
DataWorks调度依赖逻辑说明为什么要配置调度依赖?
DataWorks调度依赖逻辑说明为什么要配置调度依赖?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
北京阿里云ACE会长
在DataWorks中,调度依赖是指在进行任务调度时,需要先满足前置任务的执行条件,才能执行当前任务的情况。例如,任务A需要在任务B执行完毕后才能开始执行,此时任务A就依赖于任务B。在DataWorks中,可以通过配置任务依赖关系,实现任务的自动化和定时化。
配置调度依赖的主要目的是为了确保任务的正确性和可靠性,避免因为任务执行顺序不当而导致数据处理的错误或者数据丢失等问题。具体来说,配置调度依赖可以帮助您实现以下目的:
保证任务顺序的正确性:通过配置调度依赖,可以确保任务的执行顺序符合实际需求,避免因为任务执行顺序不当而导致数据处理的错误或者数据丢失等问题。
优化任务执行效率:通过配置调度依赖,可以实现任务的自动化和定时化,避免人工干预和重复执行,提高任务执行效率和数据处理效率。
提高任务可靠性和稳定性:通过配置调度依赖,可以实现任务的自动化和定时化,避免
2023-07-31 13:04:23赞同 展开评论 -
配置调度依赖是为了确保在任务执行时,满足任务之间的依赖关系和特定的调度逻辑。以下是一些原因说明为什么要配置调度依赖:
保证任务顺序:某些任务可能需要按照特定的顺序进行执行,例如数据抽取、清洗、转换、加载等流程。通过配置调度依赖,可以确保在前置任务完成后才能启动后续任务,避免数据处理流程中的错误或异常。
处理依赖关系:在数据处理过程中,不同任务之间可能存在依赖关系,一个任务的输出可能作为另一个任务的输入。通过配置调度依赖,可以指定任务之间的数据依赖关系,并确保在数据可用时触发下游任务的执行。
控制并发度:有时候,任务之间的并发度需要受到控制,以避免资源竞争或系统负载过高。通过配置调度依赖,可以限制任务的并发执行,确保在合适的时间和资源条件下启动任务,以优化整体系统性能。
整合调度策略:通过配置调度依赖,可以将不同类型的任务(周期性调度、手动调度、事件触发等)组合到一个整体的调度策略中。这样可以更好地管理任务的执行逻辑,提高调度的效率和灵活性。
通过配置调度依赖,您可以实现更精确、可控和灵活的任务调度管理。这有助于优化数据处理流程和任务执行效率,并确保任务按照正确的顺序和逻辑进行执行。
2023-07-31 12:04:51赞同 展开评论 -
调度依赖就是节点间的上下游依赖关系,在DataWorks中,上游任务节点运行完成且运行成功,下游任务节点才会开始运行。配置调度依赖后,可以保障调度任务在运行时能取到正确的数据(当前节点依赖的上游节点成功运行后,DataWorks通过节点运行的状态识别到上游表的最新数据已产生,下游节点再去取数)。避免下游节点取数据时,上游表数据还未正常产出,导致下游节点取数出现问题。配置节点的调度依赖时,建议根据各个节点的表数据血缘关系来规划配置节点的上下游依赖,确保满足以下原则:一张表的数据只由一个节点产出,且节点的产出表需配置为本节点的输出。说明SQL任务会通过自动解析,将产出表作为本节点输出,无需手动配置。离线同步任务需要手动配置,将产出表添加为本节点输出。上游节点的输出作为下游节点的输入,形成节点间的依赖关系。说明 对于没有表数据血缘关系的节点,可以根据节点运行的逻辑上下游关系规划配置节点的依赖关系,配置原则和配置后的结果与有血缘关系的节点一致。DataWorks的调度依赖在各个节点的调度配置中进行配置,每个节点需要为其配置依赖的上游节点和本节点的输出。
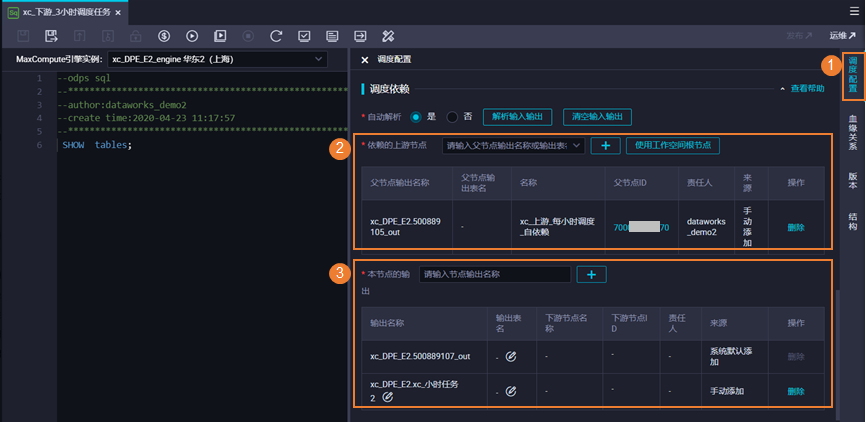
DataWorks支持自动解析和手动配置的方式进行调度依赖配置。理想状态下,DataWorks可根据您规范化的节点任务代码开发,识别输入输出命令(如select、insert),根据代码识别表数据的血缘关系,以血缘关系为基座,通过自动解析自动为您配置好节点的调度依赖。特殊场景下,例如本地上传的表,表数据无需周期性调度生成数据时,您可以手动增删节点的调度配置。在提交节点时,DataWorks会检查节点的调度依赖与节点代码中的数据血缘关系是否一致,如果出现不一致的提示,您需要根据实际情况查看是否需要修改调度依赖配置。
https://help.aliyun.com/document_detail/151507.html,此回答整理自钉群“DataWorks交流群(答疑@机器人)”2023-07-30 17:40:46赞同 展开评论


DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。