







云原生时代的架构革新,Apache Doris 存算分离如何实现弹性与性能双重提升
随着云基础设施的成熟,Apache Doris 3.0 正式支持了存算分离全新模式。基于这一架构,能够实现更低成本、极致弹性以及负载隔离。本文将介绍存算分离架构及其优势,并通过导入性能、查询性能、资源成本的测试,直观展现存算分离架构下的性能表现,为读者提供具体场景下的使用参考。


Lindorm作为AI搜索基础设施,助力Kimi智能助手升级搜索体验
月之暗面旗下的Kimi智能助手在PC网页、手机APP、小程序等全平台的月度活跃用户已超过3600万。Kimi发布一年多以来不断进化,在搜索场景推出的探索版引入了搜索意图增强、信源分析和链式思考等三大推理能力,可以帮助用户解决更复杂的搜索、调研问题。Lindorm作为一站式数据平台,覆盖数据处理全链路,集成了离线批处理、在线分析、AI推理、融合检索(正排、倒排、全文、向量......)等多项服务,支持Kimi快速构建AI搜索基础设施,显著提升检索效果,并有效应对业务快速发展带来的数据规模膨胀和成本增长。
世界第一!阿里云PolarDB登顶全球数据库性能及性价比排行榜!
2月26日,阿里云PolarDB在2025开发者大会上登顶全球数据库性能及性价比排行榜。此次突破标志着中国基础软件取得里程碑成就,PolarDB凭借创新的云原生架构,成功应对全球最大规模并发交易峰值,在性能、可扩展性等方面领先全球。
刷新世界纪录!阿里云登顶全球数据库性能及性价比排行榜
阿里云PolarDB云原生数据库在TPC-C测试中登顶全球性能及性价比排行榜。此次突破展示了PolarDB在单核性能、横向扩展及软硬件结合上的创新,标志着中国基础软件的重大成就。

SelectDB 实时分析性能突出,宝舵成本锐减与性能显著提升的双赢之旅
BOCDOP 宝舵早期基于 TiDB 构建实时数仓,随着数据量增长,在数据处理效率、OLAP 能力扩展、功能支持、成本与资源方面存在一定优化空间。**为提升数据分析能力并优化成本,宝舵引入 [SelectDB](https://www.selectdb.com/?utm_source=selectdbwechat&utm_medium=1&utm_campaign=post),达成写入速度提升 10 倍,成本直降 30% 的显著成效。

AI时代,数据库如何为大模型注入生命力?
要真正打造有价值、有生产力的AI应用,一个关键环节常被低估——那就是数据库。 在AI时代,数据库究竟如何为大模型注入生命力? 视频转载自量子位B站
极速突破,PolarDB MySQL 列存索引加速复杂查询,完成任务可领取200社区积分!
借助云原生数据库 PolarDB MySQL 版的列存索引(IMCI),解决大数据量下的高性能复杂查询问题。参与活动完成任务即可领取200社区积分,还有机会抽取福禄寿淘公仔等好礼!
无缝集成 MySQL,解锁秒级 OLAP 分析性能极限,完成任务可领取三合一数据线!
通过 AnalyticDB MySQL 版、DMS、DTS 和 RDS MySQL 版协同工作,解决大规模业务数据统计难题,参与活动完成任务即可领取三合一数据线(限量200个),还有机会抽取蓝牙音箱大奖!
【直播回放】MongoDB全球开发者认证介绍线上直播 助力您掌握企业级实战能力
想通过MongoDB认证提升竞争力却无从下手?这场线上直播为你解惑!权威解读考试大纲、题型与评分标准,资深专家分享备考策略,涵盖学习计划、实战技巧及心理调整。更有最新认证激励政策、专属徽章与大礼包等你解锁!无论你是开发者、管理员还是学生,都能为职业发展铺路。立即预约3月26日直播回放,与MongoDB专家互动答疑,轻松迈向专业高峰!
【活动回顾】StarRocks Singapore Meetup #2 @Shopee
3 月 13 日,StarRocks 社区在新加坡成功举办了第二场 Meetup 活动,主题为“Empowering Customer-Facing Analytics”。本次活动在 Shopee 新加坡办公室举行,吸引了来自 Shopee、Grab 和 Pinterest 的专家讲师以及 50 多位参会者。大家围绕电商、BI 报表和广告场景中的数据分析挑战展开了深入探讨,并分享了如何利用 StarRocks 为关键业务提供更快、更精准的数据分析解决方案。


