AI浩

已加入开发者社区1809天
勋章

专家博主
专家博主

星级博主
星级博主

技术博主
技术博主

开发者认证勋章
开发者认证勋章

江湖新秀
江湖新秀



我关注的人
粉丝


技术能力
兴趣领域
- C#
- C++
- Python
- 人工智能
擅长领域
技术认证
暂时未有相关云产品技术能力~
暂无个人介绍
-
 Swin Transformer实战:使用 Swin Transformer实现图像分类2年前目标检测刷到58.7 AP! 实例分割刷到51.1 Mask AP! 语义分割在ADE20K上刷到53.5 mIoU! 今年,微软亚洲研究院的Swin Transformer又开启了吊打CNN的模式,在速度和精度上都有很大的提高。这篇文章带你实现Swin Transformer图像分类。8644来自: 人工智能
Swin Transformer实战:使用 Swin Transformer实现图像分类2年前目标检测刷到58.7 AP! 实例分割刷到51.1 Mask AP! 语义分割在ADE20K上刷到53.5 mIoU! 今年,微软亚洲研究院的Swin Transformer又开启了吊打CNN的模式,在速度和精度上都有很大的提高。这篇文章带你实现Swin Transformer图像分类。8644来自: 人工智能
暂无更多
暂无更多信息
2023年10月
-
10.25 20:50:56
 发表了文章
2023-10-25 20:50:56
发表了文章
2023-10-25 20:50:56
YoloV8最新改进手册——高阶篇
本专栏是讲解如何改进Yolov8的专栏。改进方法采用了最新的论文提到的方法。改进的方法包括:增加注意力机制、更换卷积、更换block、更换backbone、更换head、更换优化器等;每篇文章提供了一种到N种改进方法。 评测用的数据集是我自己标注的数据集,里面包含32种飞机。每种改进方法我都做了测评,并与官方的模型做对比。 代码和PDF版本的文章,我在验证无误后会上传到百度网盘中,方便大家下载使用。 这个专栏,求质不求量,争取尽心尽力打造精品专栏!!! 专栏链接: ''' https://blog.csdn.net/m0_47867638/category_12295903
2022年11月
-
11.22 12:53:37发表了文章
2022-11-22 12:53:37
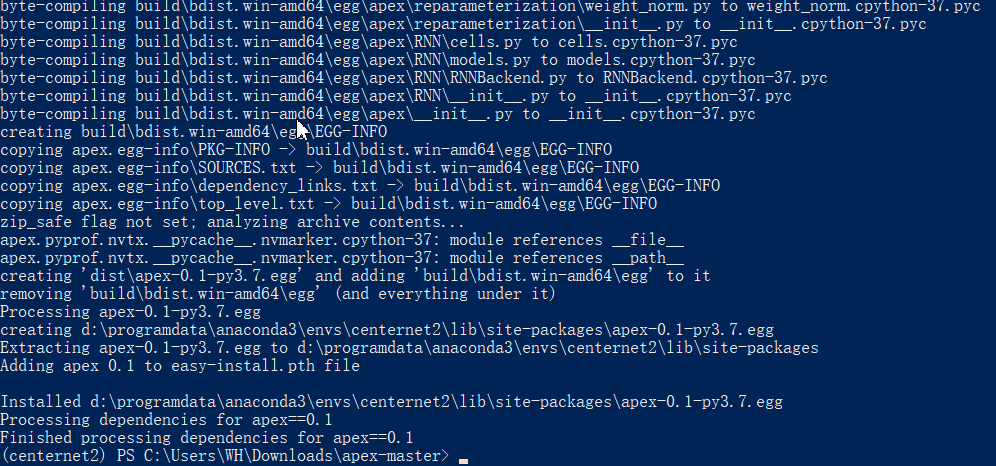
MobileNet实战:tensorflow2.X版本,MobileNetV2图像分类任务(小数据集)
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,今天我和大家一起实现tensorflow2.X版本图像分类任务,分类的模型使用MobileNetV2,MobileNetV2在MobileNetV1的基础上增加了线性瓶颈(Linear Bottleneck)和倒残差(Inverted Residual)是一种轻量级的网络,适合应用在真实的移动端应用场景。
-
11.22 12:52:53发表了文章
2022-11-22 12:52:53
