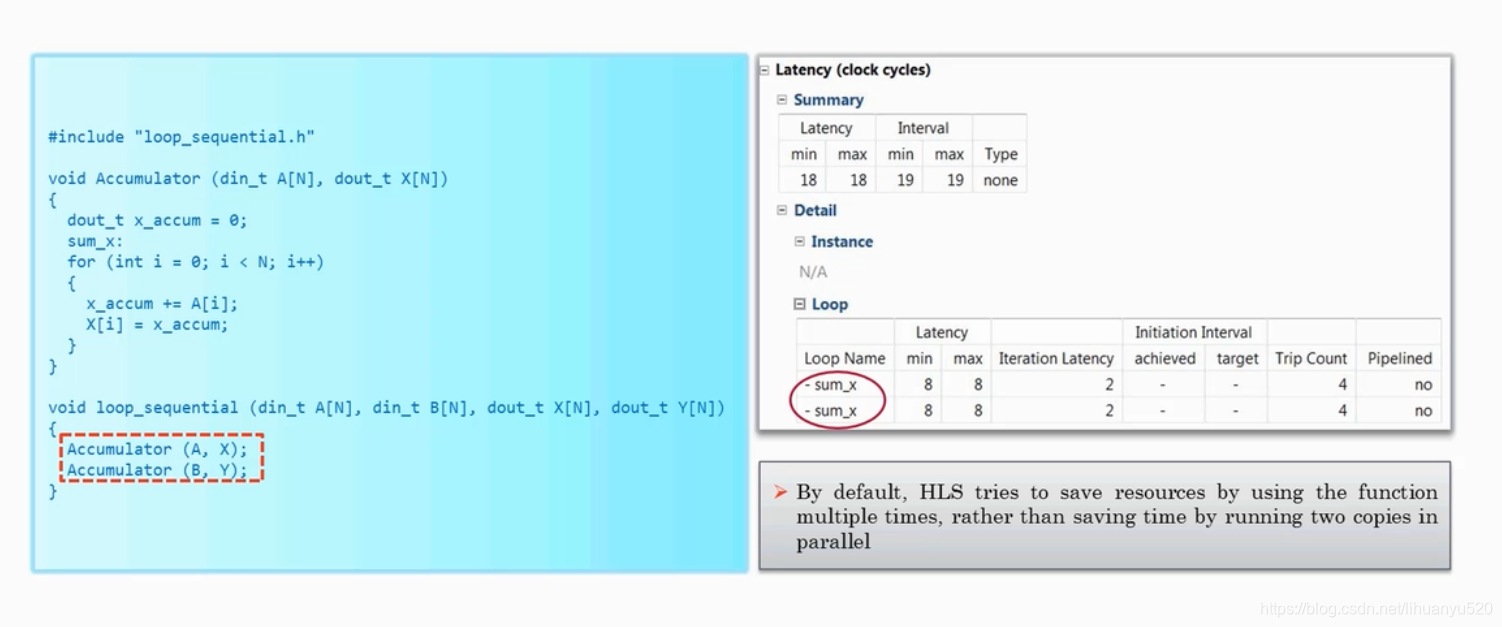
2. Dataflow for 'For-Loop’
在没有使用Dataflow时,三者执行顺序为A—>B—>C,没有交叠。使用Dataflow后,我们在三个循环之间加入channel(Ping-pong RAM,FIFO或Register),通道可确保不需要任务等待上一个任务完成所有操作才可以开始,此时循环之间是一个并行的关系,三者之间是有交叠的,这可以减少延迟提高数据的吞吐量。