DMS+X:GenAI时代的一站式Data+AI平台
本视频为Data+AI Workshop(深圳站)活动分享,主要内容介绍阿里云DMS+X平台,在生成式人工智能(GenAI)时代的功能特性,展示其如何整合数据与AI资源,打造一站式Data+AI平台,助力企业提升数据管理与AI应用效率。咨询AI专家:https://survey.aliyun.com/apps/zhiliao/CM-3QOQlI

PolarDB for AI客户案例与最佳实践
本视频为Data+AI Workshop(深圳站)活动分享,主要内容通过分享多个PolarDB for AI的实际客户案例,讲师复盘从项目启动到落地的全过程,总结出通用的最佳实践经验,为正在或计划采用该技术的企业提供实操参考。咨询AI专家:https://survey.aliyun.com/apps/zhiliao/CM-3QOQlI

PolarDB for Al:打造SQL驱动的一体化数据智能基础应用
本视频为Data+AI Workshop(深圳站)活动分享,主要内容介绍聚焦SQL驱动理念,讲师深入讲解PolarDB for AI如何搭建一体化数据智能基础应用,剖析该技术在数据智能领域从数据处理到应用输出的全流程运作机制,为技术和业务人员提供从理论到实操的系统性指导。咨询AI专家:https://survey.aliyun.com/apps/zhiliao/CM-3QOQlI

PolarDB for AI,助力企业拥抱AI新时代
本视频为Data+AI Workshop(深圳站)活动分享,主要内容介绍PolarDB for AI,阐述其在当下AI浪潮中,如何赋能企业,帮助企业快速拥抱AI新时代,为企业的数字化转型提供方向指引。咨询AI专家:https://survey.aliyun.com/apps/zhiliao/CM-3QOQlI
列表结构与树结构转换分析与工具类封装(java版)
本文介绍了将线性列表转换为树形结构的实现方法及工具类封装。核心思路是先获取所有根节点,将其余节点作为子节点,通过递归构建每个根节点的子节点。关键在于节点需包含 `id`、`parentId` 和 `children` 三个属性。文中提供了两种封装方式:一是基于基类 `BaseTree` 的通用工具类,二是使用函数式接口实现更灵活的方式。推荐使用后者,因其避免了继承限制,更具扩展性。代码示例中使用了 Jackson 库进行 JSON 格式化输出,便于结果展示。最后总结指出,理解原理是进一步优化和封装的基础。
Dify实践|Dify on DMS+对象存储OSS,实现多副本部署方案
本文介绍了在DMS上部署Dify的详细步骤,用户可选择一键购买资源或基于现有资源部署Dify,需配置RDS PostgreSQL、Redis、AnalyticDB for PostgreSQL等实例,并设置存储路径和资源规格。文中还提供了具体配置参数说明及操作截图,帮助用户顺利完成部署。
MyBatis Plus 使用 Service 接口进行增删改查
本文介绍了基于 MyBatis-Plus 的数据库操作流程,包括配置、实体类、Service 层及 Mapper 层的创建。通过在 `application.yml` 中配置 SQL 日志打印,确保调试便利。示例中新建了 `UserTableEntity` 实体类映射 `sys_user` 表,并构建了 `UserService` 和 `UserServiceImpl` 处理业务逻辑,同时定义了 `UserTableMapper` 进行数据交互。测试部分展示了查询、插入、删除和更新的操作方法及输出结果,帮助开发者快速上手 MyBatis-Plus 数据持久化框架。
MyBatis篇-映射关系(1-1 1-n n-n)
本文介绍了MyBatis中四种常见关系映射的配置方法,包括一对一、一对多、多对一和多对多。**一对一**通过`resultMap`实现属性与字段的映射;**一对多**以用户-角色为例,使用`<collection>`标签关联集合数据;**多对一**以作者-博客为例,利用`<association>`实现关联;**多对多**则通过引入第三方类(如UserForDept)分别在User和Dept类中添加集合属性,并配置对应的`<collection>`标签完成映射。这些方法解决了复杂数据关系的处理问题,提升了开发效率。
MyBatis篇-常见配置
本文介绍了 MyBatis 的常见配置及事务管理相关内容。首先概述了 MyBatis 属性加载顺序,方法参数属性优先级最高。接着列举了几个常见配置属性,如 cacheEnabled、lazyLoadingEnabled 等,并说明其作用与默认值。在多环境配置部分,讲解如何通过 SqlSessionFactoryBuilder 指定环境,以及 environments 元素的配置细节。最后讨论了两种事务管理模式:JDBC 和 MANAGED,分别适用于不同场景,并指出在使用 Spring 模块时无需额外配置事务管理器。
MyBatis篇-分页
本文介绍了多种分页方式,包括自带rowbound内存分页、第三方插件pagehelper(通过修改SQL实现分页)、SQL分页(依赖limit或rownum等关键字)、数组分页(先查询全部数据再用subList分页)、拦截器分页(自定义拦截器为SQL添加分页语句)。最后总结了逻辑分页(内存分页,适合小数据量)和物理分页(直接在数据库层面分页,适合大数据量)的优缺点,强调物理分页优先于逻辑分页。

