
如何调度DLA Spark 任务DataWorks?
如何调度DLA Spark 任务DataWorks?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
在DataWorks中调度DLA Spark任务可以通过以下步骤实现:
首先,需要在DataWorks中创建一个DLA任务。在DLA任务中,需要设置Spark作业的相关参数,例如主类名、Jar包路径、命令行参数等。具体设置方法可以参考DataWorks官方文档。
在DataWorks中创建一个调度任务。在调度任务中,需要设置DLA任务的调度规则、资源配置、启动参数等。具体设置方法可以参考DataWorks官方文档。
在调度任务中设置Spark作业的提交命令,例如:
angelscript
Copy
spark-submit --master yarn --deploy-mode client --class com.example.MainClass /path/to/your/spark/job.jar --arg1 value1 --arg2 value2
在上述命令中,spark-submit表示提交Spark作业的命令,--master yarn表示使用YARN作为Spark集群管理器,--deploy-mode client表示以客户端模式提交作业,--class com.example.MainClass表示Spark作业的主类名,/path/to/your/spark/job.jar表示Spark作业的Jar包路径,--arg1 value1 --arg2 value2表示Spark作业的命令行参数。2023-08-01 08:02:25赞同 展开评论 -
在DataWorks中调度DLA Spark任务时,需要使用到数据集成(Data Integration)模块和Spark任务。
以下是一种可能的步骤:
