
Flink CDC里整库同步的时候,因为源表有写字段是大文本,怎么解决同步问题?
Flink CDC里整库同步的时候,因为源表有写字段是大文本:longblob、text等等,这时候CDC就无法同步数据了,如何解决这个问题吗?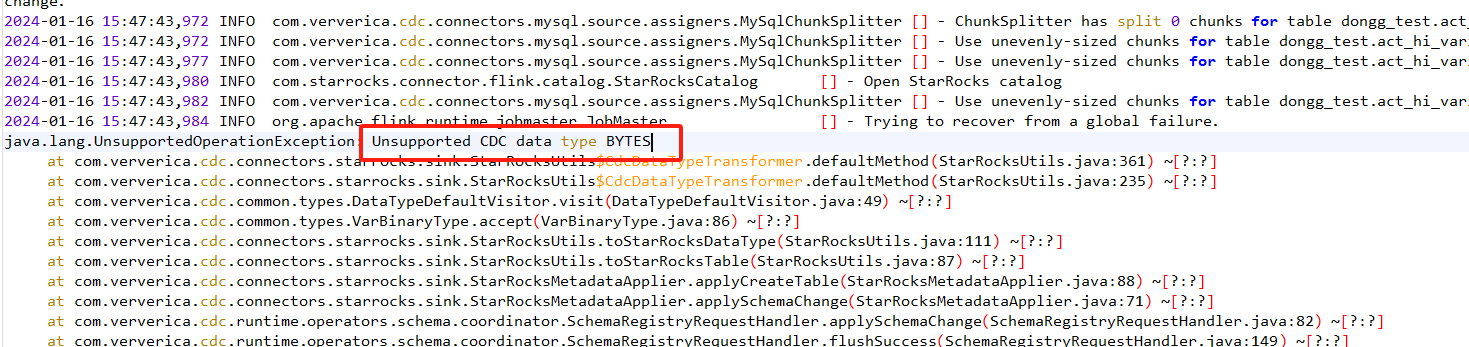
展开
收起
1
条回答
 写回答
写回答
-

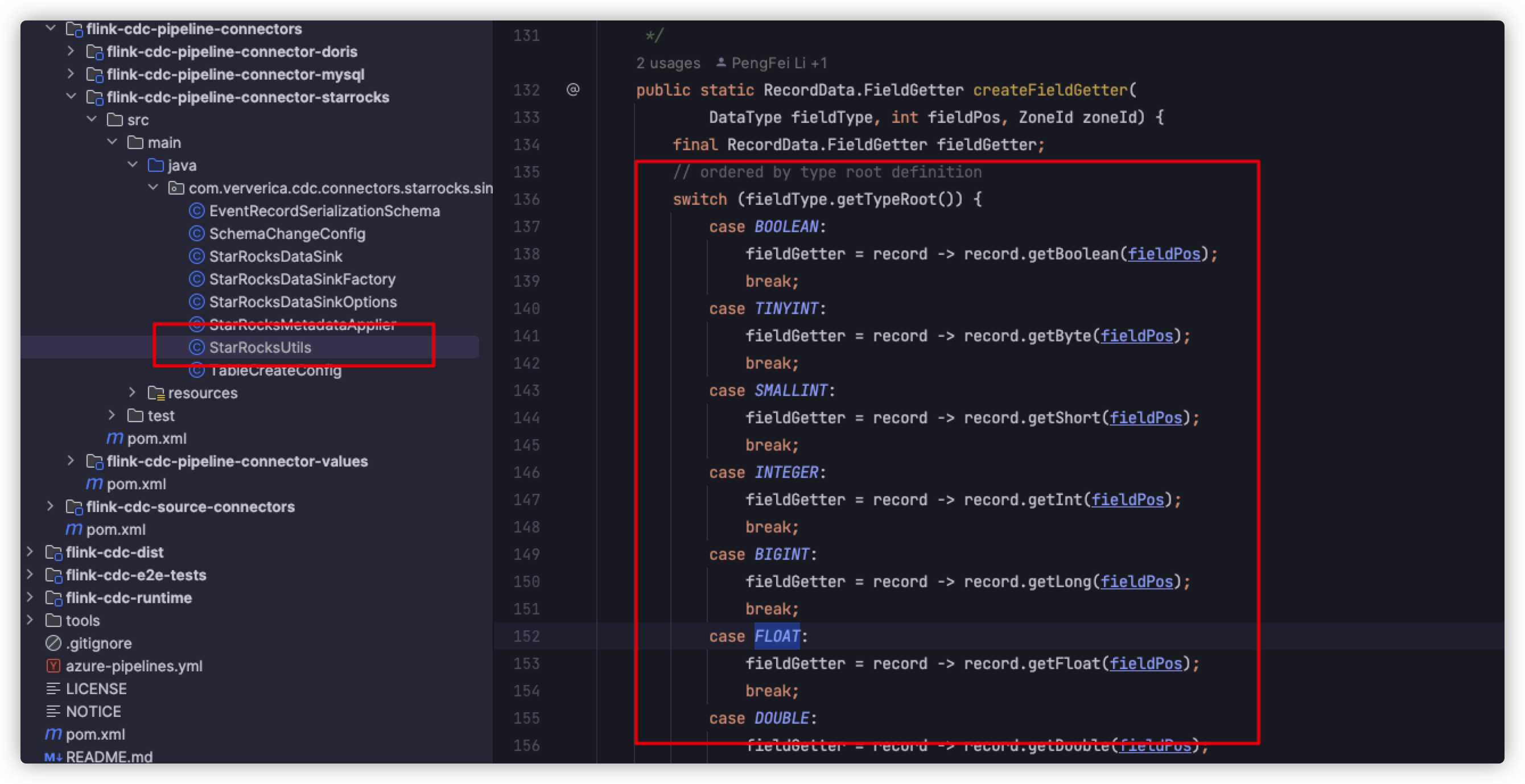
改下StarRocksUtils这个类的createFieldGetter方法,使其支持下bytes格式。
 此回答来自钉群Flink CDC 社区。2024-01-24 18:10:29赞同 展开评论 打赏
此回答来自钉群Flink CDC 社区。2024-01-24 18:10:29赞同 展开评论 打赏
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
热门讨论
热门文章
flink的1cu是指1cpu还是1cpu+4g存储?
253
FlinkCDC MySQL 中 scan.startup.mode 用的是什么模式啊?
1924
各位老师,请教个问题,flink 会在本地 /tmp 目录下产生大量flink-临时文件,目前看好?
1221
Flink的ci/cd能力今年什么时候会发布?
41
