探索云世界_个人页
探索云世界

文章
431
问答
12
视频
6
个人介绍
暂无个人介绍
擅长的技术

暂无更多信息
2025年06月
-
06.18 15:23:22
 发表了文章
2025-06-18 15:23:22
发表了文章
2025-06-18 15:23:22
Qwen 家族再上新!
Qwen3 Embedding 是基于 Qwen3 基础模型训练的文本嵌入模型系列,可将离散符号转化为连续向量,捕捉语义关系。结合 Qwen3 Reranker 模型,通过“初筛+精排”流程提升搜索与推荐系统的相关性排序能力。该系列模型支持多语言、提供灵活架构(0.6B-8B 参数规模),并在 MTEB 多语言榜单中排名第一。用户可通过 Hugging Face、ModelScope 和 GitHub 快速体验模型服务。 -
06.17 18:14:17发表了文章
2025-06-17 18:14:17
WebDancer:从零训练一个 DeepResearch 类智能体
WebDancer 是一款具备 Agentic 能力的智能体,能在开放网页环境中自主提问、搜索、推理并验证答案。它通过多步推理、信息整合与交叉验证解决复杂问题,如医学文献分析或政策追踪。WebDancer 采用 CRAWLQA 和 E2HQA 数据合成策略生成高质量训练数据,并结合 SFT(监督微调)+ RL(强化学习)双阶段训练方法,提升模型在动态环境中的适应性和泛化能力。其核心技术包括 ReAct 行为框架和 DAPO 强化学习算法,确保路径优化与策略稳定性。未来,WebDancer 将接入 Browser 工具链,拓展至代码沙盒、长文本写作等应用场景,进一步向通用智能体演进。 -
06.17 17:44:39发表了文章
2025-06-17 17:44:39
视觉感知RAG×多模态推理×强化学习=VRAG-RL
通义实验室自然语言智能团队发布并开源了VRAG-RL,一种视觉感知驱动的多模态RAG推理框架。它能像人一样“边看边想”,通过粗到细的视觉仿生感知机制,逐步聚焦关键区域,精准提取信息。VRAG-RL结合强化学习与多专家采样策略,优化检索与推理路径,在多个视觉语言基准数据集上表现出色,显著提升准确性和效率。项目已发布技术方案并开源代码,支持快速部署和二次开发。 -
06.17 17:08:29发表了文章
2025-06-17 17:08:29
Apache RocketMQ + “太乙” = 开源贡献新体验
Apache RocketMQ 是 Apache 顶级项目,源于阿里巴巴,历经多年双十一考验。RocketMQ 联合“太乙”平台启动开源竞赛,提供贡献价值评价与奖金激励(最高 5000 元),助力开发者成为社区核心成员。竞赛包含详尽教程与自动搭建环境,促进技术生态繁荣,推动分布式消息处理技术发展。欢迎加入,共创开源未来! -
06.11 16:39:25发表了文章
2025-06-11 16:39:25
合成数据也能通吃真实世界?首个融合重建-预测-规划的生成式世界模型AETHER开源
上海人工智能实验室开源了生成式世界模型AETHER,该模型仅用合成数据训练,却能在真实环境中展现强大的零样本泛化能力。AETHER首创「重建—预测—规划」一体化框架,融合几何重建与生成建模,大幅提升模型在动态环境中的决策、规划和预测能力。其核心技术包括目标导向视觉规划、4D动态重建和动作条件视频预测,实验结果表明其性能达到或超越现有SOTA水平。论文、模型及项目主页均已开源。 -
06.11 16:05:38发表了文章
2025-06-11 16:05:38
10分钟,用RAG搭建专业钉钉/飞书客服机器人
只需10分钟,快速搭建专属客服机器人,大幅提升工作效率!通过魔搭社区注册账号、绑定阿里云账号获取免费算力资源,并选择GPU模式运行教程脚本。按照食用指引操作,完成机器人部署并进行对话测试,前5位在评论区提交作业的用户将获赠魔搭社区时尚咖啡杯一个。立即点击教程脚本链接开始体验吧! -
06.11 15:44:16发表了文章
