
ModelScope中,为什么日志这里显示只有mix_dataset_sample: 76 ?
"请问现在使用自定义数据集的两个数据集,同时融合部分 ms-bench-mini --train_dataset_mix_ratio 0.05 \ --train_dataset_mix_ds ms-bench-mini \ --custom_train_dataset_path self.jsonl ruozhiba_qa_train.jsonl \日志打印如下: 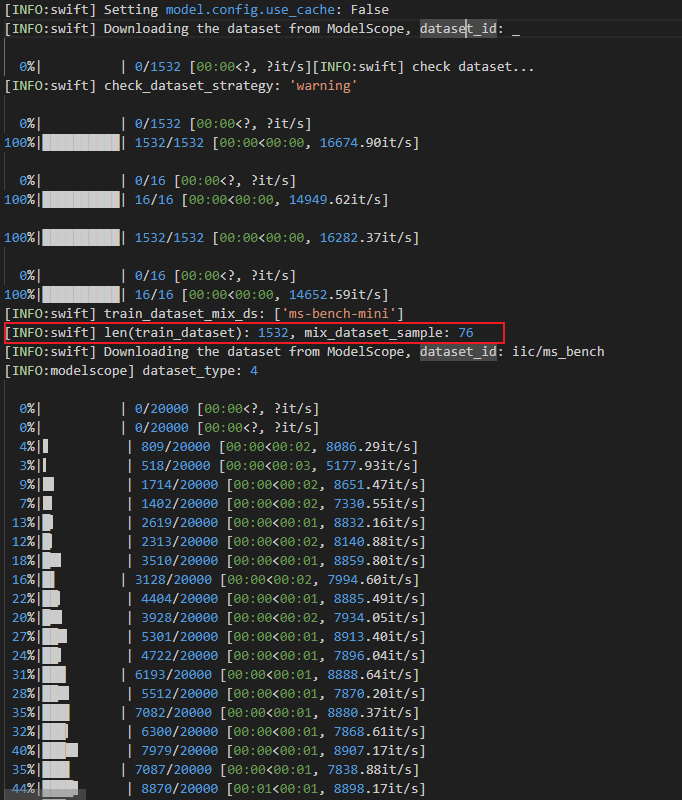
ModelScope中,为什么日志这里显示只有mix_dataset_sample: 76 ?"
-

"import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0' 参考以下代码
nproc_per_node=2
CUDA_VISIBLE_DEVICES=0,1 \
NPROC_PER_NODE=$nproc_per_node \
MASTER_PORT=29500 \
nohup swift sft \
--model_id_or_path /data/models/Baichuan2-13B-Chat \
--model_type baichuan-13b-chat \
--model_revision master \
--template_type baichuan \
--sft_type lora \
--tuner_backend peft \
--dtype AUTO \
--ddp_backend nccl \
--train_dataset_mix_ratio 0.9 \
--train_dataset_mix_ds ms-bench-mini \
--custom_train_dataset_path /data/dataset/sft/self.jsonl /data/dataset/sft/ruozhiba_qa_train.jsonl \
--num_train_epochs 5 \
--max_length 1024 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--lora_dtype AUTO \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0.1 \
--learning_rate 1e-4 \
--gradient_accumulation_steps $(expr 16 / $nproc_per_node) \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 5 \
--use_flash_attn false \
--deepspeed default-zero3 \
--save_only_model true \
--self_cognition_sample 200 \
--model_name PPT助手 'PPTASS' \
--model_author 陶喆 taozhe \
--add_output_dir_suffix False \
--output_dir /data/train-models/sft/lora/baichuan2-13b-chat/ \
--logging_dir /data/train-models/sft/lora/baichuan2-13b-chat/runs \> /data/train-models/sft/lora/baichuan2-13b-chat/runs/run.log 2>&1 & 此回答整理自钉群“魔搭ModelScope开发者联盟群 ①” "2024-05-01 16:01:46赞同 1 展开评论 打赏
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352
热门讨论
热门文章


相关文章
相关电子书
更多