MongoDB实战演练
本文介绍了基于Spring Boot和MongoDB实现文章评论功能的完整流程。主要包括需求分析、表结构设计、技术选型(如mongodb-driver与SpringDataMongoDB)、项目搭建及配置、实体类编写、基本增删改查功能实现、分页查询以及点赞功能的开发。通过Comment实体类、CommentRepository接口和CommentService服务层,实现了评论的存储、查询及更新操作,并利用MongoTemplate优化了点赞功能的性能。最后通过JUnit测试验证各功能的正确性。该方案适合需要高效处理非结构化数据的文章评论系统开发。
MongoDB常用命令
本文介绍了将文章评论数据存储到MongoDB中的操作方法,包括数据库和集合的基本操作。主要内容涵盖:选择与创建数据库(如`articledb`)、数据库删除、集合的显式与隐式创建及删除、文档的CRUD操作(插入、查询、更新、删除)。此外,还详细说明了分页查询、排序查询以及统计查询的方法,例如使用`limit()`、`skip()`实现分页,`sort()`进行排序,`count()`统计记录数。通过实例展示了如何高效管理MongoDB中的数据。
MongoDB索引知识
MongoDB索引是提升查询性能的关键工具,通过构建特殊的数据结构(如B树)优化数据访问路径。无索引时,查询需全集合扫描,时间复杂度为O(n);使用索引后可降至O(log n),实现毫秒级响应。MongoDB支持多种索引类型:单字段索引适用于高频单字段查询;复合索引基于最左前缀原则优化多条件过滤和排序;专业索引包括地理空间索引(支持LBS服务)、文本索引(全文搜索)和哈希索引(分片键优化)。合理选择和优化索引类型,可显著提升数据库性能。建议使用explain()分析查询计划,并定期清理冗余索引。
MongoDB单机部署
本文介绍了在Windows和Linux系统上安装与启动MongoDB的方法,包括命令行参数启动和配置文件启动两种方式。详细说明了创建数据目录、配置文件的编写及常见问题解决方法。同时,还提供了通过mongo命令连接数据库的操作,以及使用MongoDB Compass图形化客户端的方式。对于Linux系统,重点讲解了从下载到配置、启动服务的全过程,并涉及防火墙设置和关闭服务的方法,帮助用户顺利完成单机环境下的MongoDB部署与管理。
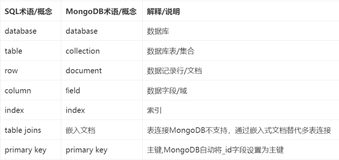
MongoDB相关概念
MongoDB是一款开源、高性能的文档型数据库,适用于高并发读写、海量数据存储及高可扩展性需求的场景。它以BSON格式存储数据,支持灵活的无模式数据结构,适合社交、游戏、物流、物联网和视频直播等应用。相比传统关系型数据库(如MySQL),MongoDB在处理大规模、低事务性要求的数据时更具优势。其特点包括高性能(嵌入式数据模型减少I/O)、高可用性(副本集自动故障转移)和高扩展性(分片技术实现水平扩展)。此外,MongoDB还提供丰富的查询功能,如文本搜索、地理位置索引等,满足多样化需求。