2025-06-11 15:44:16
构建AI时代的大数据基础设施-MaxCompute多模态数据处理最佳实践
本文介绍了大数据与AI一体化架构的演进及其实现方法,重点探讨了Data+AI开发全生命周期的关键步骤。文章分析了大模型开发中的典型挑战,如数据管理混乱、开发效率低下和运维管理困难,并提出了解决方案。同时,详细描述了MaxCompute在构建AI时代数据基础设施中的作用,包括其强大的计算能力、调度能力和易用性特点。此外,还展示了MaxCompute在多模态数据处理中的应用实践以及具体客户案例,最后提供了体验MaxFrame解决方案的方式。 -
06.11 15:13:53发表了文章
2025-06-11 15:13:53
海量数据分页查询效率低?一文解析阿里云AnalyticDB深分页优化方案
本文介绍了AnalyticDB(简称ADB)针对深分页问题的优化方案。深分页是指从海量数据中获取靠后页码的数据,常导致性能下降。ADB通过快照缓存技术解决此问题:首次查询生成结果集快照并缓存,后续分页请求直接读取缓存数据。该方案在数据导出、全量结果分页展示及业务报表并发控制等场景下表现出色。测试结果显示,相比普通分页查询,开启深分页优化后查询RT提升102倍,CPU使用率显著降低,峰值内存减少至原方案的几分之一。实际应用中,某互联网金融客户典型慢查询从30秒优化至0.5秒,性能提升60+倍。 -
06.11 13:52:10发表了文章
2025-06-11 13:52:10
首创!阿里云RASD技术突破复杂跨域场景推理瓶颈,入选国际顶会ACL 2025
阿里云自主研发的RASD技术被ACL 2025长文收录,聚焦大语言模型推理加速问题。RASD融合检索与投机采样技术,通过草稿模型与检索相融合、构建最优检索树结构及强大的可扩展性三大创新机制,显著提升跨领域复杂任务的推理效率。该技术已应用于阿里云百炼专属版产品体系,赋能多行业高效推理服务。 -
06.11 13:39:51发表了文章
2025-06-11 13:39:51
大家之言|人工智能发展趋势与基础设施建设之路
中国AI技术发展已从跟跑转向基建领跑,“十四五”期间算力规模年均增速达27%。杭州城市大脑升级AI智能体集群,重庆部署超大城市治理系统,宁夏作为“东数西算”枢纽持续突破算力规模。专家梅建平指出,人工智能虽为核心驱动力,但需警惕过度期望,理性看待其局限性。国家提出“三步走”战略与“一体两翼”规划,推动算力基础设施建设,如“东数西算”和全国一体化算力网,以优化资源调度并促进数字经济高质量发展。 -
06.10 18:14:51发表了文章
2025-06-10 18:14:51
建模世界偏好:偏好建模中的Scaling Laws
本文探讨了人类偏好建模的可扩展性,揭示其遵循Scaling Law。通过大规模训练(1.5B-72B参数)Qwen 2.5模型,使用1500万对论坛偏好数据,发现测试损失随规模指数增长而线性下降。研究提出WorldPM(Modeling World Preference),作为统一的人类偏好表征方法,在客观与主观评估中展现优势。实验表明,WorldPM可显著提升样本效率和多维度性能,成为高效的人类偏好微调基座。同时,文章反思主观评估复杂性,建议放弃简单预设,让模型自主发现人类偏好的深层规律,推动AI对齐新方向。论文与代码已开源。 -
06.10 17:54:25发表了文章
2025-06-10 17:54:25
ParScale:一种全新的大模型Scaling Law
ParScale是一种新的模型扩展路线,通过并行计算增强模型能力,无需增加参数量。它引入多个并行流处理输入,动态聚合输出,显著提升性能,尤其在数学和编程任务中表现突出。相比传统方法,ParScale仅增加1/22的内存和1/6的延迟,适合边缘设备。研究还提出两阶段训练策略,降低训练成本。未来将探索更多模型架构和大数据场景下的应用潜力。 -
06.10 15:44:03发表了文章
2025-06-10 15:44:03
解锁 Qwen3 的Agent能力,CookBook来咯!
