能力说明:
了解Python语言的基本特性、编程环境的搭建、语法基础、算法基础等,了解Python的基本数据结构,对Python的网络编程与Web开发技术具备初步的知识,了解常用开发框架的基本特性,以及Python爬虫的基础知识。
 Apsara Clouder云计算专项技能认证:云服务器ECS入门
Apsara Clouder云计算专项技能认证:云服务器ECS入门
将不定期更新关于机器学习、强化学习、数据挖掘以及NLP等领域相关知识
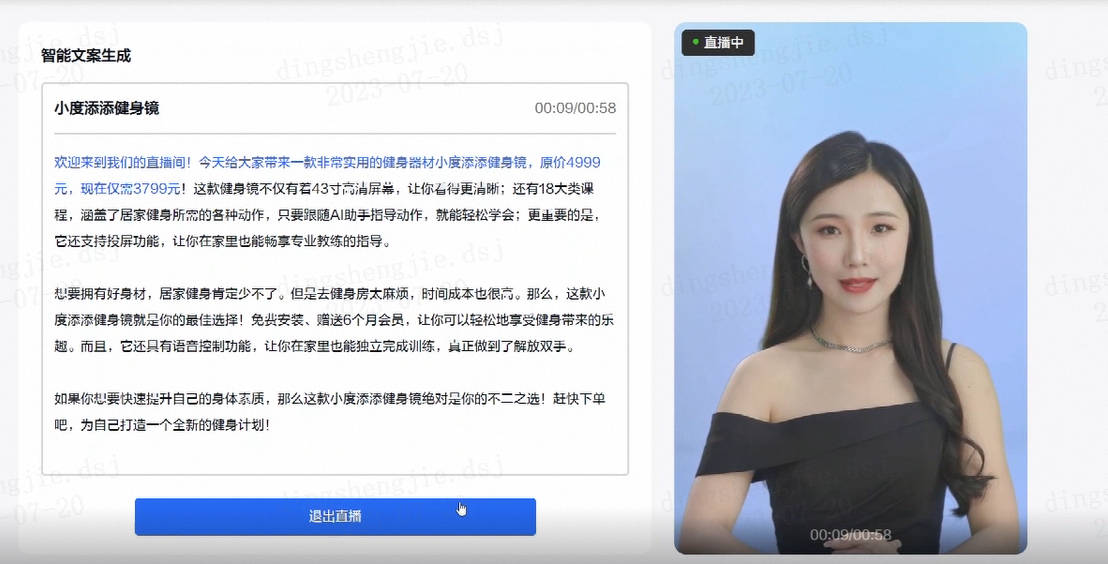
Prompt进阶3:LangGPT(构建高性能质量Prompt策略和技巧2)--稳定高质量文案生成器
Prompt进阶系列1:LangGPT(从编程语言反思LLM的结构化可复用提示设计框架)
结构化思维助力Prompt创作:专业化技术讲解和实践案例
智能咖啡厅助手:人形机器人 +融合大模型,行为驱动的智能咖啡厅机器人
AI与人类联手,智能排序人类决策:RLHF标注工具打造协同标注新纪元,重塑AI训练体验
遇见您的私人法律顾问:智能法律大模型,智能解答您的法律困惑
LLM资料大全:文本多模态大模型、垂直领域微调模型、STF数据集、训练微调部署框架、提示词工程等
跨越千年医学对话:用AI技术解锁中医古籍知识,构建能够精准问答的智能语言模型,成就专业级古籍解读助手(LLAMA)【2月更文挑战第1天】
医疗大模型:数据+知识双轮驱动实现医学推理、医患问答、病历自动生成、临床决策,为未来医疗服务提供全新可能性【2月更文挑战第3天】
Sora文生视频模型深度剖析:全网独家指南,洞悉98%关键信息,纯干货
NL2SQL进阶系列(4):ConvAI、DIN-SQL等16个业界开源应用实践详解[Text2SQL]
探索AI视频生成新纪元:文生视频Sora VS RunwayML、Pika及StableVideo——谁将引领未来
基于BiLSTM-CRF模型的分词、词性标注、信息抽取任务的详解,侧重模型推导细化以及LAC分词实践
知识图谱之图数据库如何选型:知识图谱存储与图数据库总结、主流图数据库对比(JanusGraph、HugeGraph、Neo4j、Dgraph、NebulaGraph、Tugrapg)
QAnything本地知识库问答系统:基于检索增强生成式应用(RAG)两阶段检索、支持海量数据、跨语种问答
探秘SuperCLUE-Safety:为中文大模型打造的多轮对抗安全新框架【2月更文挑战第2天】
深入理解TF-IDF、BM25算法与BM25变种:揭秘信息检索的核心原理与应用
英伟达系列显卡大解析B100、H200、L40S、A100、A800、H100、H800、V100如何选择,含架构技术和性能对比带你解决疑惑
Nougat:结合光学神经网络,引领学术PDF文档的智能解析、挖掘学术论文PDF的价值
聊天记录年度报告一览无余:轻松多格式导出永久保存,深度智能分析
全新Self-RAG框架亮相,自适应检索增强助力超越ChatGPT与Llama2,提升事实性与引用准确性
应对数据爆炸时代,揭秘向量数据库如何成为AI开发者的新宠,各数据库差异对比
Milvus 2.3.功能全面升级,核心组件再升级,超低延迟、高准确度、MMap一触开启数据处理量翻倍、支持GPU使用!