现在的环境是flink1.18.1,现在使用jar提交代码报这个错误,有遇到过吗?
38
flink 批处理 使用table去读取MySQL的数据,报这个
2262
Flink这边看输入记录数有个波谷,但输入的表数据是比较均匀的,可能是啥原因?
34
flink 1.18必须配套JDK11吗 1.8是不是不行了呢?
932
编译flinkcdc 3.0.1 版本,jdk 版本有要求吗?
33
flinkcdc 自动建表只支持3.0的pipline方式吗?
33
展开全部
流批一体技术简介
27847
数据仓库介绍与实时数仓案例
40373
权威详解 | 阿里新一代实时计算引擎 Blink,每秒支持数十亿次计算
22284
OPPO数据中台之基石:基于Flink SQL构建实数据仓库
20936
分布式Snapshot和Flink Checkpointing简介
19121
独家专访阿里集团副总裁贾扬清:我为什么选择加入阿里巴巴?
17249
实时计算 Flink SQL 核心功能解密
18654
Flink SQL 功能解密系列 —— 维表 JOIN 与异步优化
26372
Flume+Kafka+Flink+Redis构建大数据实时处理系统:实时统计网站PV、UV展示
21672
阿里云实时计算产品案例&解决方案汇总
25758
展开全部
相关课程
更多

相关文章
相关电子书
更多