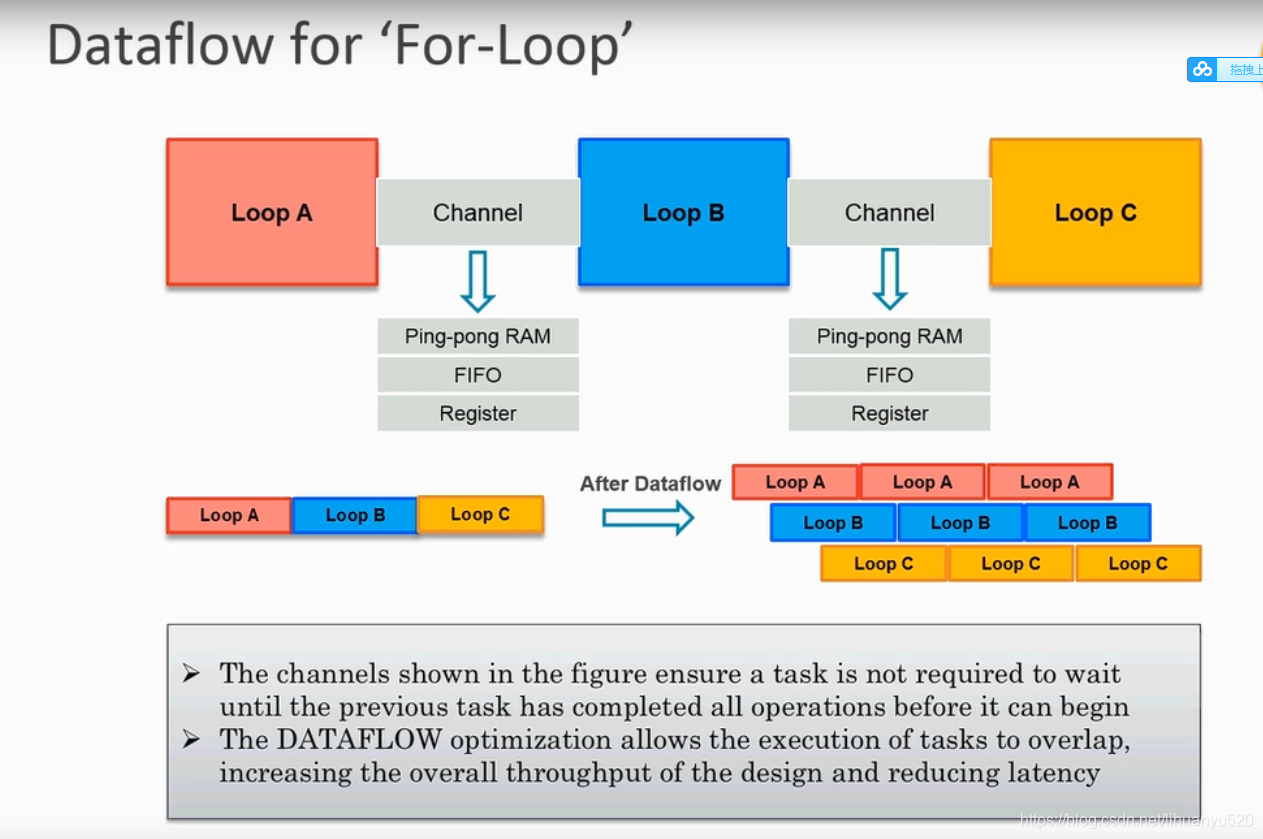
性能展示
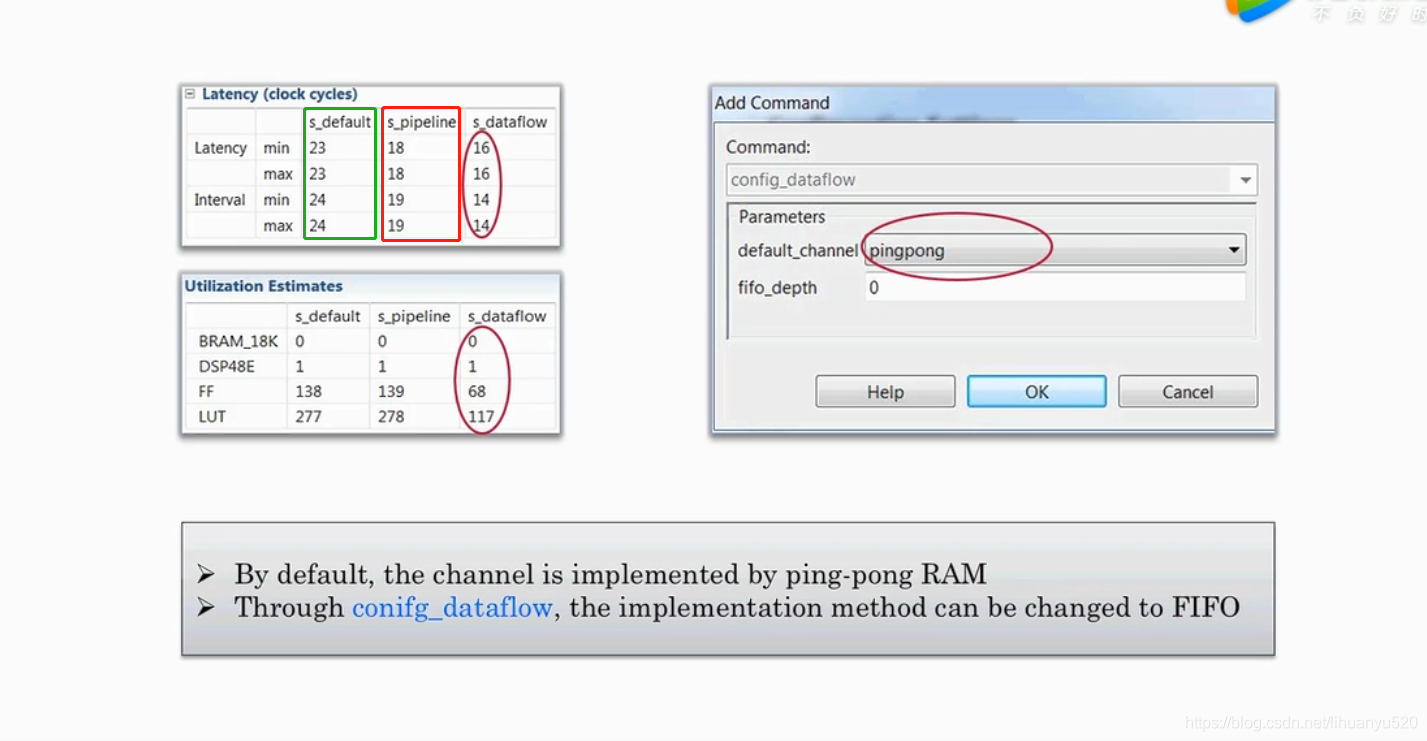
注:默认情况下,通道是通过ping-pong RAM实现的。通过conifg_dataflow,可以将实现方法更改为FIFO。
3. Dataflow优化限制
以下代码样式使Vivado HLS无法执行DATAFLOW优化