Qwen3系列模型具备强大Agent能力,但从模型到Agent仍存技术难题。为此,我们推出基于Qwen-Agent框架的3个CookBook示例,展示如何让Qwen3丝滑调用MCP Server全过程。不论是本地部署还是API调用模型,开发者均可通过Qwen-Agent完成复杂任务。CookBook包括自然语言驱动数据库操作、云端高德API地理服务及文档转思维导图等功能。Qwen-Agent封装了工具调用模板和解析器,原生支持MCP协议,大幅降低开发成本。欢迎体验并反馈。 -
06.09 17:59:19发表了文章
2025-06-09 17:59:19
Qwen3技术报告首次全公开!“混合推理模型”是这样炼成的
近日,通义千问Qwen3系列模型已开源,其技术报告也正式发布。Qwen3系列包含密集模型和混合专家(MoE)模型,参数规模从0.6B到235B不等。该模型引入了“思考模式”与“非思考模式”的动态切换机制,并采用思考预算机制优化推理性能。Qwen3支持119种语言及方言,较前代显著提升多语言能力,在多个基准测试中表现领先。此外,通过强到弱蒸馏技术,轻量级模型性能优异,且计算资源需求更低。所有Qwen3模型均采用Apache 2.0协议开源,便于社区开发与应用。
2025年05月
-
05.22 15:01:25发表了文章
2025-05-22 15:01:25
专家对谈|AI推动文化传媒行业向“新”发展
随着“人工智能+”行动的深入推进,文化传媒行业正经历深刻变革。云计算与AI深度融合,重构内容生产、分发全流程,为行业注入新动能。预计到2025年,我国AI核心产业规模将破万亿,文化传媒作为技术应用先锋,以两位数增速迈向智能化。在CCBN活动现场,中央广播电视总台与阿里云探讨了大模型如何驱动行业升级,展望未来新图景。汪莹指出,大模型将重构文化消费形态,助力生产力与传播力倍增,推动中国文化走向世界。同时,解决AI应用“最后一公里”问题需产业链各方协同发力,基于现有大模型能力进行二次开发是切实可行路径。
2025年02月
-
02.10 13:25:57发表了文章
2025-02-10 13:25:57
轻量消息队列(原 MNS)订阅 OSS 事件实践
使用轻量消息队列订阅OSS事件,实时处理文件变动,赢取ins风U型枕(限量500个)。访问活动页面,完成实操并上传截图即可参与领奖。活动时间:即日起至2025年2月28日16:00。奖品数量有限,先到先得,快来报名吧!
2025年01月
-
01.13 11:02:19发表了文章
2025-01-13 11:02:19
与 AI 智能体来一场“春节互动”
快来报名创建AI智能体,进行实时视频互动,讨论春节习俗如吃饺子、放鞭炮等。访问活动页面,按步骤部署并上传截图,即可获得限量蛇年抱枕,先到先得!活动时间:即日起至2025年2月14日16:00。 -
01.06 13:49:39发表了文章
2025-01-06 13:49:39
快速体验云消息队列 RocketMQ 版 Serverless 系列
欢迎报名参加RocketMQ Serverless活动!稳定可靠,无需运维,按量计费,秒级万QPS弹性,平均节省成本30%。参与即有机会赢取保温杯或木质音箱(限量500个)。活动时间:即日起至2025年1月26日16:00。访问活动页面,完成场景体验并上传消息轨迹截图即可参与抽奖,先到先得! -
01.02 20:19:17发表了文章
2025-01-02 20:19:17
云端问道 6 期实践教学-创意加速器:AI 绘画创作
本文介绍了在阿里云平台上一键部署Demo应用的步骤。部署完成后,通过公网地址体验Demo应用,包括文本生成图像等功能。 -
01.02 20:11:48发表了文章
2025-01-02 20:11:48
云端问道 7 期实践教学-使用操作系统智能助手 OS Copilot 轻松运维与编程
使用操作系统智能助手 OS Copilot 轻松运维与编程 -
01.02 20:04:54发表了文章
2025-01-02 20:04:54
云端问道9期实践教学-省心省钱的云上Serverless高可用架构