创建DLA数据源:在DataWorks项目中,配置DLA数据源信息。确保数据源的连接信息准确,并测试连接成功。
创建Spark任务:在DataWorks的数据开发模块中,创建一个Spark任务。编写Spark代码来实现您的计算逻辑。确保代码中包含与DLA数据源的连接和读取数据的部分。
配置资源引用:在Spark任务的属性中,设置合适的资源引用。根据任务所需的计算资源和内存等配置,选择合适的资源组。
设置依赖关系:如果有其他任务需要在DLA数据源读取完成后再执行,可以设置依赖关系,在任务节点之间定义先后顺序。
调度任务:在DataWorks的工作流模块中,创建一个工作流并将Spark任务添加到工作流中。设置调度规则,如触发时间、频率和触发条件等。
保存并发布工作流:完成任务节点、依赖关系和调度规则的配置后,保存工作流的修改,并发布工作流,使其生效。
通过以上步骤,您可以在DataWorks中调度DLA Spark任务,实现对DLA数据源的计算操作。请注意,具体的操作步骤可能会因DataWorks版本和环境配置而有所不同。
确保在DataWorks中正确配置了DLA数据源和Spark任务的相关信息,并且具备相应的访问权限和资源配额。
如果需要更详细的操作指南或遇到其他问题,请参考阿里云DataWorks文档或联系阿里云技术支持获取进一步的帮助。
阿里云DataWorks文档:https://help.aliyun.com/product/45325.html
2023-07-31 11:53:34赞同 展开评论 -
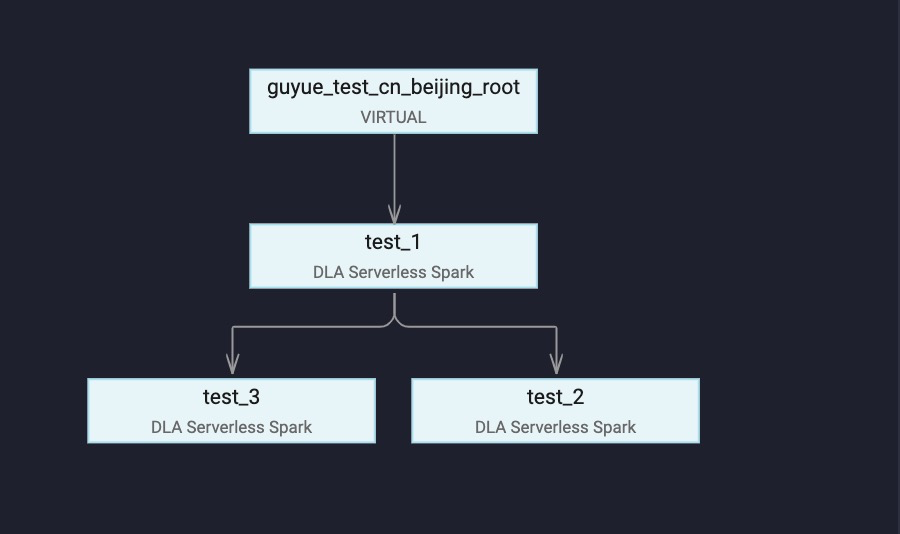
DataWorks是用于工作流可视化开发和托管调度运维的海量数据离线加工分析平台,支持按照时间和依赖关系的任务全面托管调度。任务调度中一个重要的功能是任务之间的依赖,为演示这个功能,本文会在DataWorks中创建三个DLA Spark任务, 任务之间的依赖关系如下图所示,任务test_2和 test_3 依赖上游任务test_1完成之后,才能执行。