MobileNet实战:tensorflow2.X版本,MobileNetV2图像分类任务(大数据集)
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,今天我和大家一起实现tensorflow2.X版本图像分类任务,分类的模型使用MobileNetV2。本文实现的算法有一下几个特点: 1、自定义了图片加载方式,更加灵活高效,不用将图片一次性加载到内存中,节省内存,适合大规模数据集。 2、加载模型的预训练权重,训练时间更短。 3、数据增强选用albumentations。
-
11.22 12:52:03发表了文章
2022-11-22 12:52:03
mobileNetV2解析以及多个版本实现
mobileNetV2是对mobileNetV1的改进,是一种轻量级的神经网络。mobileNetV2保留了V1版本的深度可分离卷积,增加了线性瓶颈(Linear Bottleneck)和倒残差(Inverted Residual)。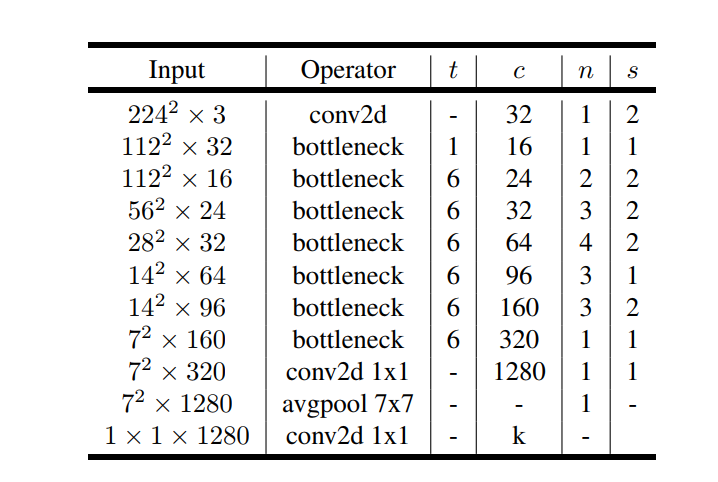
-
11.18 07:02:33发表了文章
2022-11-18 07:02:33
MobileNetV1实战:使用MobileNetV1实现植物幼苗分类
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,演示如何使用pytorch版本的MobileNetV1图像分类模型实现分类任务。 通过本文你和学到: 1、如何自定义MobileNetV1模型。 2、如何自定义数据集加载方式? 3、如何使用Cutout数据增强? 4、如何使用Mixup数据增强。 5、如何实现训练和验证。 6、预测的两种写法。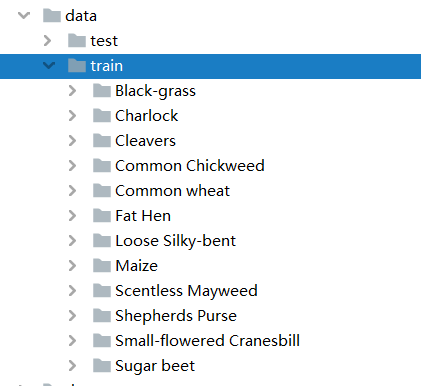
-
11.18 06:56:54发表了文章
2022-11-18 06:56:54
MobileNet实战:tensorflow2.X版本,MobileNetV1图像分类任务(大数据集)
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,今天我和大家一起实现tensorflow2.X版本图像分类任务,分类的模型使用MobileNetV1。本文实现的算法有一下几个特点: 1、自定义了图片加载方式,更加灵活高效,不用将图片一次性加载到内存中,节省内存,适合大规模数据集。 2、加载模型的预训练权重,训练时间更短。 3、数据增强选用albumentations。
-
11.18 06:55:40发表了文章
2022-11-18 06:55:40
MobileNet实战:tensorflow2.X版本,MobileNetV1图像分类任务(小数据集)
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,今天我和大家一起实现tensorflow2.X版本图像分类任务,分类的模型使用MobileNet,其核心是采用了深度可分离卷积,其不仅可以降低模型计算复杂度,而且可以大大降低模型大小,本文使用的案例训练出来的模型只有38M,适合应用在真实的移动端应用场景。
2022年04月
-