详细介绍了云上Serverless高可用架构的一键部署流程 -
01.02 19:52:35发表了文章
2025-01-02 19:52:35
云端问道18期实践教学-AI 浪潮下的数据安全管理实践
本文主要介绍AI浪潮下的数据安全管理实践,主要分为背景介绍、Access Point、Bucket三个部分 -
01.02 19:32:27发表了文章
2025-01-02 19:32:27
云端问道5期实践教学-基于Hologres轻量实时的高性能OLAP分析
本文基于Hologres轻量实时的高性能OLAP分析实践,通过云起实验室进行实操。实验步骤包括创建VPC和交换机、开通Hologres实例、配置DataWorks、创建网关、设置数据源、创建实时同步任务等。最终实现MySQL数据实时同步到Hologres,并进行高效查询分析。实验手册详细指导每一步操作,确保顺利完成。 -
01.02 19:26:43发表了文章
2025-01-02 19:26:43
云端问道11期实践教学-创建专属AI助手
本次分享意在帮助用户更加全面、深入地了解百炼的核心产品能力,并通过实际操作学会如何快速将大模型与自己的系统及应用相结合。主要包括以下三个方面: 1. 阿里云百炼产品定位和能力简介 2. 知识检索 RAG 智能体应用能力和优势 3. 最佳落地案例实践分享 -
01.02 19:13:03发表了文章
2025-01-02 19:13:03
云端问道第4期实践教学——多媒体数据存储与分发方案部署演示
该文档详细介绍了阿里云一键部署和手动部署多媒体数据存储与分发方案的步骤。一键部署通过资源编排服务(ROS)实现自动化,涵盖注册账号、开通服务、创建OSS Bucket、配置CDN加速及绑定IMM等功能,简化了复杂操作。手动部署则更细致地展示了每个配置环节,包括网络规划、资源创建、域名绑定、CDN配置、证书加密及最终的验证与清理,确保用户对整个流程有清晰理解。两种方式均以OSS为核心,支持数据上传、转码处理和加速分发,保障高效稳定的用户体验。
2024年12月
-
12.20 17:53:45发表了文章
2024-12-20 17:53:45
RDS通用云盘核心能力
本次实验主要体验RDS通用云盘的三项核心能力:IO加速、IO突发和数据归档。首先创建实验资源,包括RDS MySQL实例和ECS实例,耗时约5分钟。接着通过sysbench导入数据并配置安全设置。 在体验阶段,我们对比了开启和关闭IO加速及IO突发功能对RDS性能的影响,观察到QPS有显著差异。最后,通过将数据从云盘迁移到OSS中,展示了冷存层的数据归档功能,并进行RDS硬盘缩容,验证了其成本优势。整个实验过程详细记录了每一步操作,确保用户能直观感受到RDS通用云盘带来的性能提升和成本优化。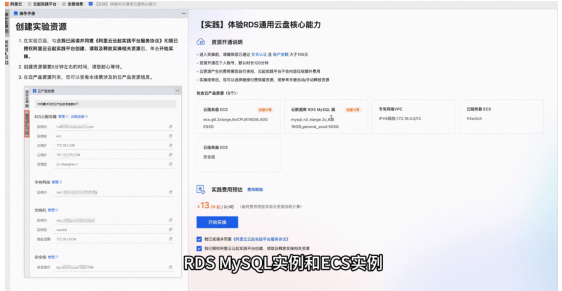
-
12.20 17:40:38发表了文章
2024-12-20 17:40:38
体验云数据库RDS通用云盘核心能力
本次课程由杨浩磊(木信)分享,主题为体验云数据库RDS通用云盘的核心能力。内容分为四部分:1) 初识RDS通用云盘,介绍其低成本、高性能的特点;2) 核心能力详解,涵盖IO加速、IO突发和数据归档功能;3) 方案及应用案例,展示实际性能提升与成本优化;4) 线上活动与权益,提供免费试用等优惠。RDS通用云盘通过多级存储架构,显著提升读写性能并降低存储成本,适用于多种业务场景。 -
12.20 17:31:29发表了文章
2024-12-20 17:31:29
【实践】快速学会使用云消息队列RabbitMQ版
本次分享的主题是快速学会使用云消息队列RabbitMQ版的实践。内容包括:如何创建和配置RabbitMQ实例,如Vhost、Exchange、Queue等;如何通过阿里云控制台管理静态用户名密码和AccessKey;以及如何使用RabbitMQ开源客户端进行消息生产和消费测试。最后介绍了实验资源的回收步骤,确保资源合理利用。通过详细的操作指南,帮助用户快速上手并掌握RabbitMQ的使用方法。 -
12.20 17:24:32发表了文章
