
DataWorks为什么在数据分析下查询出来的数据会出现覆盖情况呢?两个表都有相同的字段会出现覆盖其中一个?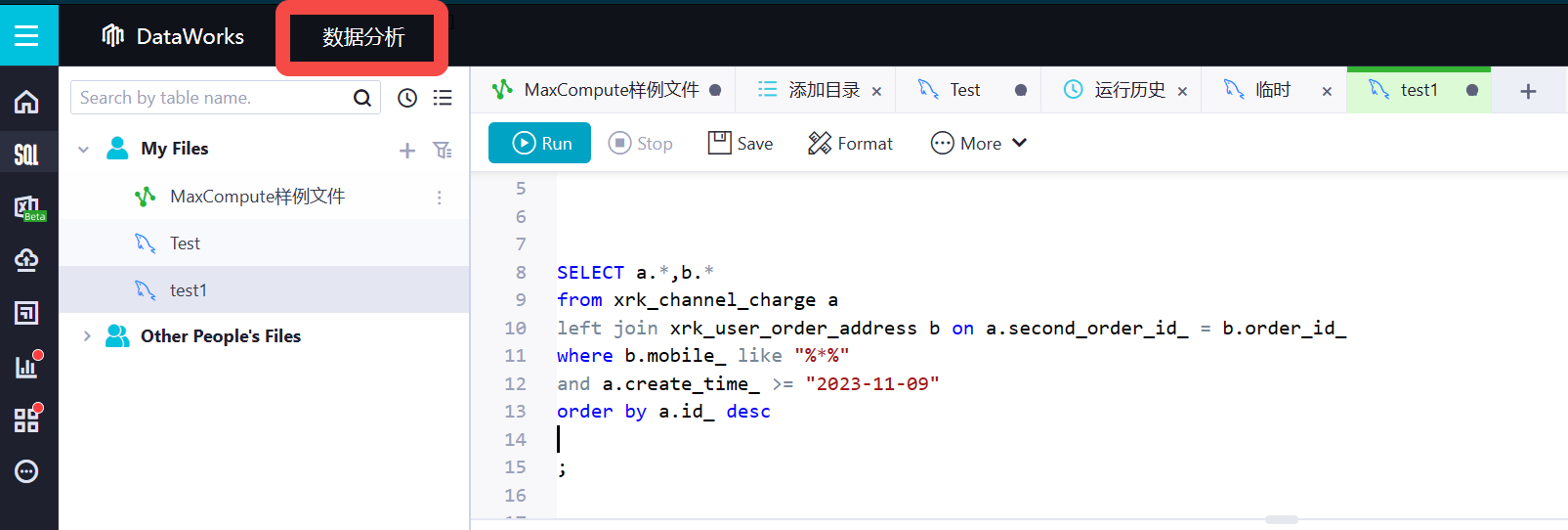
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
DataWorks在数据分析下查询出来的数据出现覆盖情况可能有多种原因。以下是一些可能的原因:
要解决这个问题,可以尝试以下方法:
在DataWorks中,如果两个表有相同字段,但在JOIN操作或聚合操作之后的结果集中,可能出现数据覆盖的情况。
这种情况通常是由于JOIN或聚合操作之后结果集中字段重名引起的。由于DataWorks无法确定哪个字段对应哪个表,因此它会简单地将重复字段合并在一起,可能导致数据覆盖。
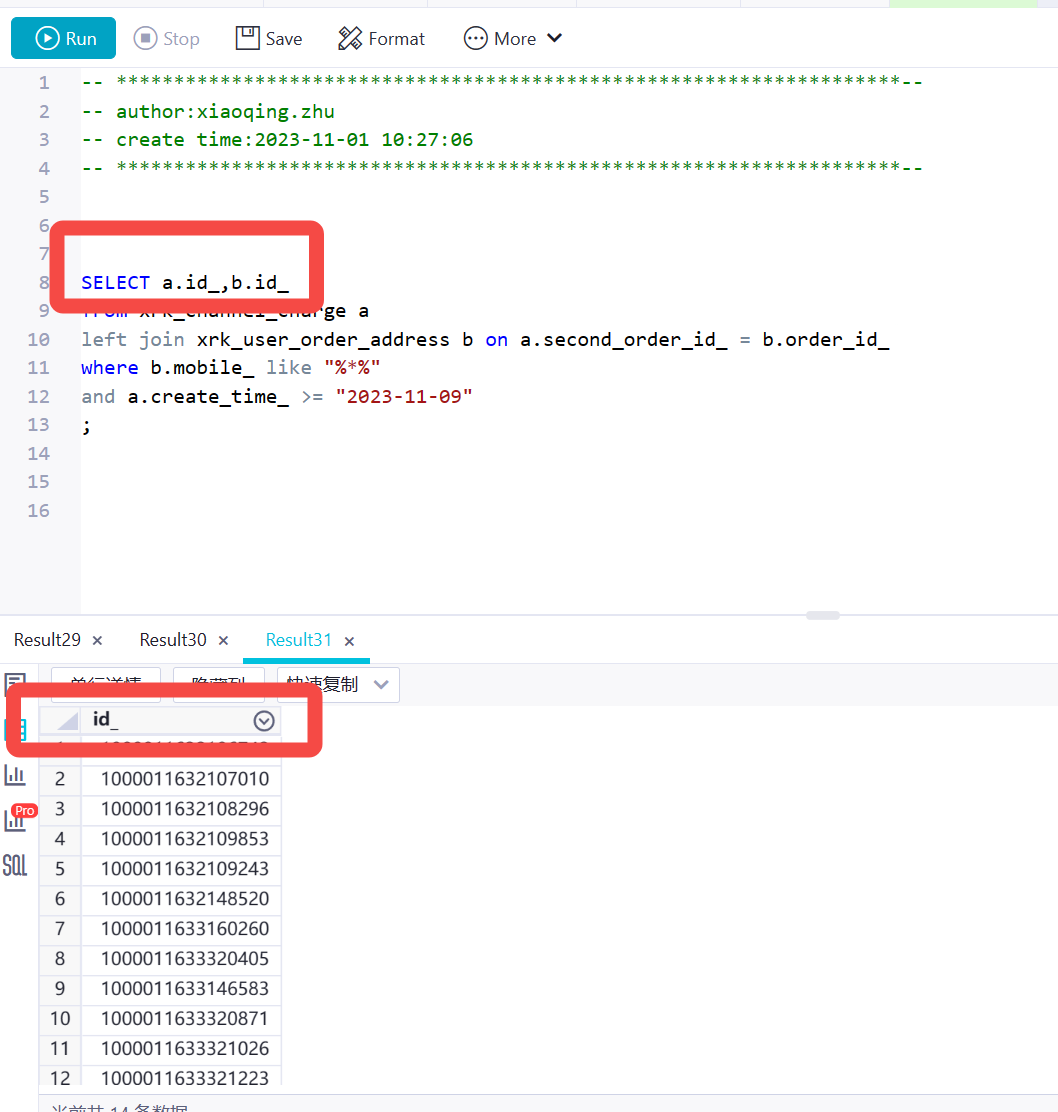
为了避免这种情况发生,建议您在JOIN或聚合操作之前给每个表的字段添加别名,以确保字段名称唯一。例如:
SELECT t1.field1 as field1_t1, t2.field1 as field1_t2 FROM table1 t1 JOIN table2 t2 ON t1.id = t2.id;
这样,在结果集中就不会出现字段重名的情况,也不会发生数据覆盖。
另外,您还可以通过调整JOIN或聚合操作的顺序和规则,以确保数据不会发生覆盖。例如,可以优先JOIN具有较少记录的表,并尽可能保留原始字段名称,以防止字段重名。
查询了两个字段 实际只展示了一个字段是吗 运行日志里有份logview 辛苦点开看下里面的result是几列,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