04.07 09:21:34发表了文章
2022-04-07 09:21:34
mobileNetV1网络解析,以及实现(pytorch)
mobileNetV1网络解析,以及实现(pytorch)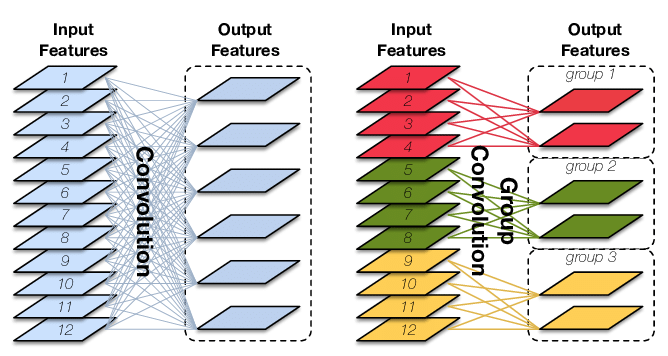
-
04.07 09:20:56发表了文章
2022-04-07 09:20:56
普通卷积、分组卷积和深度分离卷积概念以及参数量计算
普通卷积、分组卷积和深度分离卷积概念以及参数量计算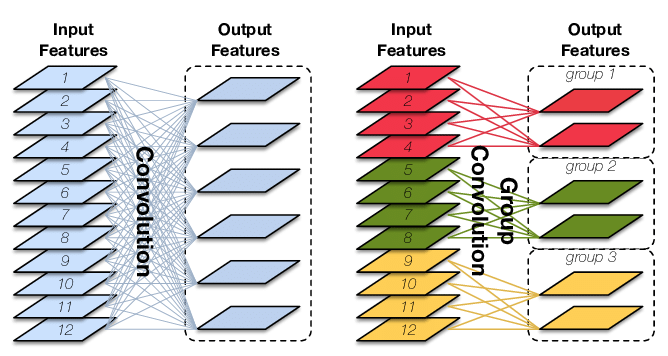
-
04.07 09:20:11发表了文章
2022-04-07 09:20:11
【第26篇】MobileNets:用于移动视觉应用的高效卷积神经网络
【第26篇】MobileNets:用于移动视觉应用的高效卷积神经网络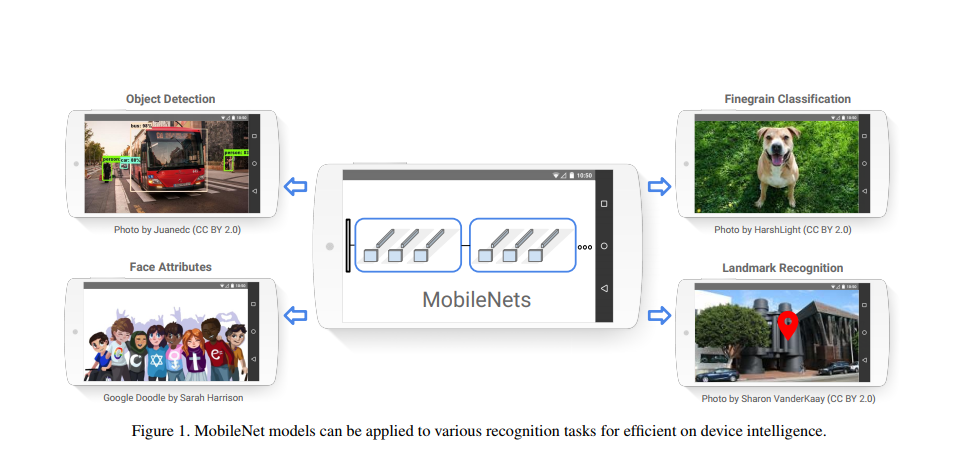
2022年01月
-
01.26 10:08:50发表了文章
2022-01-26 10:08:50
Markdown如何定义公式编号,以及引用编号
Markdown如何定义公式编号,以及引用编号 -
01.26 10:07:36发表了文章
2022-01-26 10:07:36
浅谈神经网络中的bias
1、什么是bias? 偏置单元(bias unit),在有些资料里也称为偏置项(bias term)或者截距项(intercept term),它其实就是函数的截距,与线性方程 y=wx+b 中的 b 的意义是一致的。在 y=wx+b中,b表示函数在y轴上的截距,控制着函数偏离原点的距离,其实在神经网络中的偏置单元也是类似的作用。 因此,神经网络的参数也可以表示为:(W, b),其中W表示参数矩阵,b表示偏置项或截距项。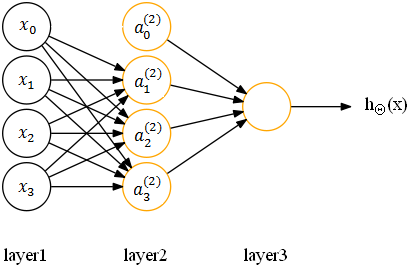
-
01.25 22:15:54发表了文章
2022-01-25 22:15:54
【第26篇】MobileNets:用于移动视觉应用的高效卷积神经网络
我们提出了一类称为 MobileNets 的高效模型,用于移动和嵌入式视觉应用。 MobileNets 基于流线型架构,使用深度可分离卷积来构建轻量级深度神经网络。 我们引入了两个简单的全局超参数,可以有效地在延迟和准确性之间进行权衡。 这些超参数允许模型构建者根据问题的约束为其应用程序选择合适大小的模型。 我们在资源和准确性权衡方面进行了广泛的实验,并与 ImageNet 分类上的其他流行模型相比表现出强大的性能。 然后,我们展示了 MobileNets 在广泛的应用和用例中的有效性,包括对象检测、细粒度分类、人脸属性和大规模地理定位。
-
01.23 10:16:42发表了文章
2022-01-23 10:16:42
InceptionV3实战:tensorflow2.X版本,InceptionV3图像分类任务(大数据集)
本例提取了猫狗大战数据集中的部分数据做数据集,演示tensorflow2.X版本如何使用Keras实现图像分类,分类的模型使用InceptionV3。本文实现的算法有一下几个特点: 1、自定义了图片加载方式,更加灵活高效,不用将图片一次性加载到内存中,节省内存,适合大规模数据集。 2、加载模型的预训练权重,训练时间更短。 3、数据增强选用albumentations。
