缓存穿透
- 缓存穿透指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库
- 如果有恶意用户使用无数的线程并发访问不存在数据,这些请求都会到达数据库,很有可能会将数据库击垮
解决方案
缓存空对象
- 思路:用户请求某一个 id 时,redis 和数据库中都不存在,我们直接将 id 对应空值缓存到 redis,这样下次用户重复请求这一 id 时,redis 中就可以命中(命中 null),就不会去请求数据库
- 优点:实现简单,维护方便
缺点:
- 额外的内存消耗(可以通过添加 TTL 解决)
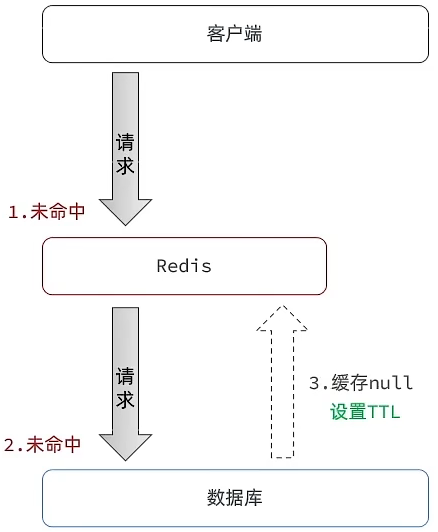
- 可能造成短期的不一致(控制 TTL 时间一定程度可以缓解):当缓存了 null 的时候,我们正好在数据库中设置了值,用户查询到的为 null,但是数据库中实际存在,这就会造成不一致(插入数据时自动覆盖之前的 null 数据可解决)
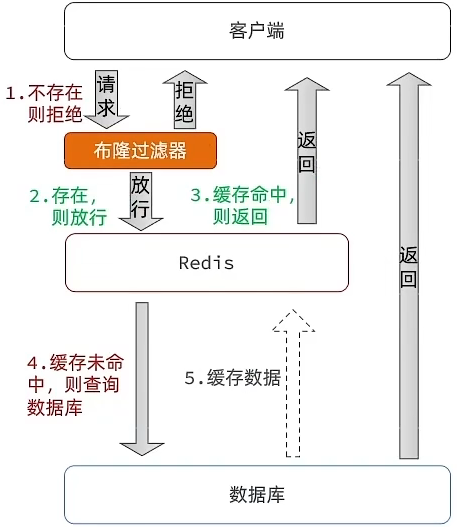
布隆过滤
- 在客户端和 redis 之间加一层 布隆过滤器,当用户访问时,首先有布隆过滤器判断数据是否存在,若不存在,直接拒绝;若存在,正常流程处理即可
布隆过滤器如何判断数据是否存在?
- 布隆过滤器可以简单理解为 byte 数组,存储二进制位,当要判断数据库中数据是否存在时,并不是直接将数据存储到布隆过滤器,而是通过哈希算法计算出哈希值,再将这些哈希值转换为二进制位保存到布隆过滤器中。判断数据是否存在时,判断对应位置是 0/1 即可(这种存在与否是一种概率上的统计,并不是 100% 准确,因此 不存在真的不存在,存在不一定存在,所以仍存在穿透风险)
- 优点:内存占用少,没有多余 key(二进制)
缺点:
- 实现复杂
- 存在误判可能(不一定准确)
缓存空对象 Java 实现
/**
* 缓存穿透
*
* @param id
* @return
*/
public Shop queryWithPassThrough(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
return JSONUtil.toBean(shopJson, Shop.class);
}
// 判断命中的是否是空值
if (shopJson != null) {
// 返回一个错误信息