MiniMax GenAI 可观测性分析 :基于阿里云 SelectDB 构建 PB 级别日志系统
基于阿里云SelectDB,MiniMax构建了覆盖国内及海外业务的日志可观测中台,总体数据规模超过数PB,日均新增日志写入量达数百TB。系统在P95分位查询场景下的响应时间小于3秒,峰值时刻实现了超过10GB/s的读写吞吐。通过存算分离、高压缩比算法和单副本热缓存等技术手段,MiniMax在优化性能的同时显著降低了建设成本,计算资源用量降低40%,热数据存储用量降低50%,为未来业务的高速发展和技术演进奠定了坚实基础。
Java 字符串详解
本文介绍了 Java 中的三种字符串类型:String、StringBuffer 和 StringBuilder,详细讲解了它们的区别与使用场景。String 是不可变的字符串常量,线程安全但操作效率较低;StringBuffer 是可变的字符串缓冲区,线程安全但性能稍逊;StringBuilder 同样是可变的字符串缓冲区,但非线程安全,性能更高。文章还列举了三者的常用方法,并总结了它们在不同环境下的适用情况及执行速度对比。
如何在MySQL中创建定时任务?
MySQL 事件调度器(Event Scheduler)可实现定时任务自动化。例如,每天凌晨清空 `test` 表,并在一个月后自动停止任务。需先启用调度器(`SET GLOBAL event_scheduler = ON`),再创建事件(使用 `CREATE EVENT` 定义执行频率和操作)。推荐用 `TRUNCATE` 提高效率,注意权限与时区设置。为防数据丢失,可结合备份机制。到期后事件自动禁用,建议定期清理。
Tablestore集成MCP协议: 标量与向量混合检索的新范式
基于表格存储(Tablestore)实现的MCP(Model Context Protocol)服务,支持文档存储与混合检索工具两大功能。通过Cherry-Studio界面和通义千问qwen-max模型进行演示,展示了文本数据上传、向量嵌入及查询过程。此外,详细说明了Python和Java版本的本地运行步骤、环境配置及二次开发方法,并提供了集成三方工具如Cherry Studio的应用示例。Tablestore凭借混合查询、Serverless低成本、弹性扩展等优势,为MCP场景提供高效解决方案。
StarRocks + Paimon 在阿里集团 Lakehouse 的探索与实践
阿里集团在推进湖仓一体化建设过程中,依托 StarRocks 强大的 OLAP 查询能力与 Paimon 的高效数据入湖特性,实现了流批一体、存储成本大幅下降、查询性能数倍提升的显著成效: A+ 业务借助 Paimon 的准实时入湖,显著降低了存储成本,并引入 StarRocks 提升查询性能。升级后,数据时效提前60分钟,开发效率提升50%;JSON列化存储减少50%,查询性能提升最高达10倍;OLAP分析中,非JOIN查询快1倍,JOIN查询快5倍。 饿了么升级为准实时Lakehouse架构后,在时效性仅损失1-5分钟的前提下,实现Flink资源缩减、StarRocks查询性能提升(仅5%
微信基于 StarRocks 的实时因果推断实践
本文介绍了因果推断在业务中的应用,详细阐述了基于 StarRocks 构建因果推断分析工具的技术方案,通过高效算子的支持,大幅提升了计算效率。例如,t 检验在 6亿行数据上的执行时间仅需 1 秒。StarRocks 还实现了实时数据整合,支持多种数据源(如 Iceberg 和 Hive)的无缝访问,进一步增强了平台的灵活性与应用价值。
简单聊聊MySQL的三大日志(Redo Log、Binlog和Undo Log)各有什么区别
在MySQL数据库管理中,理解Redo Log(重做日志)、Binlog(二进制日志)和Undo Log(回滚日志)至关重要。Redo Log确保数据持久性和崩溃恢复;Binlog用于主从复制和数据恢复,记录逻辑操作;Undo Log支持事务的原子性和隔离性,实现回滚与MVCC。三者协同工作,保障事务ACID特性。文章还详细解析了日志写入流程及可能的异常情况,帮助深入理解数据库日志机制。
NineData社区版正式上线,支持一键本地化部署!
3月10日,玖章算术正式发布NineData社区版,这是一款免费、一键安装的数据管理解决方案,支持本地化部署,保障数据隐私与合规。它包含数据库DevOps、数据复制和数据库对比三大核心功能,适用于MySQL、PostgreSQL和Doris等数据库的数据迁移。基于Docker技术,用户可通过简单命令完成安装,特别适合内网环境及中小企业使用,助力高效的数据管理和成本控制。
云数据库是什么数据库?
云数据库是部署在云计算环境中的数据库服务,用户无需自行搭建硬件和软件环境,通过互联网即可便捷使用。相比传统数据库,云数据库降低了成本和使用门槛,具备强大的扩展性和灵活性,支持多种数据存储模型,并借鉴了关系型数据库的特性如ACID事务处理。它能够应对海量数据和高并发访问需求,适应数字化时代的挑战,未来还将融合更多新技术,进一步提升其功能和应用范围。
小鹏汽车选用阿里云PolarDB,开启AI大模型训练新时代
PolarDB-PG云原生分布式数据库不仅提供了无限的扩展能力,还借助丰富的PostgreSQL生态系统,统一了后台技术栈,极大地简化了运维工作。这种强大的组合不仅提高了系统的稳定性和性能,还为小鹏汽车大模型训练的数据管理带来了前所未有的灵活性和效率。

数据库
数据库领域前沿技术分享与交流