Single-producer-consumer violations
Bypassing tasks
Feedback between tasks
Conditional execution of tasks
Loop scopes with variable bounds
Loops with multiple exit conditions

我们如何进行优化使他可以使用
Bypassing Tasks Model
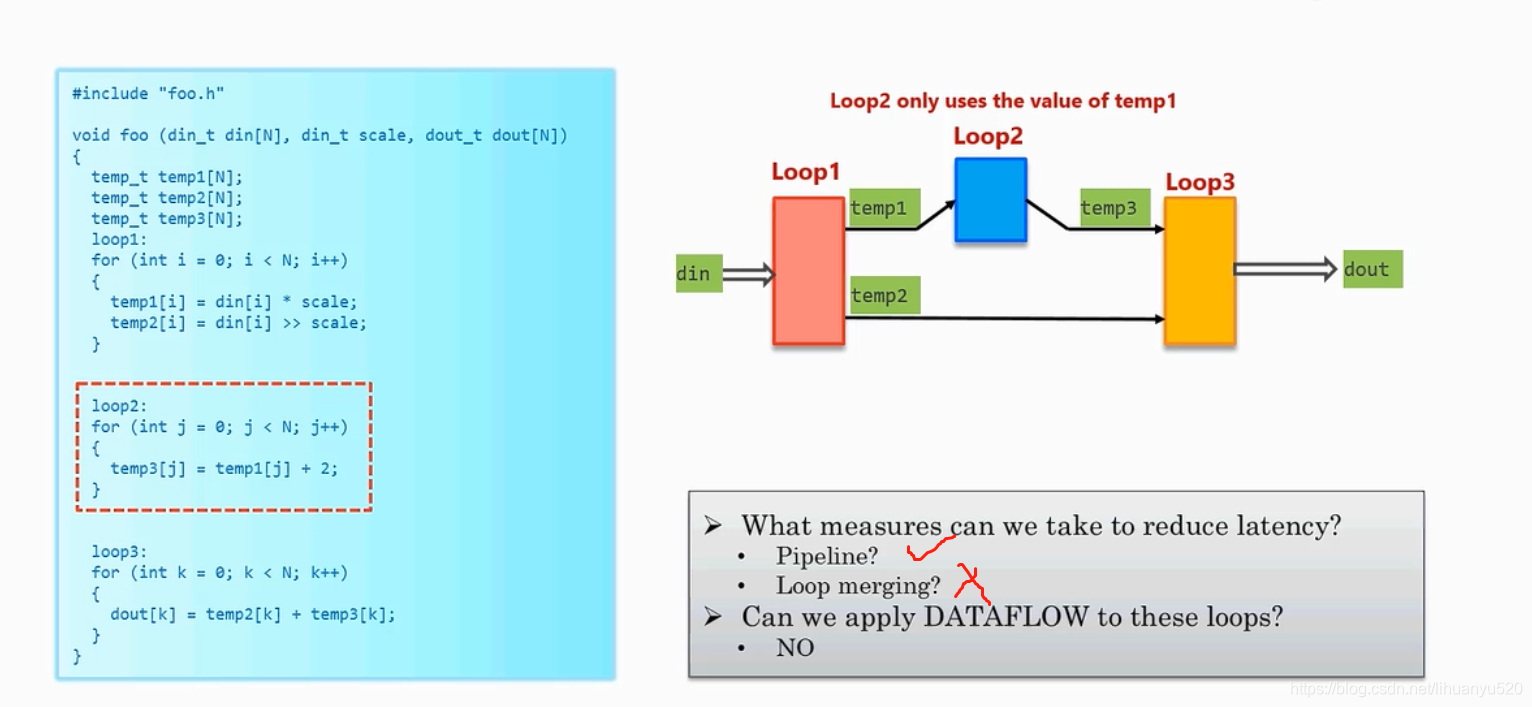
我们如何进行优化使他可以使用
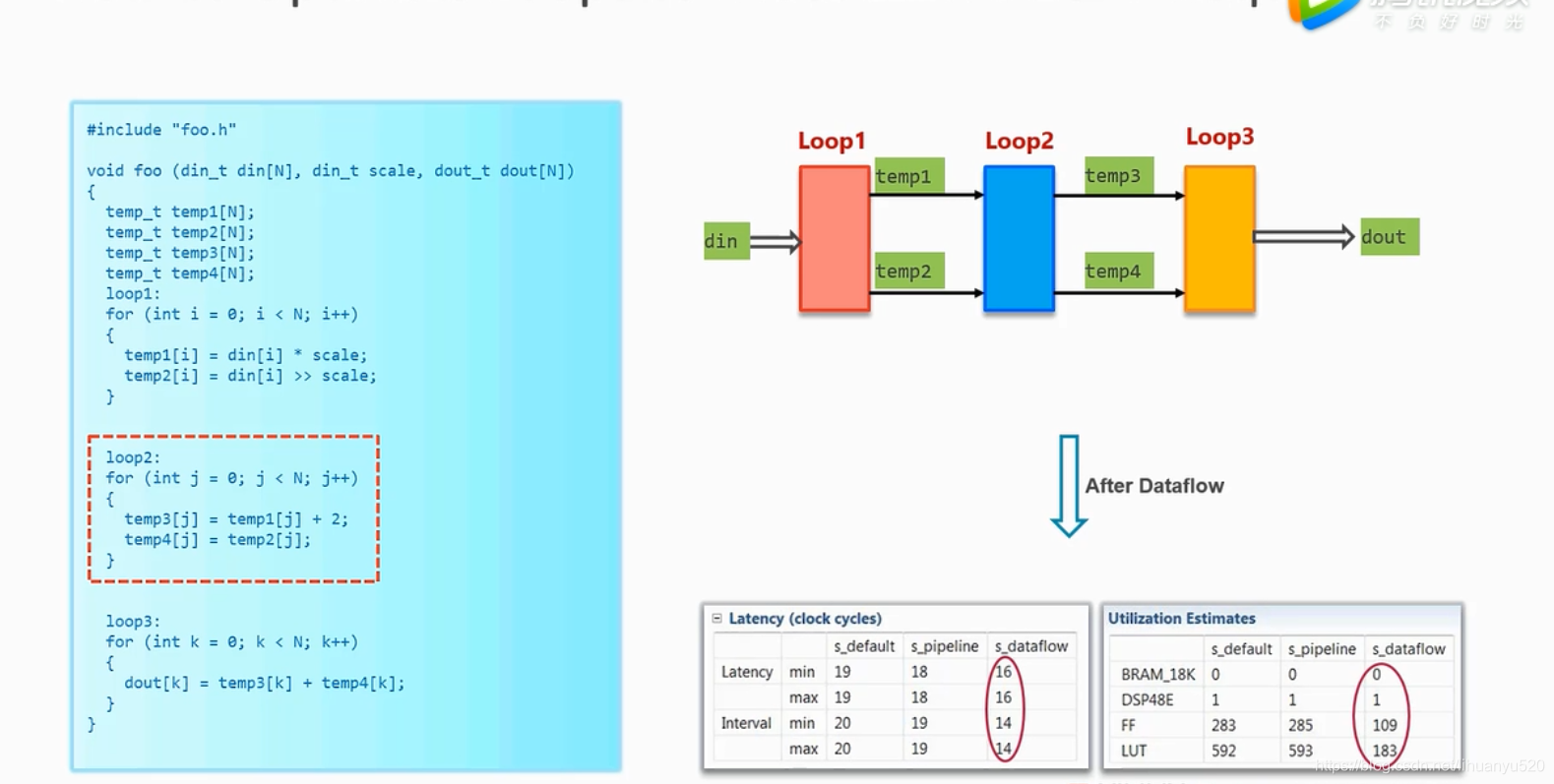
4. Configuring Dataflow Memory Channels
Vivado HLS根据数据producer和consumer 的访问方式,将任务之间的通道实现为ping-pong或FIFO buffers。
- 对于标量,指针和 reference parameters以及函数返回,Vivado HLS将通道实现为FIFO。
- 如果参数(producer和consumer )是一个数组,则Vivado HLS将该通道实现为一个ping-pong buffers或FIFO,如下所示
- 如果Vivado HLS确定按顺序访问数据,则Vivado HLS将存储通道实现为深度为1的FIFO通道.
