
flink 从业务库同步到holo,用ADTS的方式,怎么创建SQL ?
flink 从业务库同步到holo,业务库的库表名是cmc.comm_cinema 同步到holo,希望同步到holo的表名是ods.cmc_comm_cinema , 用ADTS的方式,怎么创建SQL ?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
在 Apache Flink 中,使用 ADTS(Alibaba Data Transmission Service)进行数据同步时,通常涉及到两个步骤:第一步是从源数据库读取数据,第二步是将数据写入目标数据库。在这个过程中,你可以使用 Flink SQL 来定义数据转换和同步的逻辑。
根据你的需求,你想要从业务库
cmc.comm_cinema表同步到 Holo 数据库的ods.cmc_comm_cinema表。以下是创建 SQL 查询的基本步骤:定义源表 (
cmc.comm_cinema):
首先,你需要定义一个源表,用于从业务库读取数据。这通常涉及到指定表名、数据库名以及相应的字段类型。定义目标表 (
ods.cmc_comm_cinema):
然后,你需要定义一个目标表,用将数据插入到 Holo 数据库中的对应表。同样,这需要指定表名、数据库名以及字段类型。编写同步 SQL:
最后,你需要编写一个 SQL 查询,该查询将从源表中选择所有数据,并将其插入到目标表中。
以下是一个简化的示例,了如何编写 SQL 查询来实现这个同步过程:
-- 定义源表结构 CREATE TABLE cmc_comm_cinema ( -- 这里列出源表的所有字段及其类型 ) WITH ( 'connector' = 'jdbc', -- 假设你使用 JDBC 连接源数据库 'url' = 'jdbc:mysql://<hostname>:<port>/cmc', 'table-name' = 'comm_cinema', -- 其他连接参数,如用户名、密等 ); -- 定义目标表结构 CREATE TABLE ods_cmc_comm_cinema ( -- 这里列出目标表的所有字段及其类型 ) WITH ( 'connector' = 'holo', -- 假设你使用 Holo 作为目标数据库 -- Holo 的相关配置参数 ); -- 同步数据 INSERT INTO ods_cmc_comm_cinema SELECT * FROM cmc_comm_cinema;请注意,上述代码是一个简化的示例,你需要根据实际情况调整字段类型、连接参数等。确保你的 Flink 环境已经配置了对应的连接器(如 JDBC 和 Holo)。
在实际操作中,你可能需要根据实际的源表和目标表的结构来定义字段列表和类型,以及根据实际的数据库连接信息来配置 URL、用户名、密码等参数。此外,如果源表和目标表的结构不完全匹配,你可能还需要在 SQL 查询中添加适当的转换逻辑。
2024-03-29 15:10:11赞同 1 展开评论 -
阿里云大降价~
在Flink中,使用ADTS方式同步数据需要先创建源表和目标表,然后编写SQL语句进行数据同步。
首先,需要在业务库中创建源表cmc.comm_cinema,然后在Holo中创建目标表ods.cmc_comm_cinema。具体建表语句如下:
```sql
-- 创建源表
CREATE TABLE cmc.comm_cinema (
id INT,
name VARCHAR(50),
address VARCHAR(100)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://loca2024-03-27 15:50:23赞同 展开评论 -
您好,CDAS目前不支持加表名前缀,只能放入不同的schema中
在with参数里指定 schemaname 即可:https://help.aliyun.com/zh/flink/user-guide/manage-hologres-catalogs?spm=a2c4g.11186623.0.i2#b4aee380e20ck
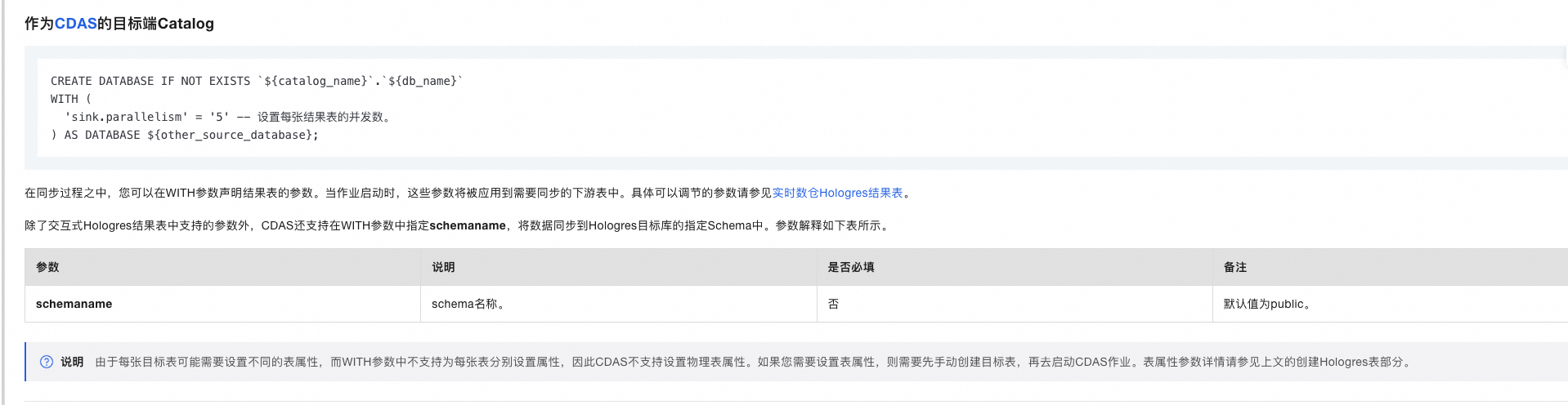
此回答整理自钉群“实时计算Flink产品交流群”2024-03-27 15:46:49赞同 展开评论 -
Apache Flink 提供了多种方式实现从业务数据库到 Hologres 的数据同步,这里假设您使用的是 Flink SQL 来完成这项任务,并且打算通过 ADTS (阿里云 Data Transmission Service) 连接器同步数据。尽管目前 Flink 官方并未提供直接连接 Hologres 的 ADTS 连接器,但您可以利用 Flink JDBC Sink 连接到 Hologres 的 JDBC 接口。
以下是一个示例,展示如何使用 Flink SQL 创建一个从源数据库表同步到 Hologres 表的作业,其中源表名为 cmc.comm_cinema,目标表名为 ods.cmc_comm_cinema:
-- 创建源表 CREATE TABLE source_table ( -- 定义源表的字段,根据实际业务库表结构调整 field1 STRING, field2 INT, -- 更多字段... ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://<your_mysql_host>:<mysql_port>/<database>', 'table-name' = 'cmc.comm_cinema', 'username' = '<your_mysql_username>', 'password' = '<your_mysql_password>' ); -- 创建目标Hologres表 CREATE TABLE target_table ( -- 定义目标表的字段,应与源表字段一一对应 field1 STRING, field2 INT, -- 更多字段... ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:hologres://<your_hologres_endpoint>:<hologres_port>/<database>', 'table-name' = 'ods.cmc_comm_cinema', 'username' = '<your_hologres_username>', 'password' = '<your_hologres_password>' ); -- 同步数据 INSERT INTO target_table SELECT * FROM source_table;请替换 <...> 内的占位符为您的实际数据库连接参数。
2024-03-27 15:16:23赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。