2024-12-20 17:24:32
高弹性、低成本的云消息队列RabbitMQ 版
本次课程由阿里云消息队列产品专家杨文婷分享,主题为高弹性、低成本的云消息队列RabbitMQ。内容涵盖四个方面:1) 产品优势,包括兼容开源客户端、解决稳定性痛点和高弹性低成本;2) 架构实现原理,如分布式架构和弹性调度系统;3) Serverless系列带来的按量付费模式和资源池优势;4) Serverless适用场景,如开发测试环境、峰谷流量业务等。最后解答了关于顺序消费、与普通MQ对比、自动扩容及API支持等常见问题。 -
12.20 17:13:08发表了文章
2024-12-20 17:13:08
AI场景下的对象存储OSS数据管理实践
本文介绍了ECS和OSS的操作流程,分为两大部分。第一部分详细讲解了ECS的登录、密码重置、安全组设置及OSSUTIL工具的安装与配置,通过实验创建并管理存储桶,上传下载文件,确保资源及时释放。第二部分则聚焦于OSSFS工具的应用,演示如何将对象存储挂载为磁盘,进行大文件加载与模型训练,强调环境搭建(如Conda环境)及依赖安装步骤,确保实验结束后正确清理AccessKey和相关资源。整个过程注重操作细节与安全性,帮助用户高效利用云资源完成实验任务。 -
12.20 16:46:03发表了文章
2024-12-20 16:46:03
AI场景下的对象存储OSS数据管理实践
本文介绍了对象存储(OSS)在AI业务中的应用与实践。内容涵盖四个方面:1) 对象存储作为AI数据基石,因其低成本和高弹性成为云上数据存储首选;2) AI场景下的对象存储实践方案,包括数据获取、预处理、训练及推理阶段的具体使用方法;3) 国内主要区域的默认吞吐量提升至100Gbps,优化了大数据量下的带宽需求;4) 常用工具介绍,如OSSutil、ossfs、Python SDK等,帮助用户高效管理数据。重点讲解了OSS在AI训练和推理中的性能优化措施,以及不同工具的特点和应用场景。 -
12.20 16:37:02发表了文章
2024-12-20 16:37:02
尽享红利,Serverless构建企业AI应用方案与实践
本次课程由阿里云云原生架构师计缘分享,主题为“尽享红利,Serverless构建企业AI应用方案与实践”。课程分为四个部分:1) Serverless技术价值,介绍其发展趋势及优势;2) Serverless函数计算与AI的结合,探讨两者融合的应用场景;3) Serverless函数计算AIGC应用方案,展示具体的技术实现和客户案例;4) 业务初期如何降低使用门槛,提供新用户权益和免费资源。通过这些内容,帮助企业和开发者快速构建高效、低成本的AI应用。 -
12.20 16:20:09发表了文章
2024-12-20 16:20:09
云端问道9期实操教学
本节介绍SAE产品的部署方式,分为一键部署和手动部署。一键部署通过阿里云ROS平台快速拉起高可用方案所需资源,适合快速搭建环境;手动部署则需进入SAE控制台进行详细配置,适用于自定义应用部署。两者均支持多种部署方式,如源码仓库、镜像等,并提供灵活的资源配置选项。部署完成后需及时删除资源以避免费用产生。SAE支持HTTP和HTTPS协议,适合长时间运行的微服务和Web应用,而FC(函数计算)更适合短时、高并发的任务处理。 -
12.20 15:56:51发表了文章
2024-12-20 15:56:51
云端问道9期方案教学
本文介绍了Serverless的发展历程及SAE(Serverless Application Engine)产品。首先,回顾了云计算从物理机、虚拟机到容器化再到Serverless的演进过程,并解释了Serverless的核心特点:无需管理底层资源、自动弹性伸缩、聚焦业务价值。接着,详细介绍了SAE的功能与优势,包括简化部署流程、支持多种弹性策略和提供丰富的运维工具。SAE的收费模式主要基于CPU和内存使用量,辅以请求数和流量计费,用户可以选择按量付费或预付费资源包。最后,通过极氪汽车、南瓜电影、视野数科和SKG等实际案例,展示了SAE在不同行业的应用效果。 -