-
01.23 10:15:46发表了文章
2022-01-23 10:15:46
ResNet实战:tensorflow2.X版本,ResNet50图像分类任务(大数据集)
本例提取了猫狗大战数据集中的部分数据做数据集,演示tensorflow2.X版本如何使用Keras实现图像分类,分类的模型使用ResNet50。本文实现的算法有一下几个特点: 1、自定义了图片加载方式,更加灵活高效,不用将图片一次性加载到内存中,节省内存,适合大规模数据集。 2、加载模型的预训练权重,训练时间更短。 3、数据增强选用albumentations。
-
01.23 10:14:32发表了文章
2022-01-23 10:14:32
ResNet实战:tensorflow2.X版本,ResNet50图像分类任务(小数据集)
本例提取了植物幼苗数据集中的部分数据做数据集,数据集共有12种类别,今天我和大家一起实现tensorflow2.X版本图像分类任务,分类的模型使用ResNet50。 通过这篇文章你可以学到: 1、如何加载图片数据,并处理数据。 2、如果将标签转为onehot编码 3、如何使用数据增强。 4、如何使用mixup。 5、如何切分数据集。 6、如何加载预训练模型。
-
01.21 12:34:06发表了文章
2022-01-21 12:34:06
1. (arg0: bool) -> mediapipe.python._framework_bindings.packet.Packet
1. (arg0: bool) -> mediapipe.python._framework_bindings.packet.Packet -
01.20 18:57:53发表了文章
2022-01-20 18:57:53
DenseNet实战:tensorflow2.X版本,DenseNet121图像分类任务(大数据集)
本例提取了猫狗大战数据集中的部分数据做数据集,演示tensorflow2.0以上的版本如何使用Keras实现图像分类,分类的模型使用DenseNet121。本文实现的算法有一下几个特点: 1、自定义了图片加载方式,更加灵活高效,节省内存 2、加载模型的预训练权重,训练时间更短。 3、数据增强选用albumentations。
-
01.20 17:29:50发表了文章
2022-01-20 17:29:50
DenseNet实战:tensorflow2.X版本,DenseNet121图像分类任务(小数据集)
本例提取了猫狗大战数据集中的部分数据做数据集,演示tensorflow2.0以上的版本如何使用Keras实现图像分类,分类的模型使用DenseNet121。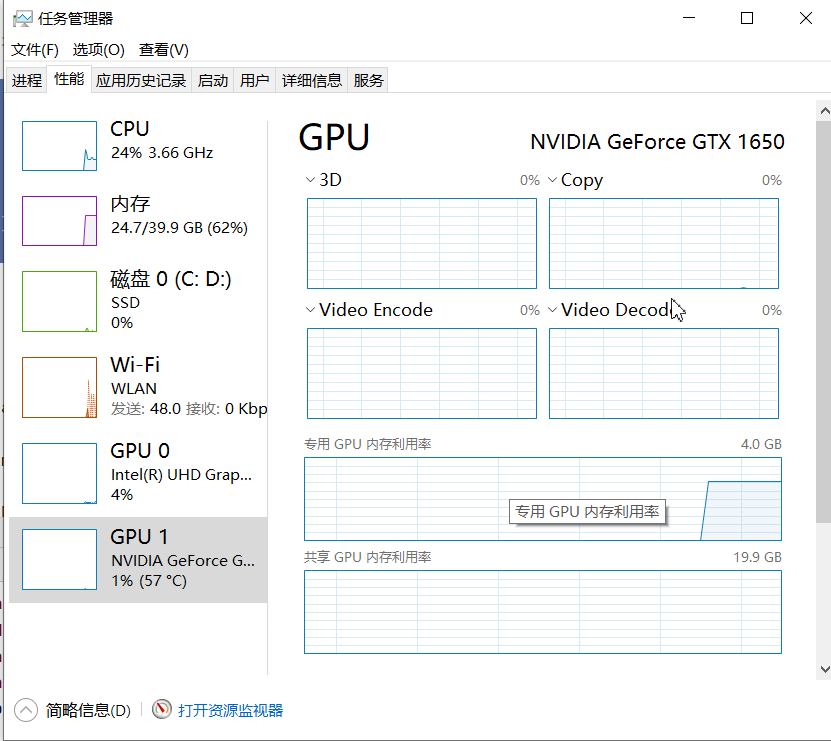
-
01.19 09:16:09发表了文章
2022-01-19 09:16:09
2021AIWIN 手写体 OCR 识别竞赛总结(任务一)