激发创新,助力研究:CogVLM,强大且开源的视觉语言模型亮相
Milvus性能优化提速之道:揭秘优化技巧,避开十大误区,确保数据一致性无忧,轻松实现高性能
ChatGLM3-6B:新一代开源双语对话语言模型,流畅对话与低部署门槛再升级
突破性的多语言代码大模型基CodeShell:引领AI编程新时代
Elasticsearch实战:常见错误及详细解决方案
ElasticSearch实战指南必知必会:安装分词器、高级查询、打分机制
ElasticSearch深度解析入门篇:高效搜索解决方案的介绍与实战案例讲解,带你避坑
多模态对比语言图像预训练CLIP:打破语言与视觉的界限
释放搜索潜力:基于ES(ElasticSearch)打造高效的语义搜索系统,让信息尽在掌握
logstash 与ElasticSearch:从CSV文件到搜索宝库的导入指南
ElasticSearch安装、插件介绍及Kibana的安装与使用详解
Elasticsearch Relevance Engine---为AI变革提供高级搜索能力[ES向量搜索、常用配置参数、聚合功能等详解]
大规模语言LLaVA:多模态GPT-4智能助手,融合语言与视觉,满足用户复杂需求
向量召回:深入评估离线体系,探索优质召回方法
挖掘文本的奇妙力量:传统与深度方法探索匹配之道
MetaGPT( The Multi-Agent Framework):颠覆AI开发的革命性多智能体元编程框架
数字时代的自我呈现:探索个人形象打造的创新工具——FaceChain深度学习模型工具
私密离线聊天新体验!llama-gpt聊天机器人:极速、安全、搭载Llama 2,尽享Code Llama支持!
开启中文智能之旅:探秘超乎想象的 Llama2-Chinese 大模型世界
FaceFusion:探索无限创意,创造独一无二的面孔融合艺术!
虚拟桌宠模拟器:VPet-Simulator,一个开源的桌宠软件, 可以内置到任何WPF应用程序
异常检测:探索数据深层次背后的奥秘《下篇》
异常检测:探索数据深层次背后的奥秘《中篇》
异常检测:探索数据深层次背后的奥秘《上篇》
解锁搜索新境界!让文本语义匹配助你轻松找到你需要的一切!(快速上手baseline)
探索图像数据中的隐藏信息:语义实体识别和关系抽取的奇妙之旅
开启智能时代:深度解析智能文档分析技术的前沿与应用
 发表了文章
2025-11-19
发表了文章
2025-11-07
发表了文章
2025-10-22
发表了文章
2025-09-26
发表了文章
2025-09-23
发表了文章
2025-09-18
发表了文章
2025-09-17
发表了文章
2025-09-08
发表了文章
2025-09-02
发表了文章
2025-08-28
发表了文章
2025-08-22
发表了文章
2025-08-07
发表了文章
2025-08-06
发表了文章
2025-07-25
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-11-19
发表了文章
2025-11-07
发表了文章
2025-10-22
发表了文章
2025-09-26
发表了文章
2025-09-23
发表了文章
2025-09-18
发表了文章
2025-09-17
发表了文章
2025-09-08
发表了文章
2025-09-02
发表了文章
2025-08-28
发表了文章
2025-08-22
发表了文章
2025-08-07
发表了文章
2025-08-06
发表了文章
2025-07-25
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20
发表了文章
2025-07-20

 回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-16
回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-03-03
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-28
回答了问题
2023-02-16