12.20 15:38:25发表了文章
2024-12-20 15:38:25
【实践】基于生命周期管理的存储成本优化
本实验介绍如何在阿里云创建和管理对象存储服务(OSS)。主要内容包括:1. 创建Bucket,选择存储类型及冗余方式;2. 上传文件,推荐使用API或SDK而非控制台直接操作;3. 设置生命周期规则,管理文件的存储层级转换与自动删除。实验重点在于合理配置存储策略以降低成本,并确保数据安全。通过控制台操作,用户可以轻松管理存储资源,但需注意防止不必要的公网访问以避免费用风险。 -
12.20 15:24:33发表了文章
2024-12-20 15:24:33
对象存储OSS产品介绍
本次分享由王太平(征越)主讲,围绕阿里云对象存储OSS的产品介绍、成本优化、功能实战及最佳实践展开。内容涵盖OSS的五种存储类型及其应用场景,详细解析了生命周期管理在数据存储成本优化中的重要作用,并提供了具体的配置建议和实际案例。适合希望深入了解OSS及优化存储成本的用户参考。 -
12.19 18:17:43发表了文章
2024-12-19 18:17:43
自建数据库迁移到云数据库实操
本课程详细介绍了自建数据库迁移到阿里云RDS的实操步骤。主要内容包括:创建实例资源、安全设置、配置自建的MySQL数据库、数据库的迁移、从自建数据库切换到RDS以及清理资源。通过这些步骤,学员可以掌握如何将自建数据库安全、高效地迁移到云端,并确保应用的正常运行。 -
12.19 17:57:16发表了文章
2024-12-19 17:57:16
自建数据库迁移到云数据库RDS
本次课程由阿里云数据库团队的凡珂分享,主题为自建数据库迁移至云数据库RDS MySQL版。课程分为四部分:1) 传统数据库部署方案及痛点;2) 选择云数据库RDS MySQL的原因;3) 数据库迁移方案和产品选型;4) 线上活动与权益。通过对比自建数据库的局限性,介绍了RDS MySQL在可靠性、安全性、性价比等方面的优势,并详细讲解了使用DTS(数据传输服务)进行平滑迁移的步骤。此外,还提供了多种优惠活动信息,帮助用户降低成本并享受云数据库带来的便利。 -
12.19 17:53:54发表了文章
2024-12-19 17:53:54
通义百炼融合AnalyticDB,10分钟创建网站AI助手
本文介绍了如何在百炼平台上创建和配置AI助手,使其能够准确回答公司产品的相关问题。主要步骤包括:开通管理控制台、创建应用并部署示例网站、配置知识库、上传产品介绍数据、创建AnalyticDB PostgreSQL实例、导入知识文件、启用知识检索增强功能,并最终测试AI助手的回答效果。通过这些步骤,AI助手可以从提供通用信息转变为精准回答特定产品问题。实操完成后,还可以释放实例以节省费用。 -
12.19 17:47:07发表了文章
2024-12-19 17:47:07
云端问道10期方案教学
本次分享由阿里云产品经理陈茏久主讲,主题为“通义百炼融合AnalyticDB,10分钟创建网站AI助手”。内容涵盖五大章节:大模型带来的行业变革、向量数据库驱动RAG服务化的探索、方案及优势、典型场景应用案例、方案涉及产品的选型配置简介和最新发布。介绍了大模型在电商、教育、汽车、游戏等行业的应用,以及AnalyticDB在向量数据库和RAG服务中的优势和具体案例。最后预告了ADB即将发布的功能,包括支持通义灵码企业标准版问答和成为析言推荐的NISQL数据分析引擎。 -
12.19 17:22:04发表了文章
2024-12-19 17:22:04
Web应用上云经典架构实践教学
Web应用上云经典架构实践教学
-
12.19 17:13:31发表了文章
2024-12-19 17:13:31
云端问道-Web应用上云经典架构方案教学
本文介绍了企业业务上云的经典架构设计,涵盖用户业务现状及挑战、阿里云业务托管架构设计、方案选型配置及业务初期低门槛使用等内容。通过详细分析现有架构的问题,提出了高可用、安全、可扩展的解决方案,并提供了按量付费的低成本选项,帮助企业在业务初期顺利上云。 -
12.19 17:05:17发表了文章