参加了“世界人工智能创新大赛”——手写体 OCR 识别竞赛(任务一),取得了Top1的成绩。下面通过这篇文章来介绍我们队伍的方案。队伍随机组的,有人找我我就加了进来,这是我第一次做OCR相关的项目,所以随意起了个名字。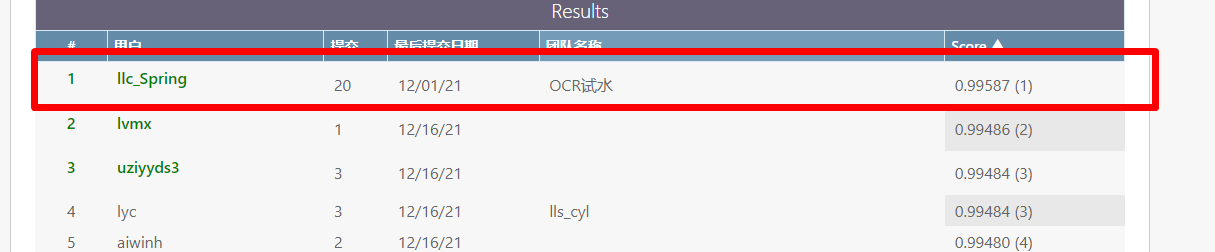
-
01.18 12:35:54发表了文章
2022-01-18 12:35:54
目标跟踪入门:使用OpenCV实现质心跟踪
**目标跟踪的过程**: 1、获取对象检测的初始集 2、为每个初始检测创建唯一的ID 3、然后在视频帧中跟踪每个对象的移动,保持唯一ID的分配 本文使用OpenCV实现质心跟踪,这是一种易于理解但高效的跟踪算法。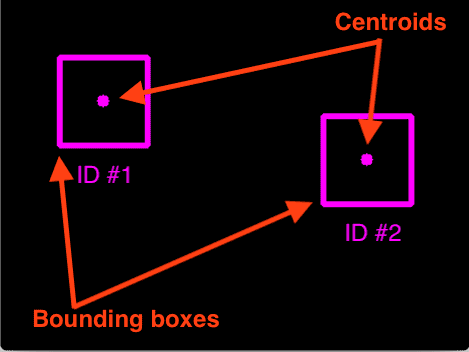
-
01.17 09:17:15发表了文章
2022-01-17 09:17:15
ConvNeXt实战:使用ConvNeXt实现植物幼苗分类(自创,非官方)
ConvNeXts 完全由标准 ConvNet 模块构建,在准确性和可扩展性方面与 Transformer 竞争,实现 87.8% ImageNet top-1 准确率,在 COCO 检测和 ADE20K 分割方面优于 Swin Transformers,同时保持标准 ConvNet 的简单性和效率。
-
01.15 05:40:31发表了文章
2022-01-15 05:40:31
Python求两个list的交集、并集、补集、对称差集的两种方法
Python求两个list的交集、并集、补集、对称差集的两种方法 -
01.15 05:39:55发表了文章
2022-01-15 05:39:55
【第25篇】力压Tramsformer,ConvNeXt成了CNN的希望
【第25篇】力压Tramsformer,ConvNeXt成了CNN的希望
-
01.15 05:38:47发表了文章
2022-01-15 05:38:47
物体检测实战:使用 OpenCV 进行 YOLO 对象检测
物体检测实战:使用 OpenCV 进行 YOLO 对象检测
-
01.14 10:26:34发表了文章
2022-01-14 10:26:34
YOLOR:多任务的统一网络
YOLOR:多任务的统一网络
-
01.14 10:22:08发表了文章
2022-01-14 10:22:08
记录:百度3天AI进阶实战营——车牌识别
记录:百度3天AI进阶实战营——车牌识别
-
01.11 06:29:39发表了文章
2022-01-11 06:29:39
pandas修改列的名字
pandas修改列的名字 -
01.11 06:28:58发表了文章
2022-01-11 06:28:58
一种实用的降学习率公式
一种实用的降学习率公式 -
01.11 06:28:12发表了文章
2022-01-11 06:28:12
目标检测进阶:使用深度学习和 OpenCV 进行目标检测
目标检测进阶:使用深度学习和 OpenCV 进行目标检测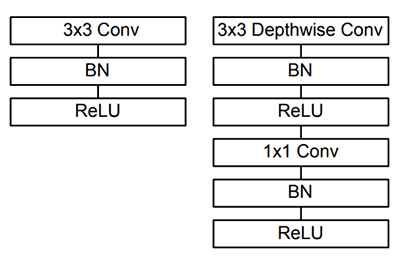
-
01.10 06:58:52发表了文章
2022-01-10 06:58:52
【第23篇】NAM:基于标准化的注意力模块
【第23篇】NAM:基于标准化的注意力模块
-