return null;
}
// 4.不存在,根据id查询数据库
Shop shop = getById(id);
// 5.不存在,返回错误
if (shop == null) {
// 将空值写入 redis(缓存穿透)
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
// 6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 7.返回
return shop;
}缓存雪崩
- 缓存雪崩是指在同一时段大量的缓存 key 同时失效或者 Redis 服务宕机,导致大量请求到达数据库,带来巨大压力
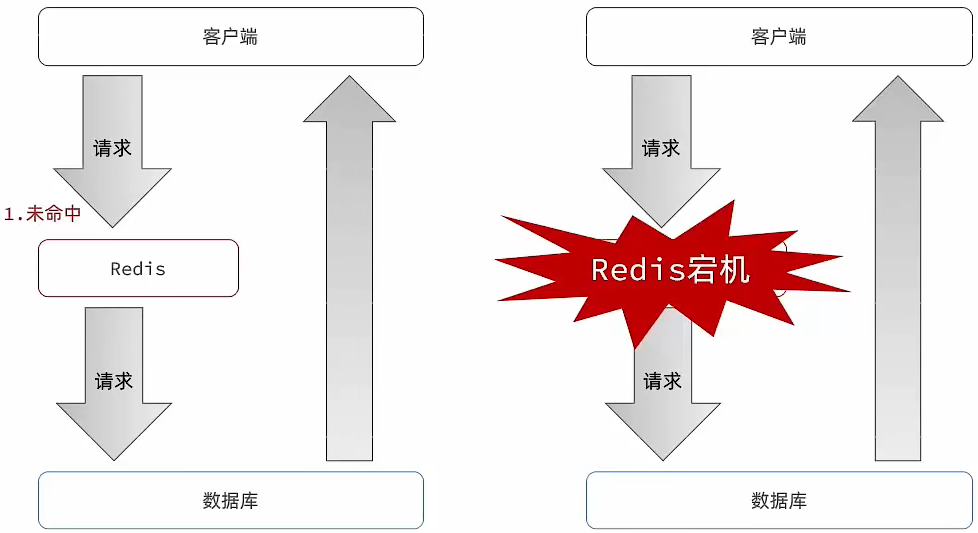
解决方案
- 给不同的 key 的 TTL 添加随机值(解决同时失效问题):比如在做缓存预热时,需要将数据库中的数据提前批量导入到缓存中,由于在同一时间导入,这些数据的 TTL 值相同,这就可能会导致在某一时刻这些数据同时过期,就会出现雪崩。为了解决这个问题,我们在导入时可以给 TTL 加一个随机数(比如 TTL 为 30±1~5 ),这样这些 key 的过期时间就会分散在一个时间段内,而不是同时失效,从而避免雪崩发生
- 利用 Redis 集群提高服务的可用性(解决 Redis 宕机):借助 Redis 哨兵机制,有一个机器宕机时,哨兵可以自动选一个机器替代宕机机器,同时主从可以实现数据同步,从而确保 Redis 的高可用
- 给缓存业务添加降级限流策略:比如快速失败,拒绝服务,避免请求压入数据库
- 给业务添加多级缓存:浏览器可以添加缓存(一般是静态资源),反代服务器 Nginx 可以添加缓存,Nginx 缓存未命中再去请求 Redis,Redis 缓存未命中到达 JVM,JVM 内部还可以建立本地缓存,最后达到数据库
缓存击穿
- 缓存击穿问题 也叫热点 key 问题,就是一个被 高并发访问 并且 缓存重建业务较复杂 的 key 突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击
缓存重建:redis 中的缓存在到期后就会失效,失效后需要重新从数据库中查询写入 redis。从数据库中查询并构建数据这一过程可能比较复杂,需要进行多表联查等,最终得到结果缓存起来。这一业务可能耗时比较长(几十甚至数百毫秒),在这一时间段内,redis 中一直没有缓存,到达的请求都会未命中去访问数据库
