
大数据计算MaxCompute我由张表有24列,每列对应一个运行数据,字段见T1、T2.....T24。
每个小时,我会接到一批数据,数据可能会是T1、T2.....T24中随机一批谁。
有什么更高效的方式将数据维护到各列中去不?数据量没有行专列之前是千万级的,转之后是百万级的?DI从接到ODPS的接口表,数据格式是:设备ID、小时、运行数据。如:需要转成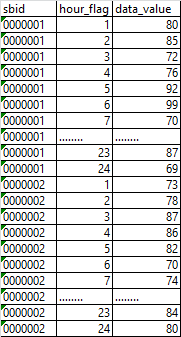

来一批更新一批
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
对于您的情况,可以考虑使用MaxCompute中的批量插入功能来提高数据插入效率。具体来说,您可以将每个小时接收到的数据按照列的顺序打包成一个数组或列表,然后一次性将整个数组或列表插入到表中。
例如,假设您要插入的数据为:
{
"T1": "value1",
"T2": "value2",
"T3": "value3",
...
}
您可以将其打包成一个JSON字符串,然后使用批量插入的方式将其插入到表中。具体操作步骤如下:
upsert方法将字节数组插入到表中。如果表中已经存在相同的主键,则更新该行的值;否则插入新行。示例代码如下:
import json
from pymysql import connect, Error
# 连接数据库
conn = connect(host='<your_host>', user='<your_user>', password='<your_password>', database='<your_database>')
cursor = conn.cursor()
# 要插入的数据
data = {
"T1": "value1",
"T2": "value2",
"T3": "value3",
...
}
# 将字典转换为JSON字符串并转换为字节数组
json_data = json.dumps(data).encode('utf-8')
# 使用upsert方法插入数据
sql = "INSERT INTO your_table (id, data) VALUES (%s, %s) ON DUPLICATE KEY UPDATE data=VALUES(data)"
try:
cursor.execute(sql, (<your_primary_key>, json_data))
conn.commit()
except Error as e:
print("Error: {}".format(e))
finally:
cursor.close()
conn.close()
通过这种方式,您可以将每个小时接收到的数据批量插入到表中,从而提高数据插入效率。同时,由于数据量较大,建议在插入数据之前对数据进行清洗和处理,以减少不必要的计算和存储开销。
如果你想要将数据维护到各列中去,你可以使用MaxCompute的流式计算功能。流式计算可以让你实时地处理数据,而不需要等到数据全部到达后才能处理。这样可以提高数据处理的效率和准确性。
以下是一些使用流式计算处理数据的方法:
在MaxCompute中,你可以使用DI(Data Integration)任务来实现数据的更新。DI任务可以将数据从一个地方复制到另一个地方,或者将多个地方的数据合并成一个地方。
对于你的情况,你可以创建一个DI任务,该任务会从你的源数据中读取数据,然后根据设备的ID和小时将数据写入到对应的列中。这样可以保证每个设备在每个小时的运行数据都会被正确地写入到对应的列中。
以下是一个基本的DI任务示例:
CREATE TABLE destination_table (
device_id string,
hour int,
data string
)
COMMENT 'This table is used to store the data';
CREATE DI RECEIVER RECEIVE_DATA(
device_id string,
hour int,
data string
)
COMMENT 'This receiver is used to receive the data';
CREATE DI SENDER SEND_DATA(
device_id string,
hour int,
data string
)
COMMENT 'This sender is used to send the data';
CREATE DI JOB DI_JOB()
COMMENT 'This job is used to process the data';
ADD DI RECEIVER RECEIVE_DATA TO DI JOB;
ADD DI SENDER SEND_DATA TO DI JOB;
RUN DI JOB;
在这个示例中,RECEIVE_DATA接收器会从你的源数据中读取数据,然后将数据发送到SEND_DATA发送器。SEND_DATA发送器会将数据写入到destination_table表中。
根据您提供的信息,您可以考虑使用MaxCompute的数据分区功能来提高数据处理的效率。数据分区可以帮助您将大型表分割成多个小表,从而加快查询速度和降低存储成本。此外,您还可以考虑使用MaxCompute的并行处理能力来提高数据处理的速度。MaxCompute支持并行处理,您可以将查询和数据处理任务分解成多个子任务,并在多个计算节点上并行执行,从而大大提高数据处理的效率。
同步速率慢? 还是在MaxCompute 更新速度慢,整体的SQL太长了。不要超过128k这是机器限制。,此回答整理自钉群“MaxCompute开发者社区2群”
在MaxCompute中,将数据维护到各列中去的高效方式是使用INSERT INTO ... SELECT语句。您可以根据需要选择插入所有列或部分列的数据。以下是一个示例:
odps_interface_table,包含设备ID、小时和运行数据字段。target_table有24个列,分别对应T1、T2...T24。您可以使用以下SQL语句将数据插入到目标表中:
INSERT INTO target_table (T1, T2, T3, ..., T24)
SELECT device_id, hour, run_data1, run_data2, ..., run_data24
FROM odps_interface_table;
如果您只需要插入部分列的数据,可以相应地调整目标表列名和查询结果中的列名。例如,如果您只需要插入T1、T3、T5和T7列的数据,可以使用以下SQL语句:
INSERT INTO target_table (T1, T3, T5, T7)
SELECT device_id, run_data1 AS T1, run_data3 AS T3, run_data5 AS T5, run_data7 AS T7
FROM odps_interface_table;
这样,您就可以根据需要将数据高效地维护到目标表的各个列中。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