- 如果Vivado HLS无法确定数据是按顺序访问的,或者无法确定数据是以任意方式访问的,则Vivado HLS将内存通道实现为ping-pong buffers。
5. 明确指定默认通道
使用config_dataflow配置
- 此配置为设计中的所有通道设置默认通道。
- 要减少通道中使用的内存大小,可以使用FIFO。
- 要显式设置FIFO中元素的深度或数量,请使用
fifo_depth选项。
6. 总结

第四讲 嵌套for循环优化
1. 三种分类
2. A Simple Example of Perfect Loop
矩阵对应元素相乘,我们对内部for循环做Pipeline和对外部for循环做Pipeline的情况对比,如下

- Pipeline最里面for循环可为大多数应用使用更少的硬件资源(与外部for循环相比),并具有通常可接受的吞吐量。
- 对层次结构的高层进行Pipeline,会展开所有子循环,并可以创建更多要调度的操作(这可能会影响运行时间和内存容量),但通常在吞吐量和延迟方面提供最高性能的设计。
第五讲 for循环优化其他方法
本节主要讲解为:
- 有关循环并行性的问题
- for循环做流水如何使用rewind
- for循环的边界是变量时,如何处理

1. 并行性
默认情况下,Vivado HLS对for循环做顺序执行的。虽然合并这些循环可以减少等待时间,但有时循环边界是变量和常数,因此无法合并循环。
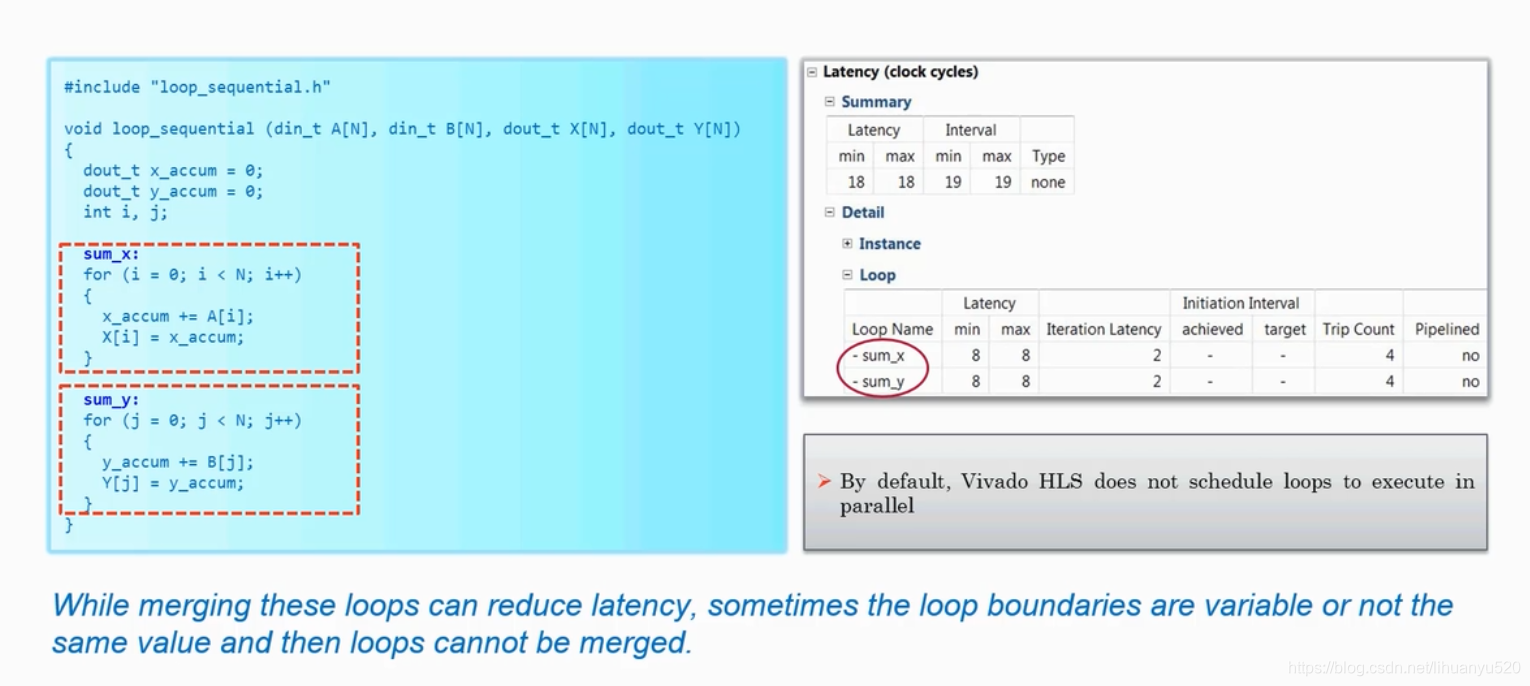
因为这两个for循环是独立存在的,我们可以定义一个函数并且调用两次,但是在默认情况下,HLS尝试通过多次使用该功能来节省资源,而不是通过并行运行两个副本来节省时间。因此结果与上文情况相同。