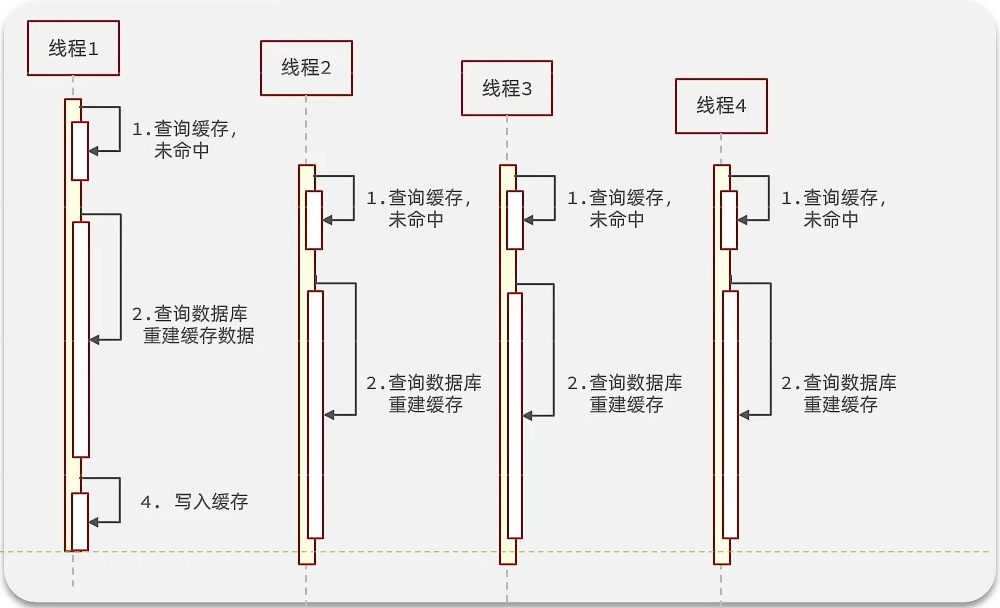
解决方案
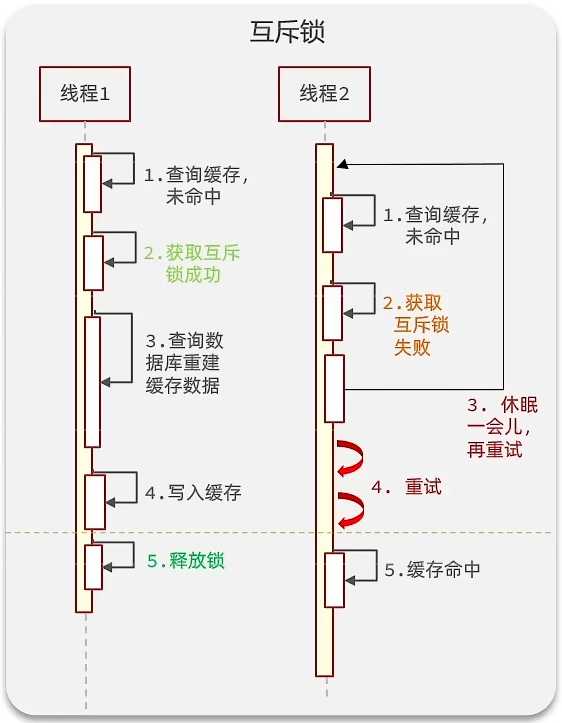
互斥锁
- 线程请求时发现未命中,在查询数据库前进行加锁操作,等到写入缓存后再释放锁。这样有其他线程未命中时,在查询数据库也会去获取互斥锁,获取失败后休眠一段时间后重新查询即可
- 显然,只有写入缓存后其他线程才能获取到数据,虽然能保证一致性,但性能比较差,还有可能造成死锁
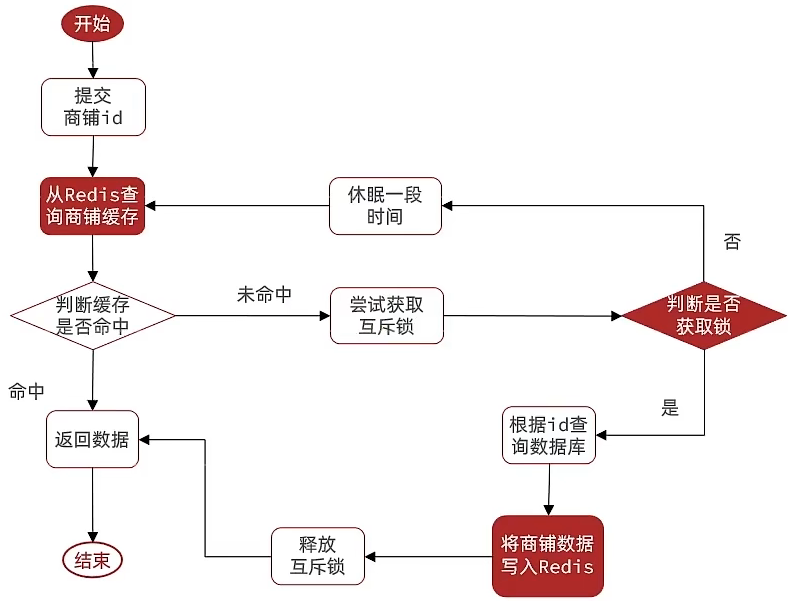
- Java 实现
/**
* 获取锁
*
* @param key
* @return
*/
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", LOCK_SHOP_TTL, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
/**
* 释放锁
*
* @param key
*/
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
/**
* 互斥锁
*
* @param id
* @return
*/
public Shop queryWithMutex(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
// 3.存在,直接返回
return JSONUtil.toBean(shopJson, Shop.class);
}
// 判断命中的是否是空值
if (shopJson != null) {
// 返回一个错误信息
return null;
}
// 4. 实现缓存重建
// 4.1 获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
// 4.2 判断是否获取成功
if (!isLock) {
// 4.3 失败,则休眠并重试
Thread.sleep(50);
// 递归
return queryWithMutex(id);
}
// 4.4 成功,根据 id 查询数据库
shop = getById(id);
// 模拟重建延时
Thread.sleep(200);
// 5.不存在,返回错误