前提条件您已经开通DLA、DataWorks以及OSS服务,且DLA、DataWorks、OSS所属Region相同。在本文中三个服务所属Region均为华北2(北京)。创建DataWorks项目空间,详情请参见创建工作空间。说明如果您想用RAM子账号提交Spark作业,且之前未使用过子账号在DLA控制台提交作业,您可以参见细粒度配置RAM子账号权限进行子账号提交作业配置。DataWorks调度DLA Serverless Spark尚未全面开放,开通请联系DLA Spark答疑 钉钉号:dgw-jk1ia6xzp操作步骤在DataWorks中添加OSS数据源。登录DataWorks控制台单击对应项目栏中的进入数据集成,然后单击数据源按钮。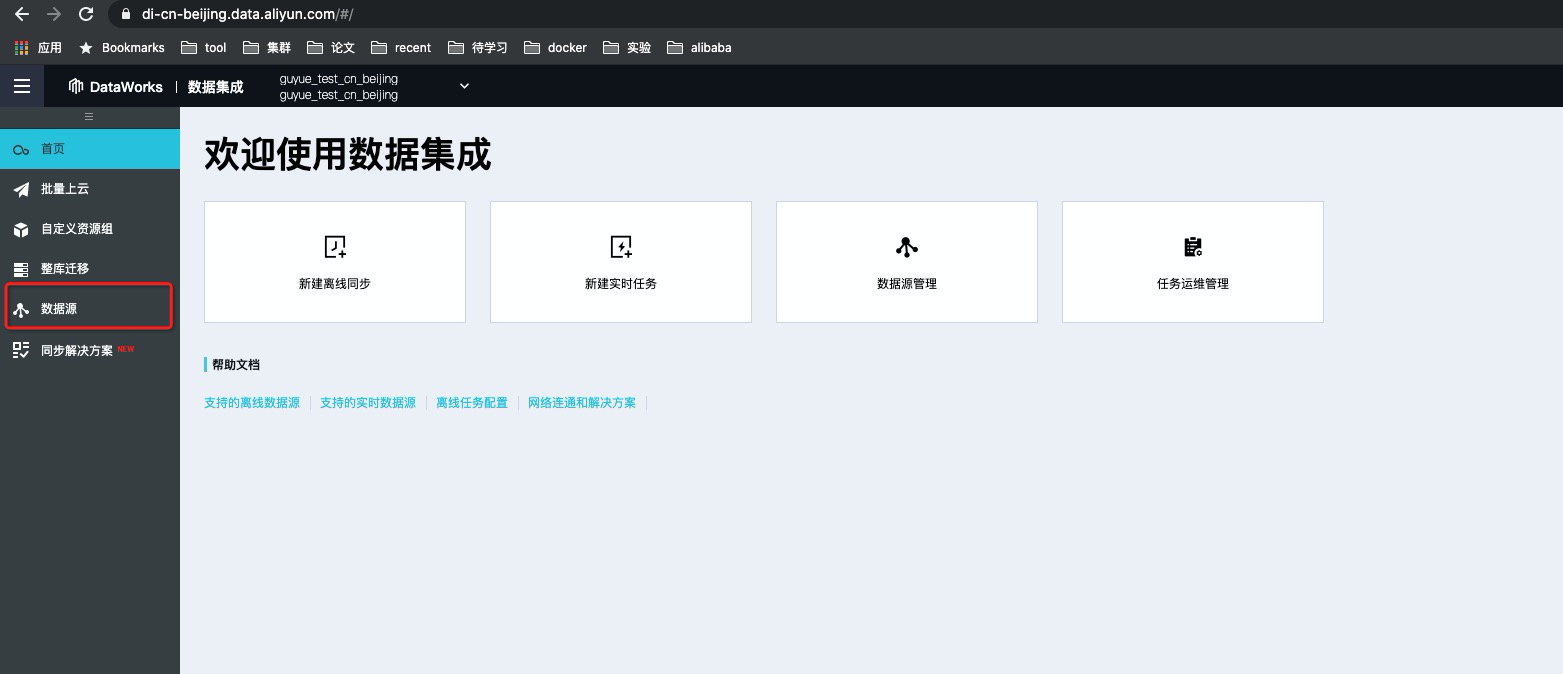
单击页面右上角新增数据源按钮,数据源选择OSS。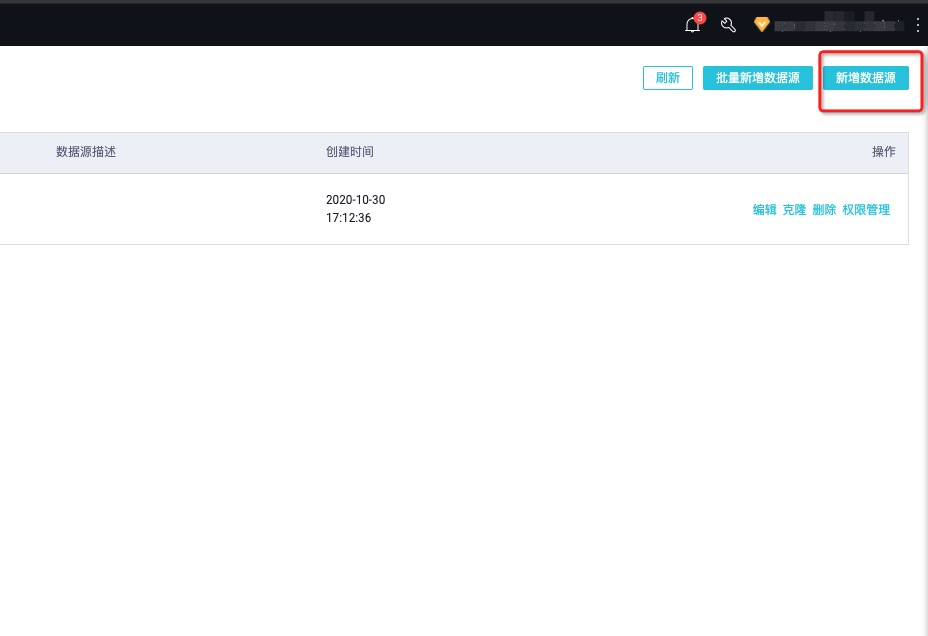
按照页面要求依次填写OSS信息,由于提交Spark作业需要用户的AccessKey ID 和 AccessKey Secret,您可以通过OSS数据源来获取这个信息。 注意不需要测试联通性,填完后单击右下角完成即可。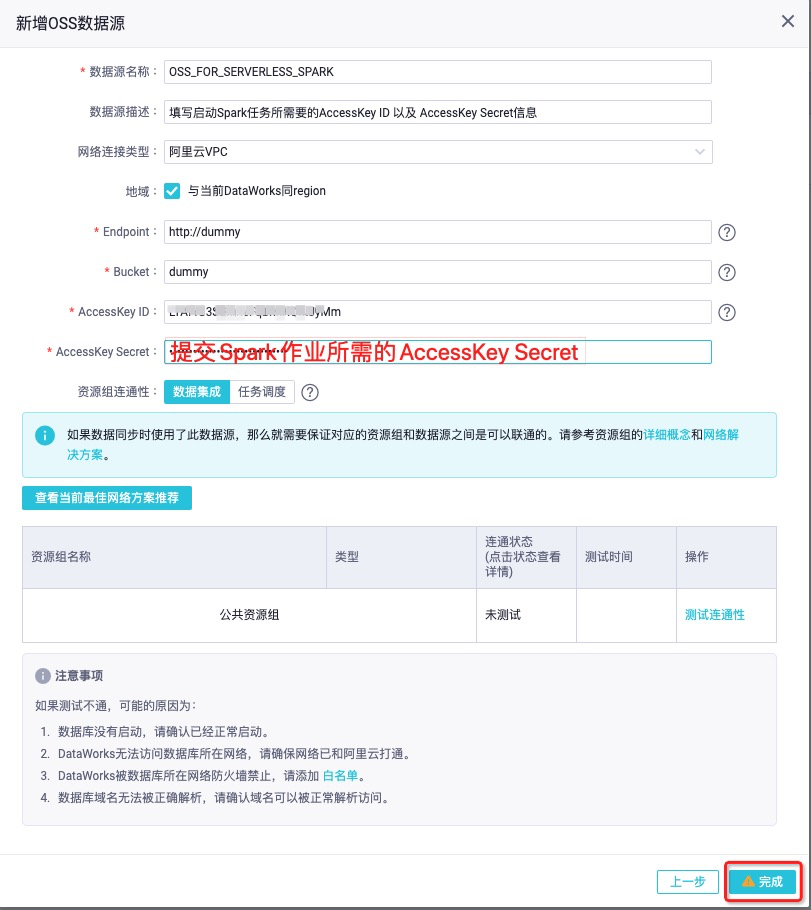
参数配置说明如下:数据源名称 为数据源指定一个名字,便与后续管理。
数
https://help.aliyun.com/document_detail/188048.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-07-31 10:28:09赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。