01.10 06:58:05发表了文章
2022-01-10 06:58:05
torch.distributed.init_process_group(‘gloo’, init_method=‘file://tmp/somefile’, rank=0, world_size=1
torch.distributed.init_process_group(‘gloo’, init_method=‘file://tmp/somefile’, rank=0, world_size=1
-
01.10 06:57:23发表了文章
2022-01-10 06:57:23
百度AI进阶实战营第九期:机械手抓取
百度AI进阶实战营第九期:机械手抓取
-
01.08 11:12:03发表了文章
2022-01-08 11:12:03
物体检测实战:使用OpenCV内置方法实现行人检测
您是否知道 OpenCV 具有执行行人检测的内置方法? OpenCV 附带一个预训练的 HOG + 线性 SVM 模型,可用于在图像和视频流中执行行人检测。
-
01.08 11:11:09发表了文章
2022-01-08 11:11:09
物体追踪实战:使用 OpenCV实现对指定颜色的物体追踪
物体追踪实战:使用 OpenCV实现对指定颜色的物体追踪
-
01.08 11:09:57发表了文章
2022-01-08 11:09:57
使用opencv中的VideoWriter函数,保存视频
使用opencv中的VideoWriter函数,保存视频 -
01.06 07:00:34发表了文章
2022-01-06 07:00:34
CoAtNet:将卷积和注意力结合到所有数据大小上
变形金刚在计算机视觉领域吸引了越来越多的兴趣,但它们仍然落后于最先进的卷积网络。在这项工作中,我们表明,虽然变形金刚往往具有更大的模型容量,但由于缺乏正确的归纳偏置,其泛化能力可能比卷积网络差。为了有效地结合两种体系结构的优势,我们提出了CoAtNets,这是一个基于两个关键观点构建的混合模型家族: (1)深度卷积和自我注意可以通过简单的相对注意自然地统一起来; (2) 以一种有原则的方式垂直堆叠卷积层和注意层在提高泛化、容量和效率方面出人意料地有效。
-
01.06 06:59:34发表了文章
2022-01-06 06:59:34
人脸识别实战:使用Opencv+SVM实现人脸识别
在本文中,您将学习如何使用 OpenCV 进行人脸识别。文章分三部分介绍: 第一,将首先执行人脸检测,使用深度学习从每个人脸中提取人脸量化为128位的向量。 第二, 在嵌入基础上使用支持向量机(SVM)训练人脸识别模型。 第三,最后使用 OpenCV 识别图像和视频流中的人脸。
-
01.06 06:58:33发表了文章
2022-01-06 06:58:33
CoAtNet实战:使用CoAtNet对植物幼苗进行分类(pytorch)