if (shop == null) {
// 将空值写入 redis(缓存穿透)
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
// 6.存在,写入redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop), CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 7. 释放互斥锁
unlock(lockKey);
}
// 8.返回
return shop;
}- 我们使用 jmeter 测试一下,发送 1000 次请求,可以看到所有的请求都是通过,并且数据库仅进行了一次查询

逻辑过期
- 顾名思义,并不是真正的过期,可以看作是永不过期。当我们向 redis 中缓存数据时不设置 TTL,在存储数据时添加一个过期时间字段(并非TTL,当前时间基础上+过期时间,逻辑上维护的时间),这样一来任何线程来查询时都可以命中,只需要逻辑上判断是否过期即可
- 如下图,若线程1来查询缓存时发现逻辑时间已经过期,就需要重建缓存,然后获取互斥锁,为了避免发生获取锁等待时间过长的问题,线程1会开启一个新的线程(线程2)来代替自己进行缓存重建操作,缓存重建完成后再释放锁,而线程1直接返回过期的数据。当其他线程也未命中的时候,获取互斥锁失败会直接返回过期数据。这样性能上虽然有保证,但一致性无法保证
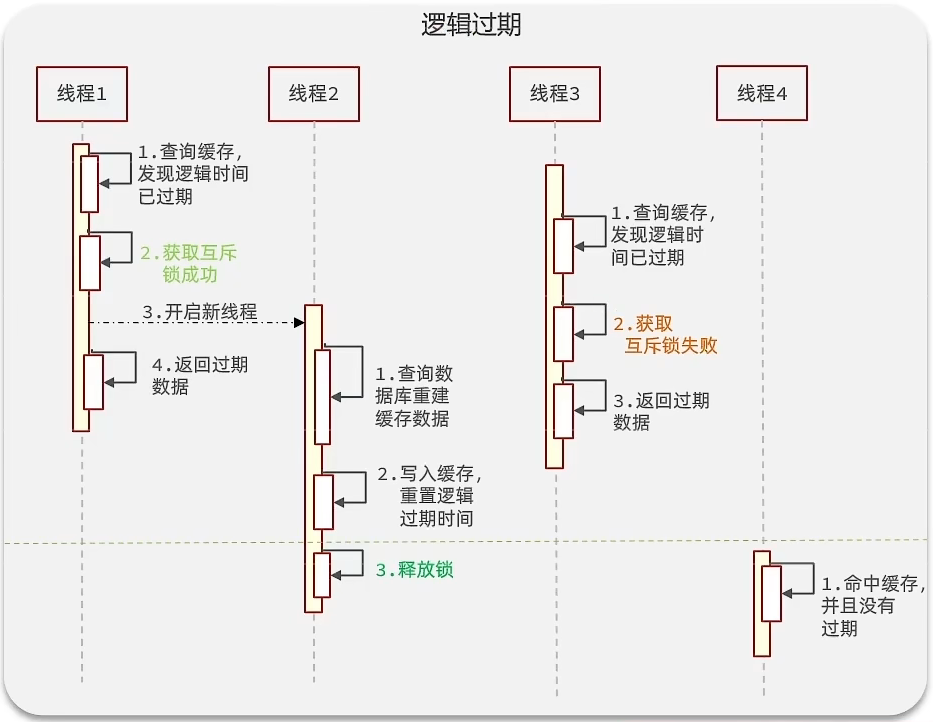
- Java 实现
/**
* 缓存预热
*
* @param id
* @param expireSeconds 逻辑过期时间
*/
public void saveShop2Redis(Long id, Long expireSeconds) throws InterruptedException {
// 1. 查询店铺数据
Shop shop = getById(id);
Thread.sleep(200);
// 2. 封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireSeconds));
// 3. 写入redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}