2024-12-19 17:05:17
Web应用上云经典架构实战
本课程详细介绍了Web应用上云的经典架构实战,涵盖前期准备、配置ALB、创建服务器组和监听、验证ECS公网能力、环境配置(JDK、Maven、Node、Git)、下载并运行若依框架、操作第二台ECS以及验证高可用性。通过具体步骤和命令,帮助学员快速掌握云上部署的全流程。 -
12.19 16:48:53发表了文章
2024-12-19 16:48:53
企业业务上云经典架构方案整体介绍
本次课程由阿里云产品经理晋侨分享,主题为企业业务上云经典架构。内容涵盖用户业务架构现状及挑战、阿里云业务托管经典架构设计、方案涉及的产品选型配置,以及业务初期如何低门槛使用。课程详细介绍了企业业务上云的全流程,帮助用户实现高可用、稳定、可扩展的云架构。 -
12.19 16:44:22发表了文章
2024-12-19 16:44:22
云端问8期-实践教学
云端问8期-实践教学 -
12.09 11:26:56发表了文章
2024-12-09 11:26:56
通过图片视觉理解,结构化提取属性信息
邀请您参加图片信息提取挑战!使用AI技术提升数据处理效率,通过部署应用并上传图片信息截图,即可赢取南瓜蒲团坐垫,每日限量50个,先到先得。活动截止至2024年12月27日16:00。立即访问活动页面参与吧!
2024年11月
-
11.26 15:02:35发表了文章
2024-11-26 15:02:35
AI编码,十倍提速,通义灵码引领研发新范式
欢迎参加通义灵码智能开发流程活动,通过在线部署和上传截图,即可获得新年好运日历,限量30个,先到先得!活动时间从即日起至2024年12月13日24:00。快来报名吧! -
11.26 14:43:53发表了文章
2024-11-26 14:43:53
Cloud Up挑战赛现已开启,点击查看活动玩法
【Cloud Up挑战赛】正式开启,围绕互联网应用开发、AI、大数据等七大领域,提供技术解决方案,帮助用户解决上云过程中的技术难题,通过实践降低成木、提高效率。每两周更新一期主题挑战,完成特定任务可获奖励,连续参与3期还有特别大奖。第三期挑战已启动,聚焦AI模型服务与推理,快来参与赢取丰富奖品吧!
-
发表了文章
2025-10-17
PolarDB-PG IMCI实战解析:深度融合DuckDB,复杂查询性能最高百倍级提升
-
发表了文章
2025-10-17
别让“数据安全”和“延时”拖慢上云脚步,PolarDB on ENS完美破解难题
-
发表了文章
2025-10-16
最佳实践3:用通义灵码开发一款 App
-
发表了文章
2025-10-16
最佳实践2:用通义灵码以自然语言交互实现 AI 高考志愿填报系统
-
发表了文章
2025-10-16
一人挑战一支研发团队,3步搞定全栈开发
-
发表了文章
2025-10-16
开发更可控,部署更便捷:AgentScope 迈入1.0时代
-
发表了文章
2025-10-16
先SFT后RL但是效果不佳?你可能没用好“离线专家数据”!
-
发表了文章
2025-10-16
真的假的?填个表格,就能调动1000个AI程序员给我打工?
-
发表了文章
2025-10-14
哪里不对改哪里!全能图像编辑模型Qwen-Image-Edit来啦
-
发表了文章
2025-10-14
ModelDistribution:高效的大模型管理、分发和预热方案
-
发表了文章
2025-10-14
ASM Ambient 模式下如何实现 L4 代理优雅升级
-
发表了文章
2025-10-14
ACK One 注册集群云端节点池升级:IDC 集群一键接入云端 GPU 算力,接入效率提升 80%
-
发表了文章
2025-09-26
通义灵码产品演示: 数据库设计与数据分析
-
发表了文章
2025-09-17
灵码产品演示:Maven 示例工程生成
-
发表了文章
2025-09-17
灵码产品演示:软件工程架构分析
-
发表了文章
2025-09-17
Dify 性能瓶颈?Higress AI 网关为它注入「高可用之魂」!