虽然Transformer在CV任务上有非常强的学习建模能力,但是由于缺少了像CNN那样的归纳偏置,所以相比于CNN,Transformer的泛化能力就比较差。因此,如果只有Transformer进行全局信息的建模,在没有预训练(JFT-300M)的情况下,Transformer在性能上很难超过CNN(VOLO在没有预训练的情况下,一定程度上也是因为VOLO的Outlook Attention对特征信息进行了局部感知,相当于引入了归纳偏置)。既然CNN有更强的泛化能力,Transformer具有更强的学习能力,那么,为什么不能将Transformer和CNN进行一个结合呢?
-
01.04 06:51:53发表了文章
2022-01-04 06:51:53
推荐一个找paper和code的网址
推荐一个找paper和code的网址
-
01.04 06:50:54发表了文章
2022-01-04 06:50:54
飞桨AI进阶实战:工业表计读数(记录)
飞桨AI进阶实战:工业表计读数(记录)
2021年12月
-
12.30 17:49:37发表了文章
2021-12-30 17:49:37
人脸检测实战终极:使用 OpenCV 和 Python 进行人脸对齐
这篇博文的目的是演示如何使用 OpenCV、Python 和面部标志对齐人脸。 给定一组面部标志(输入坐标),我们的目标是将图像扭曲并转换为输出坐标空间。
-
12.30 17:48:49发表了文章
2021-12-30 17:48:49
二分类的评价指标总结
二分类的评价指标总结
-
12.30 17:47:50发表了文章
2021-12-30 17:47:50
解决github访问速度慢的问题
解决github访问速度慢的问题
-
12.30 17:46:45发表了文章
2021-12-30 17:46:45
CoAtNet
CoAtNet -
12.30 17:45:59发表了文章
2021-12-30 17:45:59
人脸检测高级:疲劳检测
今天我们实现疲劳检测。 如果眼睛已经闭上了一段时间,我们会认为他们开始打瞌睡并发出警报来唤醒他们并引起他们的注意。我们测试一段视频来展示效果。同时代码中保留开启摄像头的的代码,取消注释即可使用。
-
12.30 17:44:39发表了文章
2021-12-30 17:44:39
人脸检测实战高级:使用 OpenCV、Python 和 dlib 完成眨眼检测
今天,我们使用面部标记和 OpenCV 检测视频流中的眨眼次数。 为了构建我们的眨眼检测器,我们将计算一个称为眼睛纵横比 (EAR) 的指标,该指标由 Soukupová 和 Čech 在他们 2016 年的论文《使用面部标记的实时眨眼检测》中介绍。
-
12.07 09:41:52发表了文章
2021-12-07 09:41:52
Swin Transformer实战:使用 Swin Transformer实现图像分类
目标检测刷到58.7 AP! 实例分割刷到51.1 Mask AP! 语义分割在ADE20K上刷到53.5 mIoU! 今年,微软亚洲研究院的Swin Transformer又开启了吊打CNN的模式,在速度和精度上都有很大的提高。这篇文章带你实现Swin Transformer图像分类。
-
12.07 09:40:54发表了文章
2021-12-07 09:40:54
人脸检测进阶:更快的5点面部标志检测器