private static final ExecutorService CACHE_REBUILD_EXECUTOR = Executors.newFixedThreadPool(10);
/**
* 逻辑过期
*
* @param id
* @return
*/
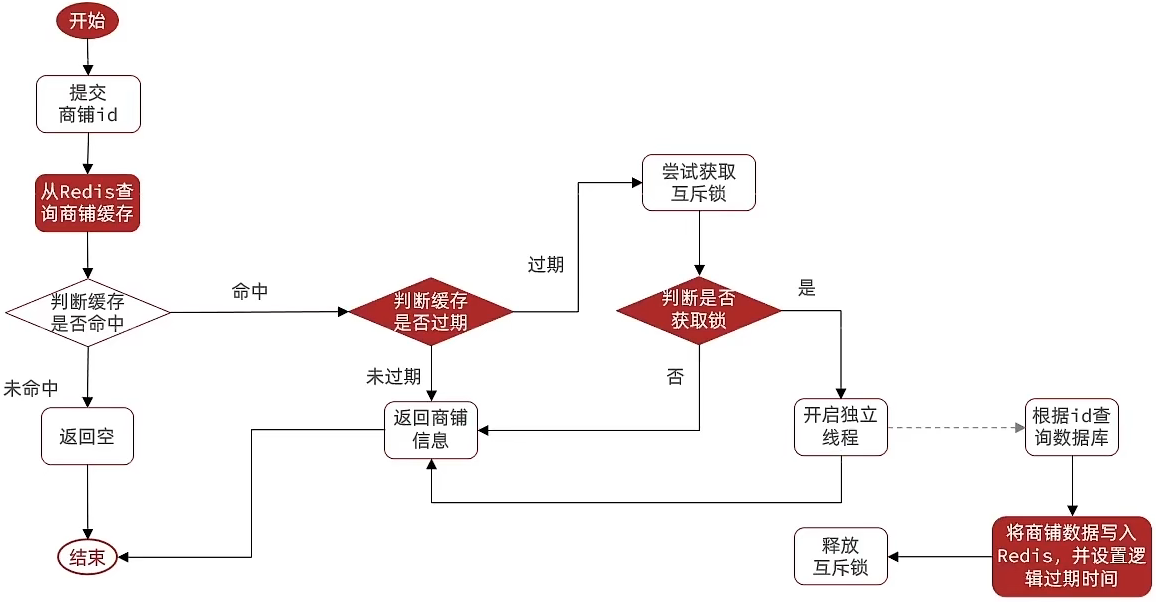
public Shop queryWithLogicalExpire(Long id) {
String key = CACHE_SHOP_KEY + id;
// 1.从redis查询商铺缓存
String shopJson = stringRedisTemplate.opsForValue().get(key);
// 2.判断是否存在
if (StrUtil.isBlank(shopJson)) {
// 3.未命中,直接返回
return null;
}
// 4. 命中,需要先把json反序列化为对象
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
// 5. 判断是否过期
if (expireTime.isAfter(LocalDateTime.now())) {
// 5.1 未过期,直接返回店铺信息
return shop;
}
// 5.2 已过期,需要缓存重建
// 6. 缓存重建
// 6.1 获取互斥锁
String lockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(lockKey);
// 6.2 判断是否获取锁成功
if (isLock) {
// 6.3 成功,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
// 重建缓存
this.saveShop2Redis(id, 20L);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
// 释放锁
unlock(lockKey);
}
});
}
// 6.4 返回过期的商铺信息
return shop;
}对比
| 解决方案 | 优点 | 缺点 |
|---|---|---|
| 互斥锁 | 没有额外的内存消耗 保证一致性 实现简单 |
线程需要等待,性能受影响 可能有死锁风险 |
| 逻辑过期 | 线程无需等待,性能较好 | 不保证一致性 有额外内存消耗 实现复杂 |