-
发表了文章
2025-09-17
使用 MSE 流量防护轻松面对运行态流量不确定风险的最佳实践
-
发表了文章
2025-09-17
通义灵码+支付 MCP:30 分钟实现创作打赏智能体
-
发表了文章
2025-09-17
RL 和 Memory 驱动的 Personal Agent,实测 Macaron AI
-
发表了文章
2025-09-05
原生支持QwenImage!FlowBench 正式开启公测!本地 + 云端双模生图,AI创作更自由
滑动查看更多
-
 提交了问题
2024-07-31
提交了问题
2024-07-31
您会在哪些场景中使用到云消息队列RabbitMQ 版?
-
提交了问题
2024-07-25
打造你的定制化文生图工具【AI动手】
-
提交了问题
2024-07-25
如何用AI来提高英语学习效率?【AI动手】
-
提交了问题
2024-07-19
传统架构在哪些方面存在缺陷?
-
提交了问题
2024-07-19
如何用5分钟搭建企业级AI问答知识库?试试Hologres,PAI和计算巢
-
提交了问题
2024-07-19
你试过一秒钟出现在世界各地的感觉吗?使用一键人像抠图换背景,让你拥有任意门
-
提交了问题
2024-07-09
结合自己的项目上云经历,分享部署过程及体验
-
提交了问题
2024-07-04
丹青-千变万换,体验图片局部内容替换,分享使用过程、输出结果及使用体验
-
提交了问题
2024-07-04
使用PAI-EAS一键部署ChatGLM,并应用LangChain集成外部数据
-
提交了问题
2024-06-12
函数计算一键部署ComfyUI绘画平台的优势有哪些?
-
提交了问题
2023-07-10
30秒上云,低门槛一键体验,谈一谈你对在控制台体验消息场景的感受?
-
提交了问题
2023-07-04
30秒上云,低门槛一键体验,谈一谈你对在控制台体验消息场景的感受?
滑动查看更多
-
 云端问道16期实践教学发布时间:2024-09-05 16:28:31 视频时长:14分16秒 播放量:253云端问道16期高弹性低成本的云消息队列 RabbitMQ 版实践教学
云端问道16期实践教学发布时间:2024-09-05 16:28:31 视频时长:14分16秒 播放量:253云端问道16期高弹性低成本的云消息队列 RabbitMQ 版实践教学 -
 云端问道16期方案教学发布时间:2024-09-05 15:43:23 视频时长:22分59秒 播放量:1483云端问道16期高弹性低成本的云消息队列 RabbitMQ 版方案教学
云端问道16期方案教学发布时间:2024-09-05 15:43:23 视频时长:22分59秒 播放量:1483云端问道16期高弹性低成本的云消息队列 RabbitMQ 版方案教学 -
 云端问道8期-方案教学发布时间:2024-08-16 13:51:56 视频时长:36分38秒 播放量:1310云端问道——解决方案陪跑班8期方案教学
云端问道8期-方案教学发布时间:2024-08-16 13:51:56 视频时长:36分38秒 播放量:1310云端问道——解决方案陪跑班8期方案教学 -
 云端问8期-实践教学发布时间:2024-08-16 13:48:49 视频时长:33分6秒 播放量:222云端问道——解决方案陪跑班8期实践教学
云端问8期-实践教学发布时间:2024-08-16 13:48:49 视频时长:33分6秒 播放量:222云端问道——解决方案陪跑班8期实践教学 -
 云端问道9期方案教学发布时间:2024-08-15 10:21:37 视频时长:26分33秒 播放量:1431云端问道——解决方案陪跑班9期方案教学
云端问道9期方案教学发布时间:2024-08-15 10:21:37 视频时长:26分33秒 播放量:1431云端问道——解决方案陪跑班9期方案教学 -
 云端问道9期实操教学发布时间:2024-08-15 09:46:21 视频时长:45分27秒 播放量:232云端问道——解决方案陪跑班9期实操教学
云端问道9期实操教学发布时间:2024-08-15 09:46:21 视频时长:45分27秒 播放量:232云端问道——解决方案陪跑班9期实操教学
滑动查看更多