今天在这里的目标是向您介绍新的 dlib 面部标志检测器,它比原始版本更快(提高 8-10%)、更高效、更小(10 倍)。 在这篇博文的第一部分,我们将讨论 dlib 的新的、更快、更小的 5 点面部标志检测器,并将其与随库分发的原始 68 点面部标志检测器进行比较。
2021年11月
-
11.30 16:05:22发表了文章
2021-11-30 16:05:22
人脸检测进阶:使用 dlib、OpenCV 和 Python 检测面部标记
人脸检测进阶:使用 dlib、OpenCV 和 Python 检测面部标记
-
发表了文章
2023-10-25
YoloV8最新改进手册——高阶篇
-
发表了文章
2022-11-22
MobileNet实战:tensorflow2.X版本,MobileNetV2图像分类任务(小数据集)
-
发表了文章
2022-11-22
MobileNet实战:tensorflow2.X版本,MobileNetV2图像分类任务(大数据集)
-
发表了文章
2022-11-22
mobileNetV2解析以及多个版本实现
-
发表了文章
2022-11-18
MobileNetV1实战:使用MobileNetV1实现植物幼苗分类
-
发表了文章
2022-11-18
MobileNet实战:tensorflow2.X版本,MobileNetV1图像分类任务(大数据集)
-
发表了文章
2022-11-18
MobileNet实战:tensorflow2.X版本,MobileNetV1图像分类任务(小数据集)
-
发表了文章
2022-04-07
mobileNetV1网络解析,以及实现(pytorch)
-
发表了文章
2022-04-07
普通卷积、分组卷积和深度分离卷积概念以及参数量计算
-
发表了文章
2022-04-07
【第26篇】MobileNets:用于移动视觉应用的高效卷积神经网络
-
发表了文章
2022-01-26
Markdown如何定义公式编号,以及引用编号
-
发表了文章
2022-01-26
浅谈神经网络中的bias
-
发表了文章
2022-01-25
【第26篇】MobileNets:用于移动视觉应用的高效卷积神经网络
-
发表了文章
2022-01-23
InceptionV3实战:tensorflow2.X版本,InceptionV3图像分类任务(大数据集)
-
发表了文章
2022-01-23
ResNet实战:tensorflow2.X版本,ResNet50图像分类任务(大数据集)
-
发表了文章
2022-01-23
ResNet实战:tensorflow2.X版本,ResNet50图像分类任务(小数据集)
-
发表了文章
2022-01-21
1. (arg0: bool) -> mediapipe.python._framework_bindings.packet.Packet
-
发表了文章
2022-01-20
DenseNet实战:tensorflow2.X版本,DenseNet121图像分类任务(大数据集)
-
发表了文章
2022-01-20
DenseNet实战:tensorflow2.X版本,DenseNet121图像分类任务(小数据集)
-
发表了文章
2022-01-19
2021AIWIN 手写体 OCR 识别竞赛总结(任务一)
滑动查看更多
暂无更多信息
暂无更多信息